
4月24日,DeepSeek挂出V4预览版:Pro版1.6万亿总参数,激活49B;Flash版284B,激活13B;上下文100万token。权重走MIT开源协议,API当天开放,同步放出技术报告。
这是自2025年1月R1引发热度以来,DeepSeek时隔15个月交出的第一个全新旗舰。
15个月里,外界能看到的动作并不少,V3.1、V3.1-Terminus、V3.2-Exp、V3.2、V3.2-Speciale都发过,但真正被称为"新一代"的只有V4。跳票三次,第一次传闻是2026年2月春节档,第二次是3月,第三次才落地到4月下旬。核心研究员流向字节和小米,豆包月活反超登顶中国AI应用榜首。舆论层面,DeepSeek被不少人写进了"掉队名单"。
但把V4的技术报告和过去一年DeepSeek的arXiv发稿表放在一起对照,会看到另一幅图景:V4是15个月里分步交付的集成结果,不是空转后的突击产物。它的每一块架构砖,CSA、HCA、mHC、Muon、MoE扩展到384个专家,早就以论文、开源代码、实验模型的形式,提前吧V4的技术路线画清楚了。

论文先于模型,V4的地基全在明面上
先看V4-Pro技术报告列出的核心升级清单:混合注意力架构(CSA+HCA)、流形约束超连接(mHC)、Muon优化器、两阶段后训练管线、MoE层384个专家每token激活6个。
这些名词里没有一个是4月24日的新发明。
mHC是2025年12月31日发布的论文《Manifold-Constrained Hyper-Connections》,arXiv编号2512.24880,梁文锋亲自署名。论文的切入点非常具体:Hyper-Connections这一代超连接结构虽然在增加残差流宽度上有效,但会破坏身份映射性质,让大模型深层训练出现不稳定。DeepSeek团队的解法是把残差空间投射到一个特定流形上(用Sinkhorn-Knopp算法保证双随机矩阵约束),恢复身份映射,并配合TileLang做内核融合来压overhead。

当时在27B规模上的实验数据已经相当亮眼:BBH从43.8(baseline)→48.9(HC)→51.0(mHC);训练过程中loss spike消失;GPU训练时间overhead只有6.7%。一位海外工程师Subhadip Mitra在博客里把这篇论文称作"striking breakthrough"。
这篇论文发在元旦前夕,延续了DeepSeek"节假日搞事情"的传统。V4-Pro技术报告第一个架构亮点,就是mHC。
Engram是第二块砖。2026年1月12日,DeepSeek发布《Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models》,arXiv编号2601.07372。论文提出一个朴素但锋利的观察:Transformer处理"Diana, Princess of Wales"这类静态实体时,其实是在用多层注意力和FFN重建一个本该被哈希查表取走的固定关联,浪费了深层算力。

