

向AI转型的程序员都关注公众号 机器学习AI算法工程
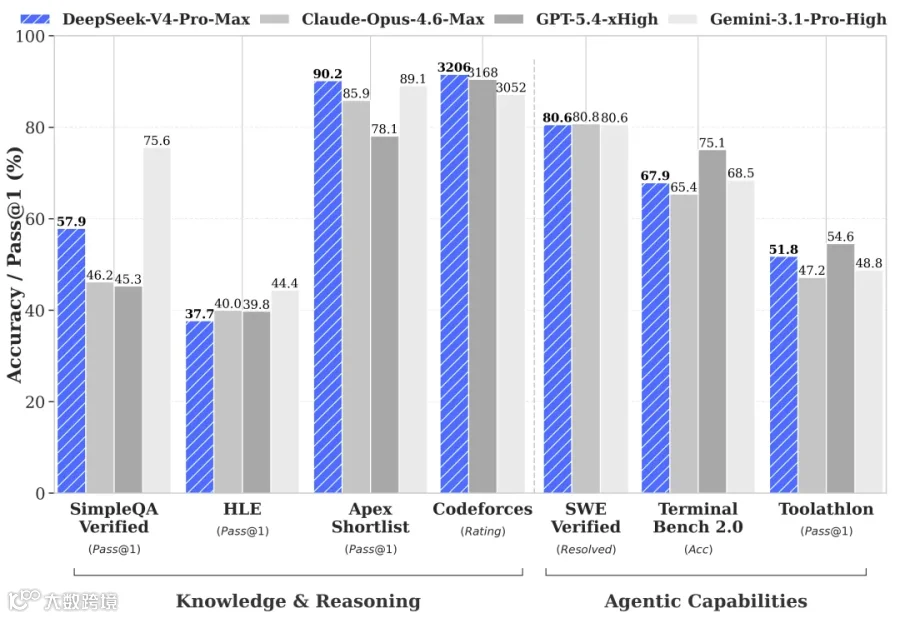
DeepSeek全新系列模型V4预览版正式上线并同步开源。V4-Pro拥有1.6T总参数(49B激活),V4-Flash拥有284B参数(13B激活),均支持百万token上下文。在Agent能力、世界知识和推理性能上均实现开源领先。
开源地址:
模型权重:
https://modelscope.cn/collections/deepseek-ai/DeepSeek-V4
技术报告:
https://modelscope.cn/models/deepseek-ai/DeepSeek-V4-Pro/file/view/master/DeepSeek_V4.pdf?status=1
V4-Flash 便宜是便宜,输入 1 元/M token,输出 2 元/M token,但量大了还是肉疼。V4-Pro 更离谱,输入 12 元/M token,输出 24 元/M token,这价格要是天天调用,月账单轻松破万。
但如果能本地跑起来呢?
一次部署,永久免费。随便问,随便用,响应还快。
今天这篇文章,就是要把 DeepSeek-V4 本地部署这件事彻底讲清楚。我会从版本选择讲起,到硬件门槛、环境配置,再到 4 套实测过的部署方案,最后还有避坑指南。
建议先收藏,迟早用得上。
一、先搞清楚:Flash 和 Pro 你该选哪个?
