

本文为2026年第13篇技术深度解析,阅读时长约15分钟。
随着数据量和索引规模扩大,Elasticsearch集群的脆弱性日益凸显,主要源于长尾查询和GC抖动两大问题。
长尾查询需处理百万级文档,如日志分析、电商搜索排序等场景。这类查询占用大量线程资源,导致查询线程池饱和,甚至使毫秒级短查询排队等待。GC抖动则因JVM垃圾回收不可预测,一次Full GC可能使查询延迟飙升至秒级。两者还会相互放大:GC停顿延长查询时间,加剧线程池排队。
常规优化手段如调整JVM参数、拆分集群仅能缓解问题。根本瓶颈在于:Lucene逐文档处理模型和JVM架构难以突破性能天花板。阿里智能引擎团队基于C++重构查询内核,推出elasticpp方案,在保留ES接口兼容性的同时彻底消除GC影响。
无感知迁移方案
产品设计聚焦用户零改造体验,无需修改DSL或迁移数据。通过ES插件形式嵌入,Java层经JNI调用C++动态库执行查询,不支持类型自动回退至原生路径。
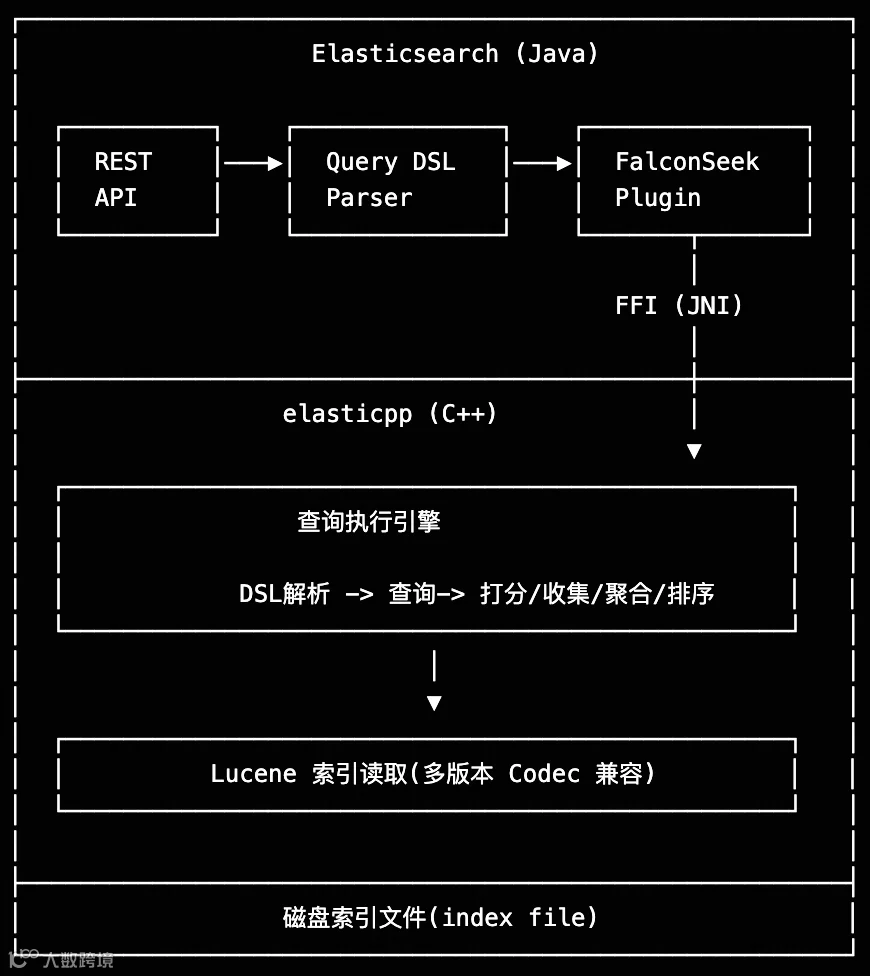
C++层完整兼容Lucene索引格式,支持主流查询和聚合操作,包括bool、term、match查询及terms、date_histogram等聚合类型。
性能优化原理
性能突破不仅源于C++替换Java,更依靠对查询路径的重构。核心优化针对文档迭代、内存访问和解码解压三大瓶颈:
批处理优化