Engram是一个基于N-gram哈希的O(1)查表模块,和MoE一起构成两条独立的稀疏性轴线。一条走条件计算,一条走条件记忆。论文在Engram-27B上相对MoE-27B等参数等FLOPs对照组,MMLU+3.4、BBH+5.0、HumanEval+3.0、Multi-Query NIAH从84.2跳到97.0。
这里有个细节值得注意:论文一作是北大在读博士Xin Cheng,通讯作者列表里有梁文锋。Engram仓库1月12日发稿,DeepSeek的FlashMLA生产内核库1月20日出现了MODEL1引用,中间只隔了9天。有Medium博主把这层关系挖了出来,认为Engram的查表机制已经开始和生产推理内核集成。
V3.2-Exp是更早的一块砖。2025年9月29日发布,核心是DSA(DeepSeek Sparse Attention),一个lightning indexer加细粒度token选择的稀疏注意力机制。当时跑分和V3.1-Terminus基本持平,社区反应冷淡,普遍认为是个无足轻重的experimental版本。但12月2日DeepSeek-V3.2正式版发布时,跑出了IMO 2025和IOI 2025双金,数学推理能力对标Gemini 3.0 Pro。Sebastian Raschka在博客里回顾时直接点出:V3.2-Exp就是为了让推理基础设施提前适配DSA,是在给后面铺路。
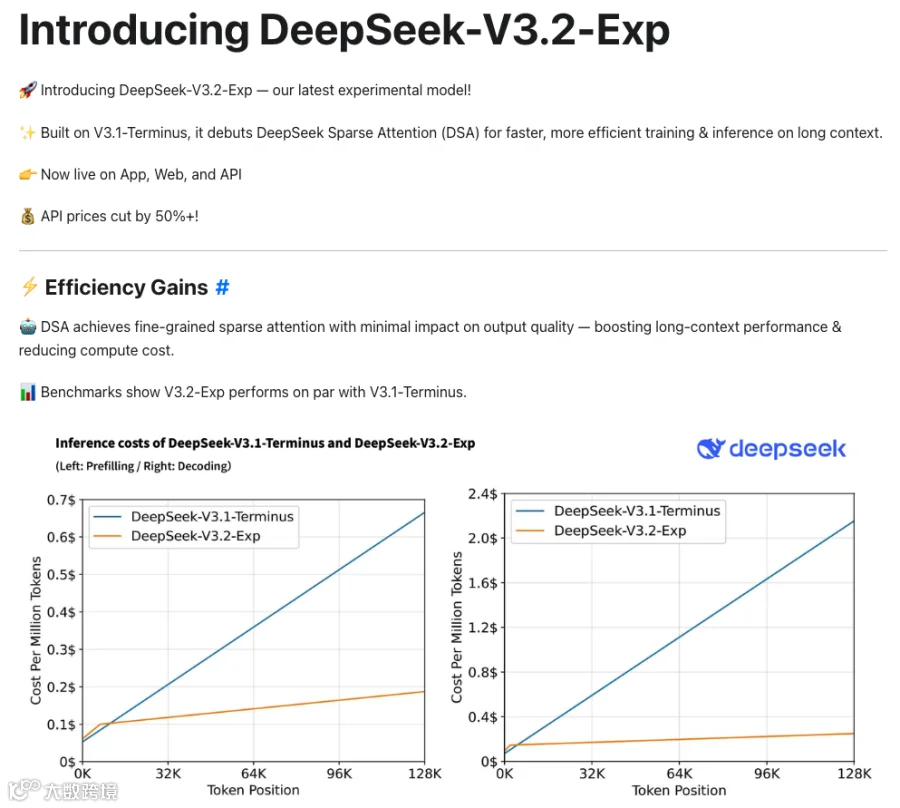
V4-Pro技术报告的混合注意力是CSA+HCA,Compressed Sparse Attention加Heavily Compressed Attention,算是DSA路线的进一步压缩版本。整条"稀疏注意力"的DNA从V3.2-Exp开始就已经确立。1M token上下文下,V4-Pro单token推理FLOPs只需要V3.2的27%,KV缓存只需要10%。
Muon优化器的算法细节也早就是公开信息,DeepSeek的说法是"用Muon做大部分模块的优化,embedding、prediction head、部分mHC参数和RMSNorm权重保留AdamW",收敛更快、训练更稳。
把时间线连起来:2025年9月DSA进生产、12月mHC论文上线、2026年1月Engram论文上线、1月FlashMLA代码库出现MODEL1引用、4月V4发布。每一步都留在光天化日之下。

换芯:V4为什么姗姗来迟的另一个答案
论文节奏只是一条叙事线,另一条是算力底座。
根据Reuters、The Information和EE Times China的交叉报道,V4最初定档2026年春节档,跳了三次才在4月下旬落地。延迟的核心原因之一,是DeepSeek花了几个月时间和华为、寒武纪一起,对模型底层架构做了大量改写,以适配国产芯片。
V4发布当天,华为宣布基于Ascend 950芯片的Ascend超节点"全面支持"V4模型推理;寒武纪也迅速宣布兼容。DeepSeek官方公告里明确提到"深度适配国产芯片"。华泰证券的分析师评价说,这会带动国产显卡能力的实质提升和广泛普及。

