

随着大模型推理部署进入规模化落地阶段,高显存、高带宽、高并发成为专业级显卡的核心考核指标。本次我们针对NVIDIA RTX PRO 5000 Blackwell 48G专业显卡(以下简称:PRO 5000 48G),完成覆盖基础算力、多卡互联、大模型推理的全链路实测,用真实数据验证其在企业级AI服务、私有化部署场景的真实战力。
|
NVIDIA RTX PRO 5000 Blackwell核心参数 |
|
|
显存大小 |
48GB/72GB |
|
架构 |
Blackwell |
|
FP32 (TFLOPS) |
65 |
|
FP16 (TFLOPS) |
516 |
|
FP8 (TFLOPS) |
1032 |
|
FP4 (TFLOPS) |
2064 |
|
INT8 (TOPS) |
1032 |
|
INT4 (TOPS) |
2064 |
|
显存规格 |
GDDR7 |
|
显存位宽 |
512 bit |
|
显存带宽 |
1344 GB/s |
|
CUDA / RT Cores |
14080 / 196 TFLOPS |
|
TDP |
300W |
注:以下数据均由宽恒科技前沿技术研究院实测得出结果仅供参考最终落地的实际性能稍有差异
测试平台配置
本次测试基于标准企业级部署环境,软件栈与大模型生产环境对齐,确保结果可直接用于落地参考。
|
硬件核心配置 |
|
|
GPU |
PRO 5000 48G * 4 |
|
CPU |
AMD EPYC 9654 96-Core Processor * 2 |
|
内存 |
64G * 16 |
|
PCIE |
PCI-E 5.0 |
|
测试环境(软件) |
|
|
系统 |
Ubuntu 22.04.5 LTS |
|
GPU 驱动版本 |
580.119.02 |
|
CUDA版本 |
13.0.88 |
|
Python |
Python 3.12.12 |
|
Torch |
2.9.0+cu130 |
|
vllm |
0.13.0+cu130 |
02
测试项目说明
本次测试围绕AI 大模型训练与推理核心场景,针对性验证 4 项关键性能。
|
测试项目 |
|
|
GPU显存 带宽测试 |
评估主机与显卡、显卡内部数据传输效率 |
|
GPU卡间 带宽测试 |
验证多卡 P2P 互联、并行计算通信能力 |
|
NCCL集群 通信测试 |
分布式训练核心通信性能基准 |
|
LLM推理 性能测试 |
32B/70B 级大模型实际部署能力 |
03
核心测试结果
1. GPU显存带宽(GB/s)
|
方式 |
主机→设备 |
设备→主机 |
设备→设备 |
|
显卡平分 |
57.4 |
57.3 |
4345.5 |
|
显卡同侧 |
57.4 |
56.4 |
4397.0 |
显存带宽表现拉满,完全满足大规模数据吞吐与高速计算需求。
2. GPU卡间带宽(GB/s)
|
方式 |
Bidirectional P2P |
|
|
显卡平分 |
禁用 |
启用 |
|
43.23 |
52.32 |
|
|
显卡同侧 |
禁用 |
启用 |
|
42.45 |
102.73 |
|
P2P 禁用:约43GB/s
P2P 启用:最高102.93GB/s
开启P2P后多卡协同效率接近翻倍,适配并行训练、多卡推理场景。
3. NCCL 测试(4卡对比 GB/s)
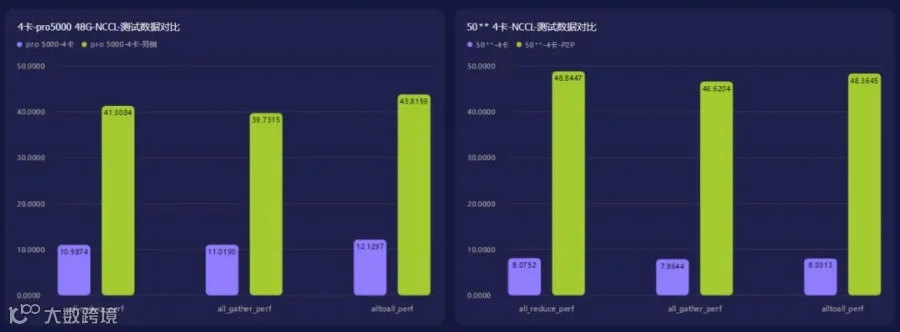
|
PRO 5000 48G |
||
|
测试项 |
显卡平分 |
显卡同侧 |
|
all_reduce_perf 4卡 |
10.9874 |
41.3084 |
|
all_gather_perf 4卡 |
11.019 |
39.7315 |