将逐文档迭代改为批量处理,函数调用次数降至原数量级,并通过编译期模板特化消除虚函数开销。
内存预取
排序前将DocValue批量加载至连续内存,提升CPU缓存命中率,减少随机访问延迟。
零拷贝与解压缓存
合并解码与处理步骤,对高频访问数据块实施解压缓存,避免重复计算。
上述优化在数十万级文档处理中产生显著叠加效应。
典型问题排查案例
批处理改造时发现:部分查询排序结果与ES原生引擎不符。根源在于Lucene查询体系中的分数二次改写机制(如常量替换、权重系数调整)在批处理模式下未正确同步。
通过双端调试(Java侧IntelliJ断点,C++侧GDB断点)比对执行流程,确认问题源于批处理逻辑未完整复现逐条处理的隐式状态改写。验证了"批处理≠简单并行化"的关键原则:必须保证正确性优先。
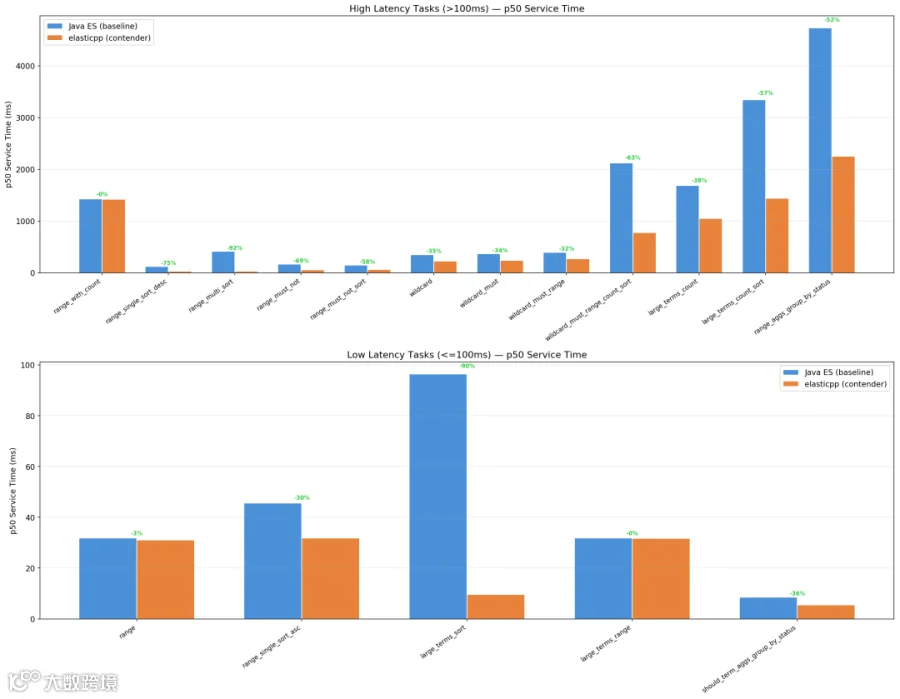
性能验证结果
基于ES Rally框架测试,在http_logs等公开数据集上,长尾查询性能提升显著:
线上场景中,毫秒级长文本查询和日志查询延迟改善明显:
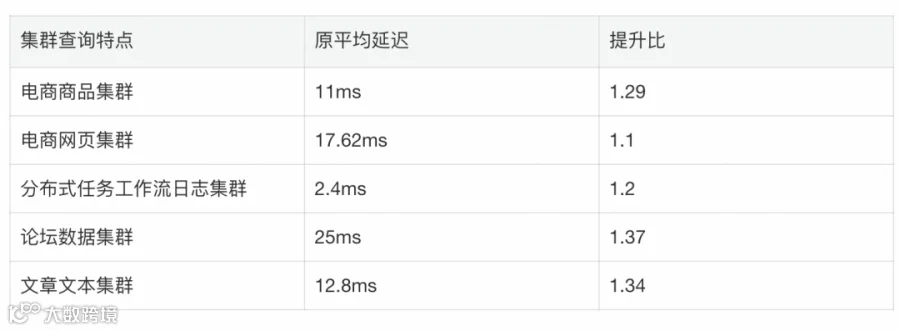
目前elasticpp已承载数十TB规模索引,稳定运行于生产环境。
未来发展方向
性能优化仅是起点,后续规划包括:
存储计算分离:支持远程索引读取,实现计算与存储资源独立扩展。
异步查询架构:增强混部调度和弹性伸缩能力,提升资源利用效率。