

4 月 24 日凌晨,OpenAI发布GPT 5.5。
OpenAI总裁 Greg Brockman 在给记者的 briefing 里说了一句话:「这是一个新的智能层级,是通向更具代理能力、更直觉化计算的一大步。」
OpenAI 这次押上的模型,内部代号叫 Spud——土豆。
这是 GPT-4.5 以来他们第一个从头训练的 base 模型。中间经过的 GPT-5.1、5.2、5.3、5.4 全都是在同一个架构上打补丁。Spud 不是补丁,是新地基。
2026 年 3 月 24 日,Sam Altman 亲自拍板停运 Sora,就是为了把算力腾给这一代模型。Altman 据称在内部说过一句话: GPT-5.5 是一个「非常强的模型,能真正加速经济」。
这篇文章把三个维度的证据摊开:官方 benchmark、独立第三方评测、真实用户口碑。看完你自己判断,这个「世界第一」的头衔, OpenAI 这次是赢回来了, 还是只赢了数字。

先看 OpenAI 自己公布的成绩单
在公开可访问的前沿模型范围内,GPT-5.5 在 14 项 benchmark 上拿到 SOTA。对比之下,Claude Opus 4.7 是 4 项,Gemini 3.1 Pro 是 2 项。
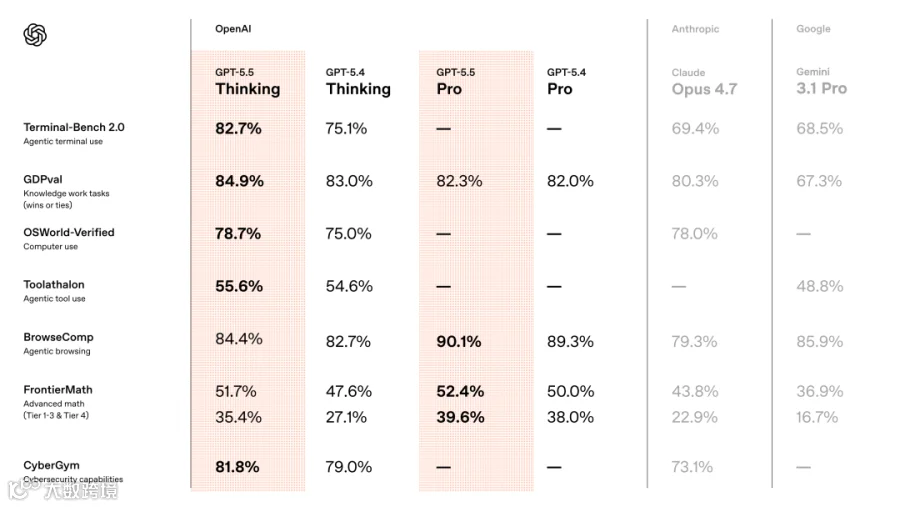
最刺眼的一个数字是 Terminal-Bench 2.0,82.7%。这个 benchmark 测的是模型在 sandbox 终端环境里完成复杂任务的能力,需要规划、迭代、调用工具。Opus 4.7 在这项上是 69.4%,Gemini 3.1 Pro 是 68.5%。13 个百分点的差距,在前沿模型的竞争里已经不算「略有领先」了。
OSWorld-Verified 是另一个硬指标,测的是模型能不能自主操作真实计算机环境。GPT-5.5 拿到 78.7%,超过了人类基准 72%。GDPval 覆盖 44 个职业的知识工作,GPT-5.5 拿到 84.9%。BrowseComp 测的是模型能不能在网上找到那些不好找的信息,GPT-5.5 Pro 拿到 90.1%,Gemini 3.1 Pro 是 85.9%。
还有一个更值得玩味的数据。CyberGym(网络安全)81.8%,FrontierMath Tier 4 35.4%。这两个都是 Anthropic 在 Mythos 上优势非常明显的领域,GPT-5.5 这次直接追了上来。
OpenAI 的叙事非常清楚:GPT-5.5 不是比 GPT-5.4 聪明一点,是跨过了一个阈值。
更要命的是效率。每个 token 的延迟和 GPT-5.4 持平,但完成同样 Codex 任务的 token 消耗大幅下降。按 Artificial Analysis 测下来,Intelligence Index 的总 token 使用量比 GPT-5.4 少了约 40%。Brockman 的原话是,GPT-5.5 是一个「更快、更锐利的思考者,用更少的 token」。
这是一套漂亮的牌。
但是。
GPT-5.5 唯一输的那项,OpenAI 在小字里暗示 Claude 作弊
GPT-5.5 只有一个数字输给了 Opus 4.7。OpenAI 在这个数字旁边加了一颗星,小字里暗示 Anthropic 可能作弊。
那项是 SWE-Bench Pro,测的是模型解决真实 GitHub issue 的能力,coding 类 benchmark 里最接近工业界实际工作流的一个。GPT-5.5 拿到 58.6%,Claude Opus 4.7 拿到 64.3%,反而领先 5.7 个百分点。
OpenAI 官方表格里给 Opus 4.7 那个数字标了颗星,脚注写着:「labs have noted evidence of memorization on this eval」(有研究机构注意到这个评测上存在记忆污染)。
翻译过来就是:我们怀疑 Claude 是见过这些题的,不算数。
但 OpenAI 没给自家 GPT-5.5 在同一套过滤条件下的复测成绩。Anthropic 倒是主动做了一份过滤掉可疑样本的重新评测,Opus 4.7 的优势基本保持不变。
这是整份发布稿里最诚实的一处不诚实。

第三方怎么打分
你不可能完全相信任何一家模型厂商自己发的 benchmark。独立第三方的打分才是关键。
Artificial Analysis 是目前业内最被认可的独立评测机构之一。他们在 GPT-5.5 发布当天也放出了评测结果。他们的 Intelligence Index v4.0 是一个聚合了 10 项评测的综合分,包括 GDPval-AA、Terminal-Bench Hard、SciCode、Humanity's Last Exam、GPQA Diamond 等。
