
DeepSeek V4技术解析:开源模型性能突破与现状
DeepSeek V4以Codeforces Rating 3206分位列人类选手第23名,LiveCodeBench Pass@1达93.5%位居全球第一。其SimpleQA-Verified测试得分57.9%,领先Claude Opus 4.6 Max 11.7个百分点,刷新开源模型纪录。
Nevertheless, its performance falls marginally short of GPT-5.4 and Gemini-3.1-Pro, suggesting a developmental trajectory that trails state-of-the-art frontier models by approximately 3 to 6 months.
技术报告坦言:"相比最前沿闭源模型仍落后3至6个月。"

作为当前最强开源模型,V4-Pro-Max在384K上下文与无限思考预算下表现突出:
- Codeforces人类排名前23(基于114道题目14场模拟测试)
- LiveCodeBench v6 Pass@1 93.5%(Gemini-3.1-Pro为91.7%)
- Putnam-2025数学竞赛题集获120满分
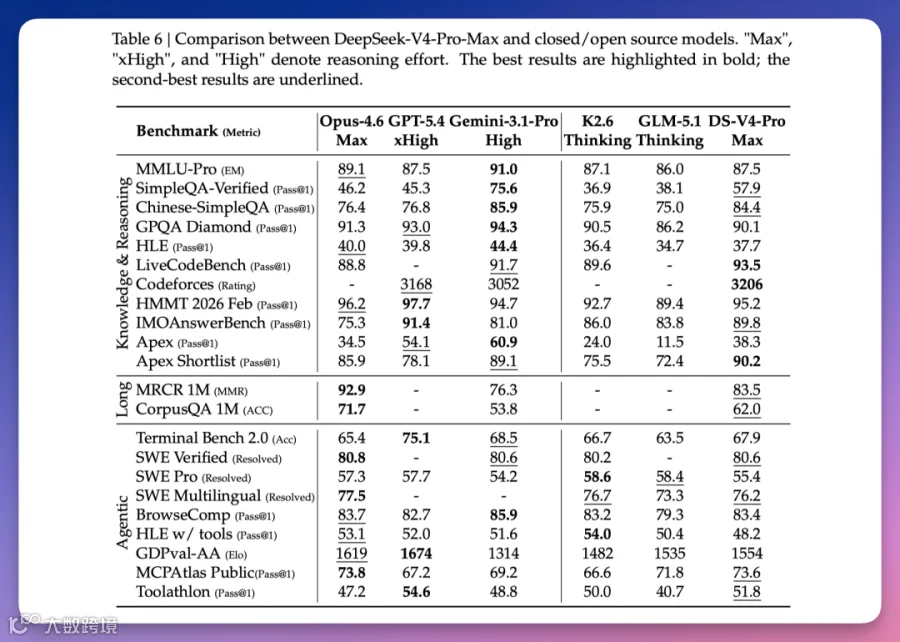
在SimpleQA-Verified世界知识测试中,V4-Pro-Max以57.9%远超同级开源模型,仅略低于Gemini-3.1-Pro(75.6%),但领先Claude Opus 4.6 Max(46.2%)。
中文场景优势显著
