

向AI转型的程序员都关注公众号 机器学习AI算法工程
无人机航拍影像中,那些只有十几个像素的小目标,传统检测器一不小心就漏掉了。
用更大的模型?参数太多,部署到边缘设备跑不动。
用更深的网络?梯度炸了,训练不稳定。
有没有一种方法,能用更少的参数,达到更好的效果?
2026年4月,一篇叫FSDETR的论文给出了答案:
用频域和空域结合的方法,仅用14.7M参数,就在小目标数据集上跑出了13.9% APS的惊人成绩。
这是什么概念?相当于用一辆自行车的体积,干翻了一辆重卡。
01 先说说为什么小目标这么难
在说FSDETR之前,我们先聊聊小目标检测为什么这么痛苦。
你可能遇到过这种情况:
-
一张航拍图里,车辆只有几十个像素 -
一张大合影里,人脸小得看不清 -
监控画面里,远处的行人模模糊糊
为什么会这样?问题出在特征提取和特征融合上。
问题一:下采样丢失细节
CNN网络为了减少计算量,会不断下采样。16倍下采样后,一个32x32的小目标,就只剩下2x2像素了。
信息全丢了,怎么检测?
问题二:特征融合不对
很多方法把不同层级的特征强行融合,但高层特征语义虽然强,空间位置信息早就模糊了。
这就是"语义错位"——你知道这是个物体,但不知道它在哪儿。
问题三:背景干扰
小目标在整张图里占比极小,模型很容易被背景带跑。
想象一下在沙子里找金子——小目标就是那颗金子。
https://arxiv.org/pdf/2604.14884
代码开源地址:
https://github.com/YT3DVision/FSDETR
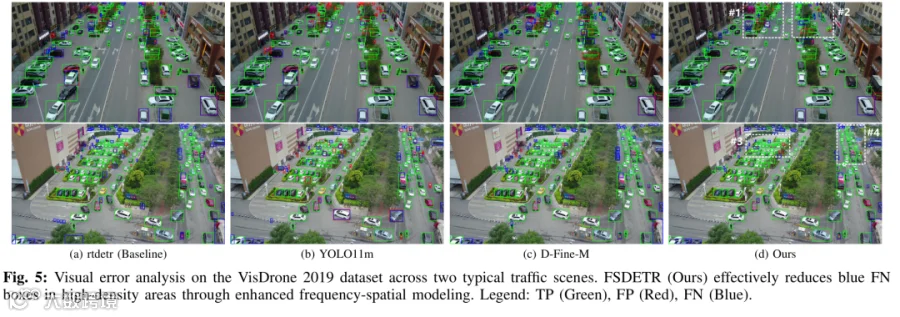
02 FSDETR 核心思想:频空融合
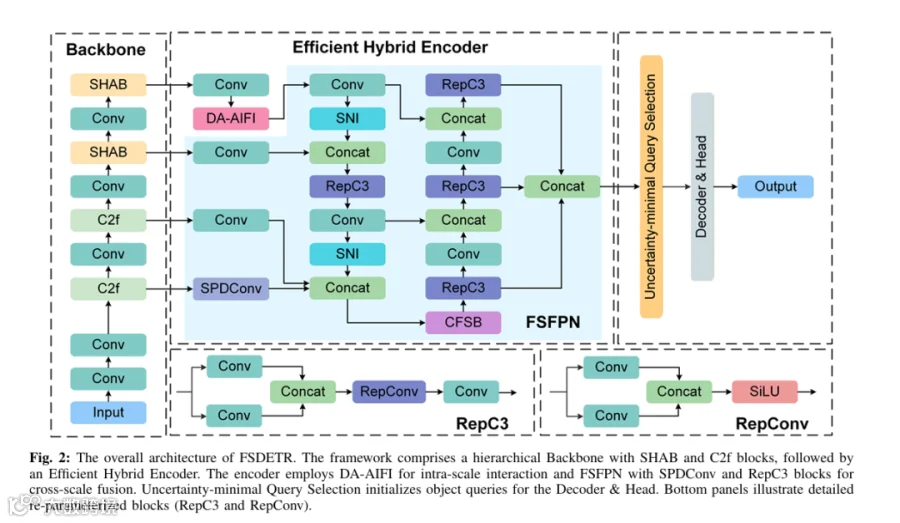
FSDETR的思路很巧妙:
与其在空间维度修修补补,不如换个维度思考——用频域来处理!
