

向量检索与 pgvector:数据库里的 AI 能力
随着大语言模型和多模态 AI 普及,向量检索已成为基础设施级能力,广泛应用于语义搜索、图像检索、推荐系统和 RAG 等场景。其核心在于将非结构化数据编码为高维向量,并实现海量数据的高效相似性匹配。
作为 PostgreSQL 的扩展,pgvector 通过 Access Method 接口实现了 IVF-FLAT 和 HNSW 向量索引,使社区版 PostgreSQL 原生支持向量存储与搜索。阿里云 RDS PostgreSQL 版在此基础上持续优化生产场景下的性能、稳定性和可扩展性,其中 RaBitQ 量化技术显著提升了大规模向量场景的处理效率。
pgvector 面临的挑战
当数据量超过百万级进入千万级甚至亿级规模时,pgvector 的性能瓶颈凸显:
- 存储效率不足:高维向量占用大量空间(例如 1024 维 float32 向量需 4096 字节),固定 8KB 页面在内存受限时频繁触发 IO,导致查询性能急剧下降。
- 查询延迟长尾效应:索引规模扩大使 P99 延迟劣化显著,高并发场景下 CPU 浮点计算压力成为瓶颈。
- 向量插入性能劣化:索引创建依赖 maintenance_work_mem 参数,内存超限时退化为磁盘操作,频繁 IO 恶化性能。
问题根源在于传统索引需完整存储浮点向量。距离计算要求读取所有维度数据并执行 O(d) 次浮点运算,规模增长时计算量和内存消耗巨大。下表展示了不同数据集的空间占用:
| 数据集 | 数据规模 | 索引空间 |
| GIST1M | 128D1M | 654MB |
| SIFT1M | 960D1M | 4887MB |
| dbpedia-openai-1M | 1536D1M | 7918MB |
| 业务数据集 | 1024D100M | 689GB |
向量量化通过压缩表示在可接受精度损失下提升存储效率,是解决该问题的有效路径。
向量量化与 RaBitQ
什么是向量量化
向量量化用紧凑编码表示高维向量。例如,768 维 float32 向量需 3072 字节,经量化可大幅压缩至 8 位整数、二值比特或码本索引级别。查询时通过查表或解析公式近似计算距离,精度损失可控。
pgvector 社区已实现半精度向量(float16)和二值量化,但前者压缩比有限,后者召回率显著降低。RaBitQ 在框架层面支持多种量化方式,平衡了压缩比与精度。
为什么选择 RaBitQ
RaBitQ(Random Binary Quantization)基于二值化量化,具有三大优势:
- 32 倍压缩比:1 比特表示单维度。
- 距离运算高效:转化为位运算结合 SIMD 并行处理。
- 理论误差保障:提供可证明的误差范围,通过初筛与重排序确保召回率。
RaBitQ 在 pgvector 中的工作原理
RaBitQ 的核心原理
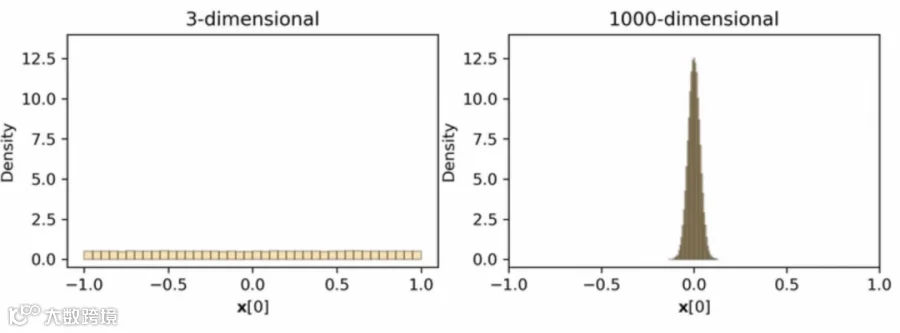