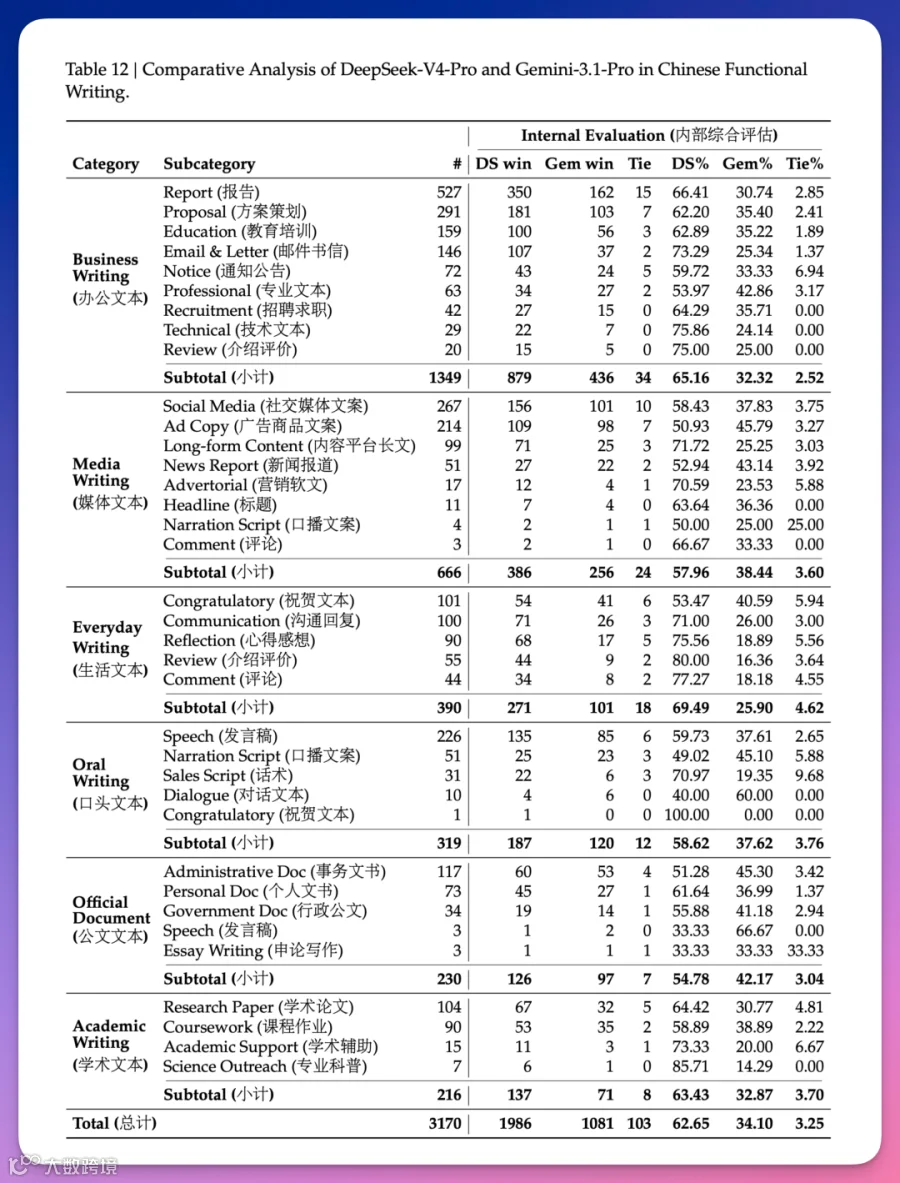
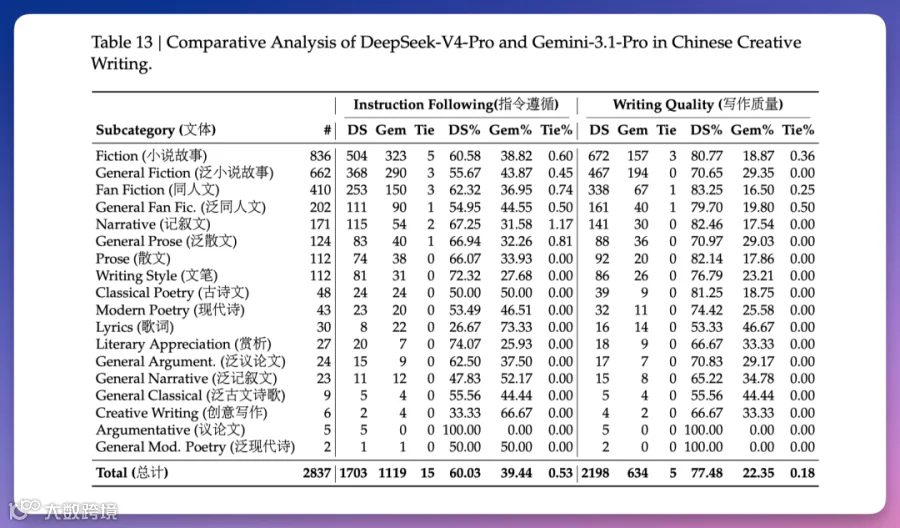
中文功能性写作评测(3170个真实任务)显示,V4-Pro以62.7%胜率显著领先Gemini-3.1-Pro(34.1%),尤其在创意写作领域质量比达77.5%对22.4%。
技术创新详解
V4突破性重写注意力架构:
- CSA(压缩稀疏注意力):每4个token压缩为1条笔记,精选512-1024条精读
- HCA(重度压缩注意力):每128个token生成1张思维导图式大纲
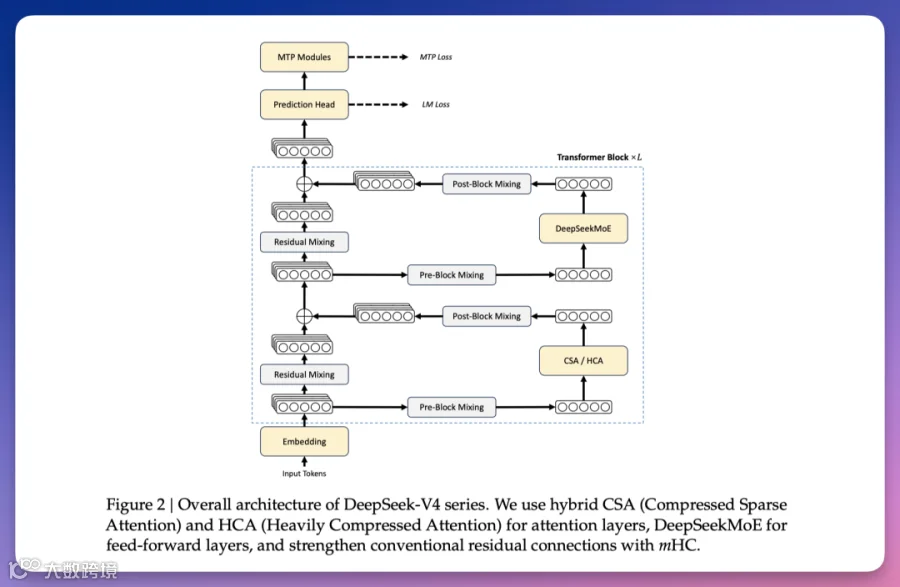
百万token上下文下单token计算量降至V3.2的27%,显存占用仅10%。配合mHC数学约束技术及OPD(On-Policy Distillation)分科蒸馏训练法,实现三种推理模式:
- Non-think:8K上下文,快速响应
- Think High:128K上下文,常规复杂任务
- Think Max:384K上下文,调用"max"参数死磕复杂问题

内部应用验证
DeepSeek工程师调研显示,85名开发者中52%将V4-Pro作为日常默认编程模型。在真实研发任务测试中,V4-Pro-Max通过率67%,接近Opus 4.5(70%),优于Sonnet 4.5(47%)。

当前V4在长文检索(MRCR 1M 83.5% vs Opus 92.9%)、复杂Agent工作流等场景仍存差距,整体发展轨迹较顶级闭源模型落后3-6个月。该1.6T参数模型已通过MIT协议开源。
不诱于誉,不恐于诽,率道而行,端然正己。