
DeepSeek-V4首次实现国产万亿参数模型、国产芯片与国产框架的全链路技术闭环,开源生态加速发展,助力开发者以低成本构建行业级应用。
核心亮点速览
超长上下文
支持100万+ Token上下文长度(相当于30万行代码或整本书),实现跨文件分析、漏洞追踪与架构设计一体化。
双版本战略
V4-Pro:代码与推理旗舰,Agent能力媲美主流闭源模型;V4-Flash:响应更快、成本更低,推理性能接近Pro版,性价比突出。
革命性技术突破
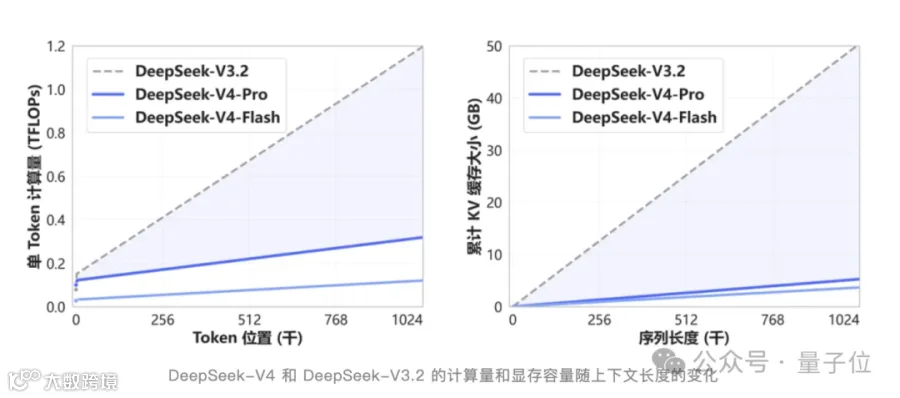
DSA稀疏注意力技术使计算及显存开销直降50%以上;深度适配国产昇腾芯片,推理性能达英伟达H20的2.87倍;开源权重支持本地部署,企业成本仅为GPT-4的1/10。
真实战力碾压
代码能力覆盖338种语言,HumanEval测试得分超90%;数学推理MATH测试达75+;中文场景深度优化,创作与分析更精准。
模型选择详解
V4-Pro核心优势
- Agent能力比肩顶级闭源模型:代码交付质量与Opus 4.6持平,复杂任务处理流畅度超越Sonnet 4.5
- 世界知识储备大幅领先开源阵营,仅次于Gemini-Pro-3.1
- 数学推理与竞赛代码能力全球一流,MATH测试得分75+
- 昇腾芯片深度优化实现推理性能突破,为国产芯片首例全链路应用
V4-Flash高性价比方案
推理能力接近Pro版,响应速度提升50%以上;API调用成本降低40%,轻量化场景效能保持Pro版90%以上。简单任务表现媲美Pro,复杂任务成本仅1/10,适合中小企业高效部署。
核心架构升级
V4的核心技术革新聚焦于注意力机制。传统Transformer模型中,每个Token需与前文所有Token逐一计算相似度,导致上下文长度增长时计算量呈平方级爆炸。V4创新性地采用分层稀疏注意力架构:
CSA压缩稀疏注意力将每4个Token的KV缓存聚合为摘要,仅筛选关键内容计算;HCA重压缩注意力以更高比例合并Token,执行稠密计算。结合滑动窗口机制处理邻近关联,形成粗细粒度混合架构。
技术演进路径清晰:V2、V3侧重参数稀疏化,而V4首次将稀疏化落地到注意力核心结构。同时实现三大底层升级——替代标准残差连接为mHC流形约束超连接以提升网络稳定性,全面启用Muon优化器加速训练收敛。这是DeepSeek首次对Transformer三大核心组件全方位重构。
Agent优化升级
DeepSeek-V4针对主流Agent产品完成深度适配,在代码任务与文档生成等场景表现显著提升。
- 无缝接入主流框架:兼容OpenAI ChatCompletions与Anthropic双接口协议,仅需调整model参数即可迁移
- 百万上下文普惠化:基于Token压缩与DSA稀疏注意力技术,1M上下文成全系标配,扫除长周期任务资源瓶颈
- 成本效能再平衡:V4-Flash在轻量任务中保持高响应效率,API成本降低40%,为自动化流程提供经济化方案
此次优化标志开源模型从“通用对话”向“工业级智能体”的关键跃迁。通过主动适配开发生态,解决智能体落地可靠性痛点,加速企业流程规模化部署。

即刻体验
DeepSeek-V4发布引用荀子《非十二子》名句“不诱于誉,不恐于诽,率道而行,端然正己”,彰显技术定力。相较于OpenAI高价闭源路线,DeepSeek选择开源普惠路径,实现中国大模型“能用、好用、敢用”的跨越式发展。
