
今日,DeepSeek V4正式发布,以百万上下文标配、性能媲美顶级闭源模型及首发适配华为昇腾芯片等亮点,将大模型更新浪潮推向高峰。技术报告中,"Muon优化器"成为关键细节。
在相同训练量下,该优化器助Kimi 2.6实现2倍效率提升,解决万亿参数训练稳定性难题。杨植麟在GTC 2026强调:"采用MuonClip替代Adam训练Transformer大模型,token效率显著提升,使50万亿token发挥100万亿效果。"

Kimi 2.6底层采用DeepSeek-V3提出的MLA(多头潜注意力),而V4技术方案明确引入Muon优化器,体现技术互融:"DeepSeek的报告提及Kimi,Kimi的架构基于DeepSeek。"这种深度协作正改变中国AI创新路径。
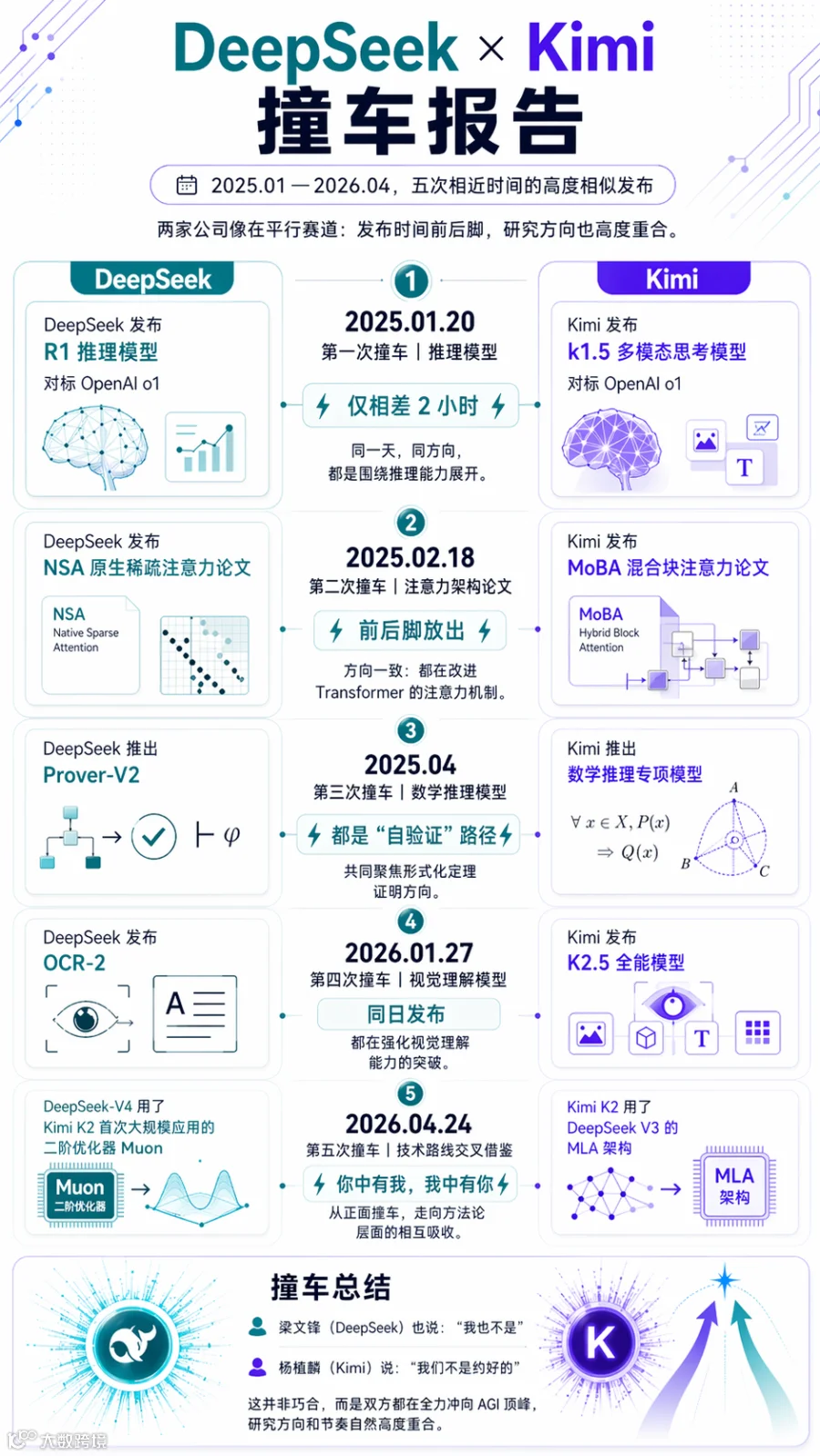
五次技术“撞车”:中国AI的拐点时刻

Long-CoT推理突破:开源格局分水岭
2025年1月,DeepSeek R1以MIT协议开源Long-CoT推理能力后两小时内,Kimi k1.5跟进,均实现"先思考后输出"。OpenAI后续论文点名此两家为中国最早复现其Long-CoT技术的企业,标志着中国AI从追随者转为引领者。
万亿参数工程化:训练与推理新标杆
近期,Kimi 2.6以SWE-Bench Pro 58.6%成绩实现Agent集群并行编程,V4将百万上下文设为服务标配并输出384K tokens。双方同步推进国产芯片适配:V4支持华为昇腾950与寒武纪,Kimi 2.6采用国产芯片混合推理方案。五次技术协同清晰印证——中国AI正脱离OpenAI对标体系,减少英伟达依赖,构建自主开源生态。
开源生态下的必然趋同

Kimi通过QK-Clip技术解决万亿参数下Muon训练稳定性问题(最大logits从超1000降至50-100),V4则混合采用Muon与AdamW优化模块。与此同时,Kimi K2架构内化DeepSeek-V3的MLA压缩KV缓存。"你的论文成基础设施,我的创新为底层支撑",展现开源社区的正向循环。
双方均挑战基础架构:Kimi探索线性注意力(Kimi Linear),DeepSeek研发稀疏注意力(DSA);共同优化残差连接方式。这种趋同源于对Scaling Law的共识及对国产化技术栈的专注。
国产芯片适配:重构AI算力底座

工程化与架构创新双路径
V4完成从CUDA到华为CANN框架的全栈迁移,覆盖算子库至内存管理,实现MoE专家并行与FP4量化训练的国产芯片部署。寒武纪同步开源vLLM适配方案。Kimi则通过Kimi Linear架构将KV缓存传输压至普通以太网承载范围,并联合清华发布PrFaaS技术,分离Prefill与Decode阶段,使吞吐提升54%、首词延迟降低64%。
两套方案共同验证:"让国产芯片跑得好、跑得省",打破"高端推理必须绑定英伟达GPU"的垄断逻辑,推动黄仁勋警示的"华为平台首发"成为现实。

用中国芯片跑中国模型,服务全球开发者
海外认可度攀升:Kimi与DeepSeek稳居OpenRouter中国模型调用量前二;Cursor接入Kimi,乐天Rakuten AI基于DeepSeek开发;Meta将二者与GPT-4同列为Muse Spark基准。其开源模型性能逼近顶级闭源体系,而成本仅为1/50,加速竞争天平倾斜。
两位广东创始人的路径殊途同归:梁文锋信奉开源哲学,V4公告引用荀子"率道而行,端然正己";杨植麟践行极客精神,以"Talk is cheap. Show me the code"为准则。风格迥异却共同定义了中国开源模型的全球坐标——"你的MLA是我的基础,我的Muon是你的加速器"。