RaBitQ 利用高维空间几何特性:单位球面上随机向量在各维度呈零点集中分布。处理流程包含三步:
- 将向量投影到单位球面。
- 通过随机旋转变换均匀分散信息至各维度。
- 二值量化方向替代具体数值,实现 32:1 压缩。
距离计算时,原始内积/欧氏距离被拆解为可预计算分量和核心项。核心项通过 SQ4 量化转化为位运算与 POPCOUNT 快速求解,结合理论误差界实现初筛与重排序,兼顾效率与精度。
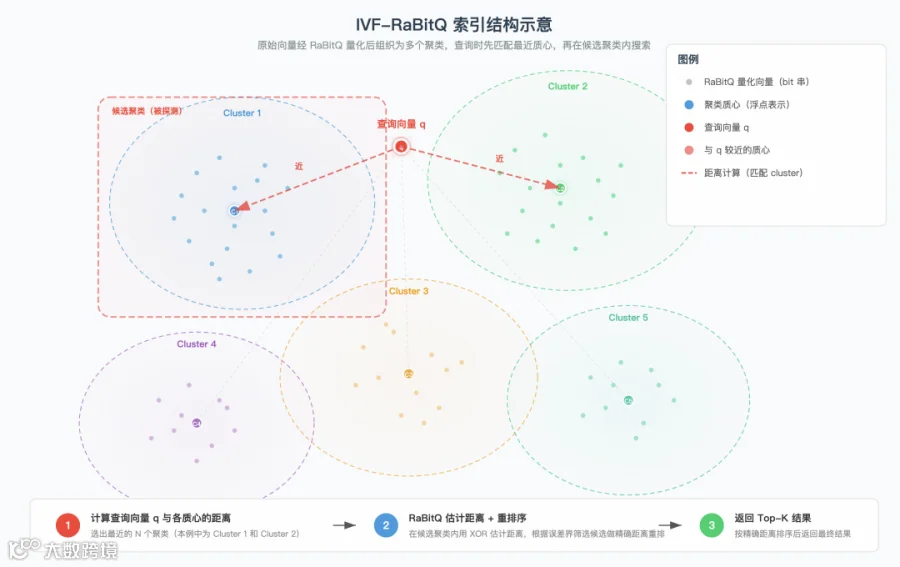
pgvector上的 IVF-RaBitQ
IVF-RaBitQ 结合 K-Means 聚类与量化技术:
索引构建:
- K-Means 划分向量空间生成聚类中心(保留原始精度)。
- 初始化 RaBitQ 旋转变换信息。
- 以聚类中心为质心对内部向量执行量化。
向量搜索:
- 匹配查询向量至最近聚类。
- 对查询向量 SQ4 量化,通过 RaBitQ 索引计算估计距离。
- 按误差界对候选向量精确重排序。
pgvector 索引上的 HNSW-RaBitQ
HNSW-RaBitQ 针对分层图索引优化:
- 图结构构建基于原始向量,避免量化偏差。
- 搜索阶段:上层初筛用 RaBitQ 估计距离快速定位;Level 0 搜索结合误差界筛选候选集,精确计算关键向量。
性能测试:压缩率、延迟与召回率
测试环境
- RDS PostgreSQL 17(20260330 版本)
- 实例规格:pg.x2.12xlarge.2c
- pgvector 版本:0.8.0.2
- 数据集:dbpedia-openai-1M、1024 维 100M 业务数据
测试结果
dbpedia-openai-1M 数据集:
| 索引类型 | 索引参数 | 创建时间 | 索引空间 |
| IVF-FLAT | nlists=1000 | 95.32s | 7820MB |
| IVF-RaBitQ | nlists=1000 | 78.72s | 248MB |
| HNSW | m=16, ef_construction=64 | 281.42s | 7918MB |
| HNSW-RaBitQ | m=16, ef_construction=64 | 251.97s | 510MB |
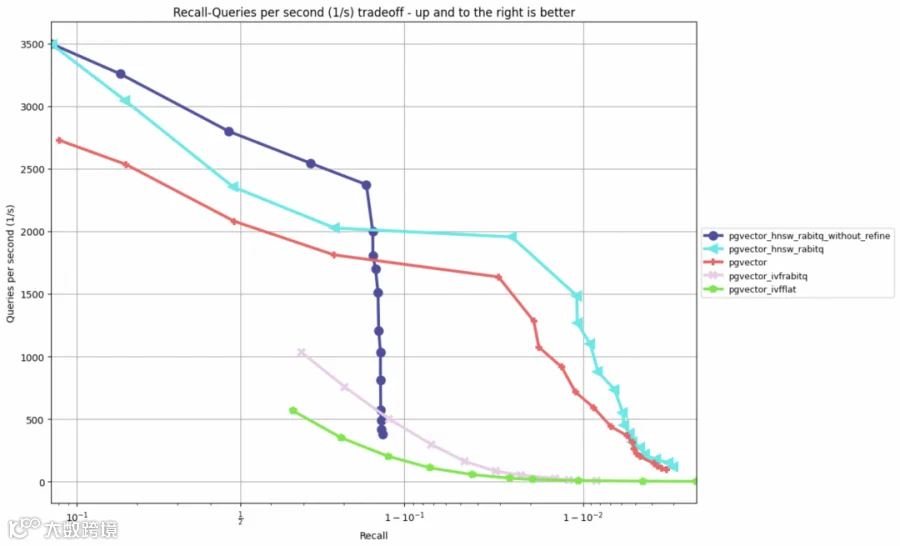
同等召回率下,RaBitQ 量化使查询性能提升 2-5 倍,索引空间压缩 32 倍。
1024 维 100M 业务数据集:
| IVF-RaBitQ | HNSW | ||
| 索引参数 | lists=10000 | m=16, ef_construction=64 | |
| 索引创建时间 | 4h23min17s | 4d1h13min47s | |
| 索引空间 | 16GB | 689GB | |
| write-only avg-latency | 6.41ms | 469.41ms | |