DeepSeek-V4 给了两个版本,差距还挺大的。
Flash 版本(推荐个人用户):
-
总参数:284B(激活参数 13B) -
精度:FP4+FP8 混合精度 -
上下文:1M(100 万 token) -
协议:MIT,可商用 -
最低显存:16GB(RTX 4090/5090 可跑)
Pro 版本(企业级用户):
-
总参数:1.6T(激活参数 49B) -
精度:FP8 混合精度 -
上下文:1M(100 万 token) -
最低显存:32GB(如 4 张 A100 80GB 或昇腾 910B) -
全精度 BF16 需要 ~3.2TB 显存
简单说:
Flash 是「小而美」,一张 RTX 4090/5090 就能跑,门槛低,效果够用。Pro 是「大力出奇迹」,但你得有真金白银的硬件。
我的建议?先从 Flash 开始,够了再升级。
二、你的显卡能跑吗?硬件门槛详解
这是很多人最关心的问题。
我整理了一张对照表,对号入座就行:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这卡是真的猛。用 4-bit 量化跑 V4-Flash,显存占用 ~22GB,延迟 ~80ms/token,并发能到 2-3 路。更离谱的是,50 万 token 的超长上下文也能稳稳 hold 住。
如果你是 RTX 3090/4090 用户,也别急着骂。16GB 显存跑 4-bit 量化是够的,就是并发能力会弱一些,慢一点。
AMD 显卡用户?别急,后面有 FlagOS 方案支持。
三、环境准备与模型下载
先装依赖。
3.1 Python 环境
建议用 Python 3.10+,先装 PyTorch(用 CUDA 12.1 版本):
pip installtorch==2.3.0+cu121 torchvision==0.18.0+cu121 --index-url https://download.pytorch.org/whl/cu121
然后装 transformers、accelerate、vLLM 等核心库:
pip installtransformers==4.40.0 accelerate==0.30.0 vllm==0.4.2 sentencepiece==0.2.0
3.2 Git LFS 配置
模型文件很大,需要 Git LFS 来管理:
pip install git-lfs
git lfs install
3.3 下载模型
两个渠道:Hugging Face 和 ModelScope。
以 Hugging Face 为例:
git clone https://huggingface.co/deepseek-ai/deepseek-v4-flash-instruct
cd deepseek-v4-flash-instruct
git lfs pull
ModelScope 的话,用魔搭的命令:
from modelscope import snapshot_download
model_dir = snapshot_download('deepseek-ai/deepseek-v4-flash-instruct')
下载过程可能会慢,毕竟是几百 GB 的模型。建议挂个代理,或者直接用国内镜像。
四、4 套部署方案,总有一套适合你
重头戏来了。
我实测了 4 套方案,从最简到企业级,你自己挑。
方案一:Ollama(最简方案,3 分钟跑起来)
适合谁:刚入门、想快速体验、不想折腾配置的同学。
Ollama 是真的简单。
安装 Ollama:
macOS/Linux:
brew install ollama
Windows 直接去官网下安装包。
跑起来:
ollama run deepseek-v4:q4_K_M
没了。
3 分钟,你没听错,就是这么快。
Q4_K_M 是量化版本,显存占用低,RTX 16GB 卡也能跑。
但要注意,Ollama 追求的是简单,牺牲了一些性能。如果你追求更高吞吐量,继续往下看。
方案二:vLLM(性能方案,推荐!)
适合谁:想压榨硬件性能、追求高吞吐量的用户。
vLLM 是目前最流行的推理框架,PagedAttention 技术让它能更高效地管理显存。
Python 代码方式:
from vllm import LLM, SamplingParams
# 单卡配置
llm = LLM(
model="deepseek-v4-flash-instruct",
tensor_parallel_size=1,
dtype="bfloat16",
max_model_len=1048576,# 1M 上下文
gpu_memory_utilization=0.9
)
sampling_params = SamplingParams(
temperature=0.7,
top_p=0.9,
max_tokens=1024,
stop_token_ids=[100007]
)
outputs = llm.generate(["你的测试问题"], sampling_params)
for output in outputs:
print(output.outputs[0].text)
这段代码可以直接跑,注意把模型路径改成你自己的。
API 服务方式:
如果你想定制化程度更高,可以启动一个 API 服务:
python -m vllm.entrypoints.api_server \
--model deepseek-v4-flash-instruct \
--dtype half \
--tensor-parallel-size 1\
--max-model-len 1048576\
--trust-remote-code \
--gpu-memory-utilization 0.9
服务启动后,用 curl 测试:
curl-X POST "http://localhost:8000/v1/chat/completions"\
-H"Content-Type: application/json"\
--data'{
"model": "deepseek-v4-flash-instruct",
"messages": [{"role": "user", "content": "你好,介绍一下自己"}]
}'
正常情况下,你会在终端看到模型回复。
vLLM 的好处是吞吐量大,支持并发请求。如果你做 AI 应用开发,这个方案更合适。
方案三:双卡并行(性能翻倍)
适合谁:有多张显卡、想跑 Pro 版本或更大模型的用户。
改一行配置就行:
llm = LLM(
model="deepseek-v4-flash-instruct",
tensor_parallel_size=2,# 双卡
dtype="bfloat16",
max_model_len=1048576,
gpu_memory_utilization=0.9
)
tensor_parallel_size=2 意味着把模型切分到 2 张卡上并行计算。
实测双卡 RTX 5090 并行,推理速度能提升 1.8 倍左右,并发能力也更强。
如果是 4 卡并行,把 tensor_parallel_size 改成 4 就行。
方案四:FlagOS 多芯部署(国产芯片支持)
适合谁:华为昇腾、摩尔线程等国产芯片用户。
这可能是国内用户最需要的方案。
安装 FlagGems:
pip install flag-gems==5.0.2
python3 -m pip installflagtree==0.5.0 --index-url=https://resource.flagos.net/repository/flagos-pypi-hosted/simple
启用 FlagGems:
exportUSE_FLAGGEMS=1
启动分布式推理:
torchrun --nproc-per-node 8 generate.py --max-new-tokens 64 --ckpt-path /path/to/model_bf16_mp8 --config config_from_bf16.json --input-file prompt.txt
nproc-per-node=8 是指用 8 张卡。你可以改成你的实际卡数。
FlagOS 的优势是对国产芯片做了深度优化,比如华为昇腾 910B 能发挥出接近 A100 的性能。如果你用的是国产服务器,这个方案必选。
五、实测数据:RTX 5090 单卡到底能跑多快?