但需要区分一个关键问题:V4是"在国产芯片上训练",还是"在国产芯片上推理"?
技术报告给出的答案是后者。V4的MegaMoE融合推理内核已经在昇腾NPU上跑通,在通用推理场景达成1.5×-1.73×加速,延迟敏感场景最高1.96×,和英伟达GPU上的加速幅度一致。DeepGEMM仓库也同步开源了MegaMoE的CUDA版本。DeepSeek把这称为"production-level inference dual-platform validation"(生产级推理双平台验证)。
训练侧的故事要复杂一些。Reuters此前的报道说V4可能是在英伟达Blackwell上训练的,The Information则爆料DeepSeek获取了数千张通过第三国拆解走私进入中国的高端芯片(Nvidia和DeepSeek都否认了这一说法)。Jensen Huang在Dwarkesh播客上公开警告,如果DeepSeek把模型专门优化到昇腾芯片上,"对美国是个糟糕结果"。真实情况大概率介于两者之间。训练仍主要依赖英伟达GPU,但推理栈、算子库、通信库都在向CANN迁移。
这条"换芯"路径的真实意义在软件层。CUDA的二十年霸主地位建立在两层软件锁上:芯片是一层,算子库和编译器生态是第二层。DeepSeek花几个月改写核心代码适配CANN,等于在软件锁上凿出一个口子。163.com援引维金研究的观点:如果DeepSeek未来一到两年内能在昇腾上跑通推理和训练的全栈软件,核心模型开发管线就能事实上脱离CUDA。
这条路本身就是高风险的。模型跳票、社区议论、用户流失都是代价。但这个代价换来的东西远不止V4一个模型的交付,更是一条新的技术主权路线的验证。

跳票、出走、被写进讣告之后交卷
DeepSeek过去15个月外部舆论的反复,在V4发布当天戛然而止。
2025年年中到下半年,郭达雅和罗福莉等核心研究员先后出走字节和小米。The Information从2月开始反复爆V4发布窗口,2月、3月、4月每次都落空。DeepSeek官方的回应永远是沉默。豆包月活冲到1.57亿登顶中国AI应用榜首,DeepSeek退居第二。Anthropic在2月23日公开指控DeepSeek通过15万+账号对Claude做过"工业级蒸馏"以构建自己的奖励模型,虽然争议巨大,但至少说明DeepSeek的数据管线的复杂度已经到了值得对手专门报告的程度。
4月中旬,DeepSeek启动成立以来第一次外部融资,估值不低于100亿美元,拟筹集至少3亿美元。阿里、字节、腾讯等大厂提前预订了数十万张下一代AI芯片,据称价格因此被推高了20%左右。这些动作叠加在一起,说明跳票期间DeepSeek在多线同时加码,远不是停滞。
V4发布当天,DeepSeek在推特上贴出了《荀子》里的一句话:"不诱于誉,不恐于诽,率道而行,端然正己。"这句话不煽情,但切题。它表达的意思是"按自己的节奏走",不是"我们憋了个大的"。
节奏本身是一种选择。
主流AI公司通常是产品节奏驱动,季度发布会、年度Keynote、benchmark刷榜是标准动作。DeepSeek选了另一套节奏:论文打节拍,模型压正拍。V3.2-Exp的冷淡收场、mHC论文的元旦前夜、Engram论文的中旬空降、V3.2正式版冲IMO金牌,每一个看似独立的事件,事后都能在V4技术报告里找到对应位置。
这种节奏有一个很容易被忽视的副产物:对开源社区的技术预埋。mHC发论文后,tokenbender在GitHub上做了研究级PyTorch实现;Engram仓库开源权重和代码,Substack博客、Medium深度拆解、Tom's Hardware专题文章接连出现。到V4正式发布时,整个社区对底层架构的理解已经非常深入,不需要DeepSeek再花一场发布会去科普。
这是一种更成熟的工程思维:把一次大版本拆解成多个可独立验证的里程碑,每个里程碑都在学术共同体的监督下完成。社区帮你检验技术可行性,你按自己的节奏完成系统集成。