|
alltoall_perf 4 卡 |
12.1297 |
43.8159 |
|
RTX 50** |
||
|
测试项 |
显卡平分 |
显卡同侧 |
|
all_reduce_perf 4卡 |
8.0752 |
48.8447 |
|
all_gather_perf 4卡 |
7.8644 |
46.6204 |
|
alltoall_perf 4 卡 |
8.0313 |
48.3645 |
PRO 5000 48G多卡部署接近RTX 50** 90%的性能,分布式训练通信瓶颈大幅缓解。
04
LLM 大模型推理实测
本次测试采用行业主流大模型,严格按照首 Token 延迟<5s、单用户>10 tokens/s的生产标准压测,验证真实服务能力。
测试模型与规则
模型 1:QwQ-32B(FP16,32k 上下文,TP=4)
模型 2:Llama3-70B(FP16,32k 上下文,TP=8)
输入输出长度:512/512、1024/1024
核心指标:首Token延迟、单用户吞吐、最大稳定并发、Decode 吞吐、总吞吐
测试结果:
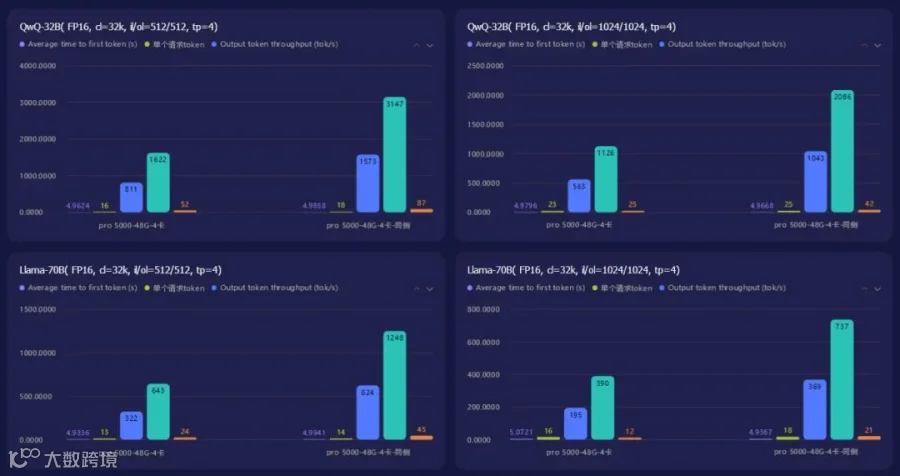
|
QwQ-32B |
||||
|
测试项 |
il/ol=512/512 |
il/ol=1024/1024 |
||
|
显卡平分 |
显卡同侧 |
显卡平分 |
显卡同侧 |
|
|
首token延迟(s) |
4.9624 |
4.9858 |
4.9796 |
4.9668 |
|
单个请求token |
16 |
18 |
23 |
25 |
|
Output token throughput(tok/s) |
811 |
1573 |
563 |
1043 |
|
Total token throughput(tok/s) |
1622 |
3147 |
1126 |
2086 |
|
并发数量 |
52 |
87 |
25 |
42 |
|
Llama3-70B |
||||
|
测试项 |
il/ol=512/512 |
il/ol=1024/1024 |
||
|
显卡平分 |
显卡同侧 |
显卡平分 |
显卡同侧 |
|
|
首token延迟(s) |
4.9336 |
4.9941 |
5.0721 |
4.9367 |
|
单个请求token |
13 |
14 |
16 |
18 |
|
Output token throughput(tok/s) |
322 |
624 |
195 |
369 |
|
Total token throughput(tok/s) |
643 |
1248 |
390 |
737 |
|
并发数量 |
24 |
45 |
12 |
21 |
QwQ-32B:输出吞吐最高3147tok/s,首 token 延迟<5s
Llama3-70B:输出吞吐最高1248tok/s,首 token 延迟<5s
双模型均达标,可稳定支撑高并发大模型实时服务。
05
本次测试结论
PRO 5000 48G是大模型部署性价比之选
综上,在预算有限、并发请求量不高的场景下,对于100B参数以内的大模型推理部署,PRO 5000 48G配置已足够满足需求。而且推理场景下,实测性能达90%同为Blackwell架构的某前辈卡。
况且PRO 5000是原生48G显存,在数据中心机房工况中长时间运行更为稳定。同时在功耗控制上表现更优,整体推理性价比突出,是兼顾成本与性能的务实选择。

下期我们将发布NVIDIA RTX PRO 5000 Blackwell 72G的测评报告,敬请期待!
ps:如果不清楚具体部署方式,或想达到最优部署,欢迎添加添加宽恒售前客服,提供您的需求,我们将竭诚为您服务。

扫码添加宽恒售前客服


