
国产万亿参数大模型全链路技术突破:DeepSeek-V4发布
国内首次实现万亿参数大模型、国产芯片与深度学习框架的全链路技术闭环,开源生态加速发展,开发者可低成本构建行业级应用。
核心亮点速览
支持百万级Token上下文(相当于30万行代码或整本书籍),实现跨文件分析与架构设计能力;推出V4-Pro与V4-Flash双版本战略——Pro版聚焦代码/推理领域,Agent能力比肩Claude Opus 4.6;Flash版响应速度提升50%以上,成本仅为GPT-4的1/10。核心技术突破包括:DSA稀疏注意力技术使计算开销降低50%;深度适配国产昇腾芯片,推理性能达英伟达H20的2.87倍;开源权重支持本地部署,显著降低企业使用成本。性能实测显示:代码能力覆盖338种语言,HumanEval评分90%+;数学推理MATH数据集评分75+;中文场景深度优化。
模型选择详解
V4-Pro旗舰性能
- Agent能力达开源模型顶尖水平,代码交付质量接近Opus 4.6,复杂任务处理体验超越Sonnet 4.5
- 世界知识储备大幅领先开源阵营,仅略逊于Gemini-Pro-3.1
- 数学推理与竞赛代码能力全球一流,MATH评分突破75分
- 昇腾芯片适配实现推理性能2.87倍于H20,国产技术首次突破
V4-Flash高性价比方案
推理能力达Pro版90%以上水平,API调用成本降低40%;API延迟显著优化,适合中小企业常规任务;复杂任务处理成本仅为同类方案的1/10,持续迭代优化高难度场景表现。
核心架构升级
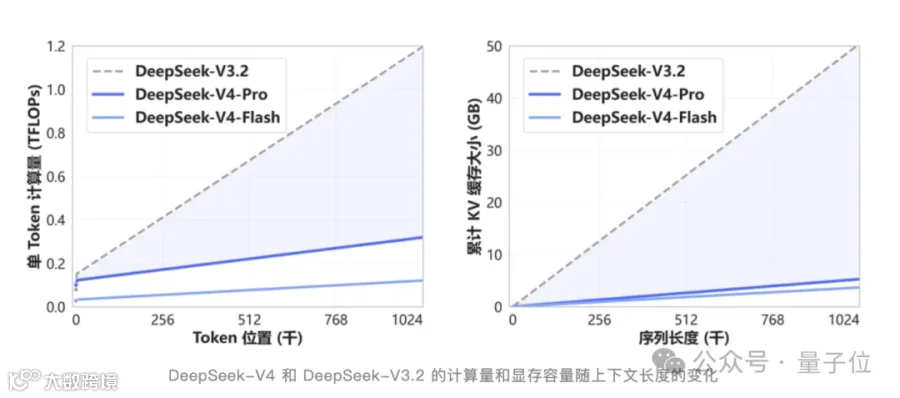
针对传统Transformer注意力机制计算量激增问题,V4创新采用双注意力架构:CSA压缩稀疏注意力将每4个Token聚合成摘要,通过Top-K筛选关键信息;HCA重压缩注意力实现每128个Token的高比例压缩。结合滑动窗口机制处理局部关联,形成粗/细粒度混合计算体系。技术演进上首次从参数稀疏化延伸至上下文稀疏化,同步升级三大核心组件——采用mHC流形约束超连接优化深层网络,启用Muon优化器替代AdamW,实现训练稳定性和收敛速度双重提升。
Agent系统优化
深度适配Claude Code、OpenClaw等主流Agent产品,优化代码任务与文档生成能力。关键改进包括:完全兼容OpenAI ChatCompletions/Anthropic双协议,仅需修改模型参数即可无缝迁移;基于Token压缩+稀疏注意力技术,1M上下文成为全系标配;V4-Flash版在轻量级任务中保持90%+效能,为Agent长周期任务提供资源保障。此次优化标志开源模型从通用对话向工业级智能体关键跃迁,通过开发生态主动适配解决落地可靠性问题。

DeepSeek-V4发布引述《荀子·非十二子》"不诱于誉,不恐于诽,率道而行,端然正己",彰显坚持开源普惠的技术路线。相较行业高价闭源策略,国产大模型在可用性、易用性与安全性实现突破性进展。