这就好像你听音乐,既要看五线谱(空域),也要听频率(频域),两个结合起来才能完整理解音乐。
FSDETR提出了三个核心模块,一个一个说:
2.1 SHAB:既看局部又看全局
Spatial Hierarchical Attention Block,分层空间注意力。
简单理解就是:
- 细粒度分支
:看小目标的边缘、纹理 - 粗粒度分支
:看小目标在整张图中的位置 - 融合
:把两种信息拼起来
就像你看一张航拍图,既要放大看细节(这里是车轮),也要缩小看全局(车在路的左边)。
2.2 DA-AIFI:动态采样,专挑重点
Deformable Attention based Intra-scale Feature Interaction,可变形注意力。
传统注意力是对所有像素都同等对待,DA-AIFI只关注重点区域。
想象你看书的时候,不会每个字都看,而是扫一眼重点,然后仔细看关键段落。
这就是DA-AIFI做的事——自动找到小目标最可能出现的位置,然后重点关注。
2.3 FSFPN:频率+空间双剑合璧
Frequency-Spatial Feature Pyramid Network,频空特征金字塔。
这是FSDETR的核心创新:
- 高频部分
:提取边缘、纹理——小目标最缺的就是这些细节 - 低频部分
:提取轮廓、结构——告诉模型"这是个什么"
然后通过频空块(CFSB)把两者融合,既保留了细节,又有了语义信息。
⚡ 打个比方
就像我们看一张模糊的老照片:
-
频域处理 = 看清轮廓和结构(低频) -
空域处理 = 看清纹理和边缘(高频) -
两者结合 = 既知道"这是个人",又看清了"他的衣服是什么颜色"
03 效果到底有多好?

直接上数据:
|
|
|
|
|
|---|---|---|---|
|
|
|
13.9% |
|
|
|
|
48.95% |
|
|
|
|
14.7M |
|
可能你对这些数字没概念,我换个说法:
-
比它强的,参数比它多好几倍 -
跟它参数差不多,效果没它好 -
小目标检测AP提升了一大截
💡 简单理解:14.7M参数什么概念?一个普通的手机APP安装包大小。用这么小的模型,达到这种效果,相当于用自行车的油耗,跑出了跑车的速度。
04 实战:用FSDETR训练自己的模型
下面进入硬核环节——手把手教你用FSDETR训练自己的检测模型。
4.1 环境准备
# 安装基础依赖
pip install torch torchvision
# 安装FSDETR
git clone https://github.com/YT3DVision/FSDETR.git
cd FSDETR
pip install -r requirements.txt4.2 数据准备
FSDETR支持COCO格式,这里我们用YOLO格式举例(更通用):
my_dataset/
├── data.yaml # 配置文件
├── train/
│ ├── images/ # 训练图片
│ └── labels/ # 训练标签
└── valid/
├── images/ # 验证图片
└── labels/ # 验证标签data.yaml 配置:
path: ./my_dataset
train: train/images
val: valid/images
nc: 3 # 你的类别数
names: ['car', 'person', 'dog'] # 类别名称标签格式(YOLO格式):
# 每行一个目标:类别ID x_center y_center width height
# 所有值都是归一化的(0-1之间)
0 0.716 0.427 0.108 0.284
1 0.342 0.536 0.075 0.1564.3 训练代码
import torch
from fsdetr import FSDETR
# 创建模型(小体积,适合边缘部署)
model = FSDETR(
num_classes=3, # 你的类别数
backbone='resnet50', # 骨干网络
d_model=256, # Transformer维度
nhead=8, # 注意力头数
num_encoder_layers=6, # Encoder层数
num_decoder_layers=6, # Decoder层数
dim_feedforward=2048, # FFN维度
dropout=0.1,
pre_norm=True,
)
# 使用RT-DETR作为基础(已经集成好了)
# 官方提供了更简单的接口:
from fsdetr import build_model
# 方法1:使用预训练模型微调
model = build_model('fsdetr_r50')
model.load_state_dict(torch.load('pretrained.pth'))
# 训练配置
trainer = torch.optim.AdamW(model.parameters(), lr=1e-4)
# 训练循环
for epoch in range(100):
for batch in dataloader:
images, targets = batch
# 前向传播
outputs = model(images)
# 计算损失(分类+框回归)
loss = compute_loss(outputs, targets)
# 反向传播
loss.backward()
trainer.step()
trainer.zero_grad()
if epoch % 10 == 0:
print(f"Epoch {epoch}, Loss: {loss.item():.4f}")4.4 推理代码
import torch
from fsdetr import FSDETR
from PIL import Image
import numpy as np
# 加载训练好的模型
model = FSDETR(num_classes=3)