结果是:GPT-5.5(xhigh)60 分。Claude Opus 4.7(Max Effort)57 分。
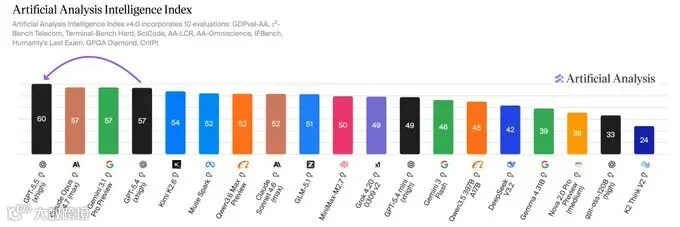
Artificial Analysis 官方的判词很谨慎:「GPT-5.5 让 OpenAI 重新回到了清晰的 #1 位置。在此之前,OpenAI、Anthropic、Google 三家基本并列。」
3 分的差距,在他们的打分体系里是「打破并列」。但也就仅此而已。这不是碾压,是追平之后挤出半个身位。
还有一个关键 benchmark 叫 OpenAI MRCR v2,测的是超长上下文的检索能力。在 512K-1M token 区间,GPT-5.5 拿到 74.0%,Claude Opus 4.7 是 32.2%。这是本次所有对比里分差最夸张的一项。对于要做整代码库推理、多文档研究、长 agent 轨迹的场景,GPT-5.5 的可靠性是另一个量级的。
但你要问 Claude Opus 4.7 在什么地方仍然领先,有一项:Humanity's Last Exam。这是目前全球最难的通用推理题库,不让模型用工具。Opus 4.7 在这项上拿到 46.9%,GPT-5.5 Pro 是 43.1%,Anthropic 未公开的 Mythos Preview 更高,到了 56.8%。
所以第三方打出来的结论是什么?benchmark 层面,OpenAI 确实赢了,赢的方式不叫降维打击,更像压哨进球。

开发者的真实反馈
发布 24 小时内,Twitter 和 HN 上已经攒了一大摞一手测试。
日本开发者 @SuguruKun_ai 直接用 GPT-5.5 + Codex 的 Computer Use 功能,几乎一键生成了一个完整可玩的 3D FPS 射击游戏。Three.js 实现,第一人称射击、移动、打红球靶子、血量弹药和分数实时更新。左边面板能看到 GPT-5.5 自己在迭代 prompt、跑调试、修 bug。他的评价很简单:比之前用其他工具做的 10 个 3D 游戏体验都强。
Riley Brown 的测试更狠。他只用了几条 prompt,GPT-5.5 就自己规划轨道、生成 25 列以上的火车在复杂轨道网络上运行、实现自由视角(Free/Bird/Follow/POV)、处理速度调节和碰撞后的非确定性重生,搞出一个完整的 3D 火车世界模拟器,还带实时 Crash Counter,已经破了 1600 次碰撞。他的判断是,这是第一次感觉 ChatGPT 能真正解决一个复杂的交互模拟需求,而不只是响应。
Adrian Morris 的测试代表另一种感觉。他把之前用 Claude 写的一份 .md 模板喂给 GPT-5.5 Codex,让它一次性生成一个自己花了 6 个月手动搭建的复杂算法。GPT-5.5 不仅自动重写了模板、优化了语法,还带完整 changelog,95% 正确,一次过。他的评价很有参考价值:在复杂代码库的顶层设计上,GPT-5.5 比 Claude 更强;但在执行和纠错上,Claude 仍然有优势。
数学家 @QiaochuYuan 做了三道研究生到研究级的题测试:非交换环论的反例问题、度 7 多项式的 Galois 群计算、集合族的图论构造。无工具、无搜索。GPT-5.5 给出了全新构造,用算术级数 + 素数 + 中国剩余定理完成证明,比原 MathOverflow 答案逻辑还清晰。他的结论是:到目前没发现任何数学错误,理解深度远超一年前的模型。
产品人 Brennan McEachran 的测试最离谱。他让 GPT-5.5 + Computer Use 做一个 slide-by-slide 的循环:自动生成图像、挑选、迭代、插入 PPTX、验证、进入下一页。最终生成 21 张幻灯片,主题从链条、公路、汽车到分子、地球仪、图表、护盾、闪电全覆盖,打开 PowerPoint 验证通过,XML 无错误。整个循环几乎没有人工介入。
被 OpenAI 放进发布稿的两句 CEO 金句也值得引一下。MagicPath 的 Pietro Schirano 让 GPT-5.5 合并了一个包含数百次前端和重构改动的分支,主分支也在同期大量变化,20 分钟一次通过。他的原话是:「I'm working with a higher intelligence, and there's almost a sense of respect.」Every 的 CEO Dan Shipper 的评价更短但更重:「这是我用过的第一个具备严肃概念清晰度的 coding 模型。」