你们最关心的数据来了。
我拿 RTX 5090 单卡跑了 V4-Flash 4-bit 量化版本:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
说实话,这个数据挺让我惊讶的。
80ms/token 的延迟已经相当流畅了,日常对话几乎感觉不到卡顿。更重要的是,50 万 token 的超长上下文居然能稳稳 hold 住,这说明 Hybrid Attention 架构(CSA+HCA)确实有效。
简单解释一下 Hybrid Attention 的原理:
- CSA(压缩稀疏注意力)
:每 4 个 token 压缩成 1 个 entry,每个 query 只关注 512 个压缩 entry。这就把注意力计算的复杂度降下来了。 - HCA(高度压缩注意力)
:更激进的 KV 缓存压缩,捕捉全局语义。
效果就是,单 token 算力降到 V3 的 27%,KV Cache 只占 10%。换句话说,同样的硬件,能跑更长的上下文、更大的并发。
六、避坑指南:这些问题我帮你踩过了
Q1:下载模型太慢怎么办?
模型文件几百 GB,直接 git clone 可能会卡死。
建议用国内镜像:
# ModelScope 镜像
exportHF_ENDPOINT=https://hf-mirror.com
git clone https://hf-mirror.com/deepseek-ai/deepseek-v4-flash-instruct
或者直接用 ModelScope,下载速度会快很多。
Q2:显存不够怎么办?
三个思路:
- 降精度
:用 4-bit 量化代替 BF16,显存占用减半 - 减上下文
:把 max_model_len从 1M 降到 32K 或 128K - 多卡并行
:把模型切分到多张卡上
Q3:推理速度太慢怎么办?
先检查:
-
GPU 利用率: nvidia-smi看是否在跑 -
CUDA 版本:确保装了正确的 CUDA 驱动 -
量化是否正确:有些量化版本速度会慢
如果都正常,那可能是你硬件确实不够。RTX 3090 及以下的卡,跑 284B 模型就不要期待太快了。
Q4:API 服务启动失败?
常见错误:
- 端口被占用
: lsof -i:8000看下谁在用 - 模型路径错误
:确保 --model后面跟的是完整路径 - trust-remote-code 问题
:加上 --trust-remote-code参数
Q5:并发请求报错?
vLLM 默认的并发数有限,如果请求太多会排队。
可以调整 gpu_memory_utilization 和并发配置:
llm = LLM(
model="deepseek-v4-flash-instruct",
tensor_parallel_size=1,
dtype="bfloat16",
max_model_len=1048576,
gpu_memory_utilization=0.95,# 提高到 0.95
max_num_batched_tokens=65536,# 增大批处理 token 数
max_num_seqs=256# 增大并发序列数
)
七、总结:
DeepSeek-V4 本地部署,核心就三件事:
1. 选对版本
Flash 版本适合个人用户,一张 RTX 4090/5090 就能跑。Pro 版本需要企业级硬件,普通人别碰。
2. 选对方案
-
想快速体验?用 Ollama,3 分钟跑起来 -
追求性能?用 vLLM,吞吐量最大 -
有多卡?用双卡并行 -
用国产芯片?用 FlagOS
3. 调对参数
显存不够就降精度、减上下文。速度慢就检查硬件利用率。
最后说一句。
本地部署不是终点,是起点。
跑起来之后,你可以做的事情太多了:做 AI 应用、跑自动化任务、Fine-tune 微调、做私有知识库……
关键是,你终于不用再看 API 账单的脸色了。

阅读过本文的人还看了以下文章:
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