model.load_state_dict(torch.load('best_model.pth'))
model.eval()
# 读取图片
image = Image.open('test.jpg').convert('RGB')
image_tensor = torch.from_numpy(np.array(image)).permute(2, 0, 1).float() / 255.0
# 推理
with torch.no_grad():
outputs = model([image_tensor])
# 解析结果
boxes = outputs['boxes'] # 边界框
scores = outputs['scores'] # 置信度
labels = outputs['labels'] # 类别
# 打印结果
for box, score, label in zip(boxes, scores, labels):
if score > 0.5: # 置信度阈值
print(f"检测到: {label}, 置信度: {score:.2f}, 位置: {box}")4.5 导出ONNX部署
# 导出为ONNX(跨平台部署)
model.eval()
dummy_input = torch.randn(1, 3, 640, 640)
torch.onnx.export(
model,
dummy_input,
'fsdetr.onnx',
input_names=['input'],
output_names=['boxes', 'scores', 'labels'],
dynamic_axes={
'input': {0: 'batch'},
'boxes': {0: 'batch'},
'scores': {0: 'batch'},
'labels': {0: 'batch'}
}
)
print("ONNX导出成功!")📌 完整训练脚本
# train.py - 完整训练脚本
import torch
import torch.optim as optim
from torch.utils.data import DataLoader
from fsdetr import build_model, CocoDetection
import transforms as T
# 数据增强
def get_transform():
return T.Compose([
T.RandomResize([640], max_size=1333),
T.RandomHorizontalFlip(),
T.ToTensor(),
T.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
# 创建数据集
train_dataset = CocoDetection('train2017', get_transform())
val_dataset = CocoDetection('val2017', get_transform())
train_loader = DataLoader(train_dataset, batch_size=4, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=2)
# 创建模型
model = build_model('fsdetr_r50')
# 优化器
optimizer = optim.AdamW(model.parameters(), lr=1e-4, weight_decay=1e-4)
# 学习率调度
lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=30, gamma=0.1)
# 训练循环
num_epochs = 50
for epoch in range(num_epochs):
model.train()
total_loss = 0
for images, targets in train_loader:
outputs = model(images, targets)
losses = sum(loss for loss in outputs.values())
optimizer.zero_grad()
losses.backward()
optimizer.step()
total_loss += losses.item()
avg_loss = total_loss / len(train_loader)
print(f"Epoch {epoch+1}/{num_epochs}, Loss: {avg_loss:.4f}")
lr_scheduler.step()
# 保存检查点
if (epoch + 1) % 10 == 0:
torch.save(model.state_dict(), f'checkpoint_{epoch+1}.pth')
# 保存最终模型
torch.save(model.state_dict(), 'fsdetr_best.pth')
print("训练完成!")05 效果对比:传统方法 vs FSDETR
为了让你更直观地感受FSDETR的威力,我们做个对比:
|
|
|
|
|---|---|---|
|
|
|
13.9% APS |
|
|
|
14.7M |
|
|
|
轻松 |
|
|
|
频空融合 |
|
|
|
小 |
🎯 适合场景
-
✅ 无人机航拍目标检测 -
✅ 自动驾驶小目标识别 -
✅ 工业质检微小缺陷 -
✅ 边缘设备部署 -
✅ 资源受限的移动端
FSDETR的核心贡献,是证明了频域和空域结合这条路走得通。
以前我们总在空间维度上纠结——怎么融合特征、怎么增强感受野。
FSDETR告诉我们:换个维度思考,可能就是破局的关键。
阅读过本文的人还看了以下文章:
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