| read-only top100 avg-latency | 359.194ms | 1789.22ms | |
| read-write write avg-latency | 13.42ms | 473.54ms | |
| read-write read avg-latency | 395.93ms | 1704.64ms |
测试小结
- 内存充足场景:RaBitQ 量化实现 32 倍空间压缩,查询性能显著提升。
- 亿级规模场景:IVF-RaBitQ 在索引创建、写入及大结果集查询上优势突出,尤其适用于内存受限的高并发生产环境。
快速上手:用 SQL 体验 RaBitQ 量化检索
环境准备
-- 检查 pgvector 版本
SELECT extversion FROM pg_extension WHERE extname = 'vector';
-- 确保 vector 扩展已启用
CREATE EXTENSION IF NOT EXISTS vector;创建表并插入数据
-- 创建向量表
CREATE TABLE items (
id bigserial PRIMARY KEY,
embedding vector(768)
);
-- 插入示例数据
INSERT INTO items (embedding)
SELECT array_agg(random())::vector(768)
FROM generate_series(1, 100000);创建 RaBitQ 量化的 IVF-FLAT 索引
-- lists 参数通常设为数据量的平方根
CREATE INDEX ON items
USING ivfflat (embedding rabitq_vector_cosine_ops)
WITH (lists = 100);创建 RaBitQ 量化的 HNSW 索引
CREATE INDEX ON items
USING hnsw (embedding rabitq_vector_cosine_ops)
WITH (m = 16, ef_construction = 64);执行量化搜索查询
-- 设置搜索参数
SET ivfflat.probes = 10;
-- SET hnsw.ef_search = 64;
-- 执行相似度搜索
SELECT id, embedding <=> '[0.1, 0.2, ...]' AS distance
FROM items
ORDER BY embedding <=> '[0.1, 0.2, ...]'
LIMIT 10;结语
RaBitQ 量化显著提升了阿里云 RDS PostgreSQL 上 pgvector 的向量检索效率,使大规模向量场景下的存储成本降低 32 倍,查询性能提高数倍。用户无需引入额外向量数据库或复杂运维,仅需调整索引参数即可获得优化效果,为生产环境提供了高效可靠的向量检索解决方案。