但吐槽从发布第一天就同样猛烈。
价格翻倍是最集中的槽点。API 定价每百万 input token $5、output token $30,比 GPT-5.4 整体翻了一倍。Claude Opus 4.7 是 $5/$25,output 还便宜 17%。很多开发者在 X 上算账:虽然 token 消耗少了 40%,单价翻倍之后真实 per-task 成本也就降了一点点,某些高 reasoning 场景反而更贵。有人直接吐槽 API pricing 是「crazy expensive」。
设计能力是第二个槽点。@CtrlAltDwayne 直接说:「coding 强得惊人,但前端设计完全没进步,怎么引导都救不回来,出来的还是 AI slop HTML。」这个槽点从 GPT-5 时代延续至今,重训一次 base 也没解决。
性格问题是第三个。有用户在高 reasoning 模式下觉得 GPT-5.5「overthink,还狂甩 unit tests」,有人吐槽它「有点用力过猛,偶尔 cringe edgy」。建议默认开 Low 模式的声音也冒出来了。但也有相反的声音。怀念 GPT-4o 亲切感的用户说,5.5 终于找回来一些人情味,「比 5.4 微妙得多」。
Claude 粉反向喊话也有。有人在 PK 之后直接下断言:「Opus 4.7 sucks AF. Why does it feel really dumber after GPT 5.5??」但另一拨人的测试得出完全相反的结论,说 Opus 4.7 在真实复杂任务上仍然「更 thorough」。最后一类测试来自 Among Us 多代理游戏:GPT-5.5 在这个需要撒谎的游戏里「说谎更少,照样赢了冠军」,被网友玩成了梗。
最戏谑的一个段子来自 @DenisVodchyts,总结了所有大模型发布后的用户情绪曲线:第 1 天「这玩意儿疯了吧」,第 3 天「好像变差了」,第 5 天「经过 17 次 prompt 调优后,真香」。
这条曲线对 GPT-5.5 大概率也会成立。现在还在第 1 天。
 GPT5.5 配不配得上「世界第一」
GPT5.5 配不配得上「世界第一」
benchmark 的答案是:配,以 3 分的微弱优势。
LMArena 的答案是:还没投,但按民意风向,至少到月底前不配。
开发者的答案是:分场景。
这三个答案之间没有矛盾。它们共同指向了一个更清晰的现实——今天的前沿模型,已经分化成了两个不同的产品哲学。
GPT-5.5 是一个为「行动」而生的模型。它的全部架构投入都在 agentic coding、computer use、long-horizon 多步任务、工具调用、token 效率。你给它一个 messy 的需求,它自己规划、自己调试、自己跑 terminal、自己写几千行代码然后自己修 bug。它被设计来帮你把事情做完,不是设计来陪你聊天。
Claude Opus 4.7 走的是另一条路。它在 LMArena 上拿下的「民意护城河」本质是一种气质优势:对用户意图的细腻理解、代码审美的稳定性、长对话里的一致性、对模糊问题的深度权衡。你愿意把一个需要判断的问题交给 Claude,是因为你相信它会认真地想,而不是立刻扑过来干活。
OpenAI 赢了 benchmark 榜,但 Claude 仍然赢了「你真的想一起工作的那个搭档」。
所以现实的选法变得很简单:
要做事,用 GPT-5.5。要让 agent 跑一整夜、要让 Codex 自主合并几百个 commit、要操作计算机完成一个复杂工作流,当下没有更好的选择。
要思考,用 Claude。要做严肃的 code review、要写复杂业务逻辑、要做有细微权衡的文档和对话,人类投票还没倒向 GPT-5.5。
要省钱,两家都得算账。GPT-5.5 单价贵,但 token 消耗少。Claude output 便宜 17%,但新版 tokenizer 消耗 1.0-1.35 倍的 input。真实 per-task 成本需要你在自己的 workload 上实测,list price 算不出来。
Sam Altman 没说错,GPT-5.5 是一个非常强的模型。
OpenAI 拿回了基准层面的王座。
接下来三个月,真正的问题是——当 Anthropic 的 Mythos 从 preview 走向 GA,当 Gemini 3.5 放出来,当开发者在 LMArena 上用真实使用投出那些决定性的选票,这个王座还能坐多久。
大模型世界第一这个头衔,正在变成一个每七天就要重新换人的临时岗位。