V4的位置:开源第一,闭源还差一截
V4的真实技术水位需要放到当下的基准测试里看。以DeepSeek自己公布的技术报告数据:
V4-Pro-Max在Codeforces上拿到3206分,超过GPT-5.4 xHigh的3168分和Gemini 3.1 Pro High的3052分,这是竞赛编程第一次被开源模型拿下。LiveCodeBench、Apex Shortlist也都领先。数学方面,HMMT 2026 Feb 95.2、IMOAnswerBench 89.8。
但代码工程领域的表现就复杂多了。SWE-Bench Verified打平80.6,和闭源旗舰平齐;SWE-Bench Pro拿到55.4,被Kimi K2.6的58.6压了3分;Arena Code榜上K2.6领先73 Elo。换句话说:短代码生成和竞赛题,V4-Pro-Max第一;真实GitHub仓库级的bug修复和长程agent任务,Kimi K2.6更强。
长上下文检索是另一个硬伤。MRCR 1M上V4-Pro 83.5,Opus 4.6拿到92.9;CorpusQA 1M上V4-Pro 62.0,Opus 4.6是71.7。1M上下文V4是扛住了,但检索精度离Opus还差一截。GDPval-AA经济价值评分上,V4-Pro 1554,GPT-5.4 1674,Opus 4.6 1619。知识工作的经济价值维度,闭源模型仍然领先。
V4真正的"杀手锏"不是跑分,是成本曲线。Kingy AI的分析里有一句讲得挺准:V4是第一个让routine 1M token上下文在经济上变得现实的开源模型。1M context下V4-Pro推理FLOPs只占V3.2的27%,KV缓存只占10%,Flash版更极端。API定价Pro版约1.74/3.48美元每百万输入/输出token,Flash版12倍便宜。V4-Flash的价格甚至和DeepSeek V2发布时(2024年6月)持平。
这是个相当激进的价格锚。Opus 4.7是5/25美元,GPT-5.5更贵。V4把开源旗舰的价格和闭源顶级模型的价格差又拉开了一个数量级。
所以V4是不是"重新定义了行业"?诚实的答案是:没有。闭源顶级模型在agent任务、长上下文检索、知识工作经济价值上依然领先。但在"能不能用得起"这个问题上,V4把开源能做到的极限又往前推了一大步。
蛰伏的真正含义
回到开头那个问题:DeepSeek是不是在沉默?
V3.1 → V3.1-Terminus → V3.2-Exp → V3.2 → V3.2-Speciale,这条轨迹本身就是持续迭代的中间版本链,够不上"沉默"的评价。mHC、Engram、DSA三篇论文加一个FlashMLA代码库,做的是把架构创新拆成学术工件逐件交付,远不止"突击发布前的预热"。跳票三次、核心员工流失、排名被超越,这些都是代价,但停滞没有在数据上成立。
蛰伏不是躺平。蛰伏是选择不和别人保持同一个节奏。
这和主流模型厂商的打法是两套逻辑。
主流打法追求每季度新闻周期,追求benchmark榜首位置,追求用户感知的迭代速度。DeepSeek的打法追求的是另一个东西:用论文把社区变成自己的质检员,用开源把生态变成自己的分发渠道,用时间换架构的成熟。
V3.2-Exp发布时跑分不亮眼,当时被轻视。现在回头看,那是V4地基的浇筑现场。mHC论文发元旦当天,被当成"又一篇DeepSeek论文"刷过去。现在回头看,那是V4深度训练稳定性的最后一块拼图。Engram论文发1月12日,被很多人归为"有趣但不知道怎么用"。现在回头看,那是V4长上下文检索的理论来源。
把这些事件按时间串起来,再对照V4发布当天的技术报告,蛰伏这个词的真正含义就出来了。它描述的是一种关于技术信心的长期投资,而不是"等待时机"的被动姿态。你把单点创新拆散了发在学术社区,赌的是社区的检验能帮你验证它能不能走得通;你把模型节奏压在架构成熟度上,赌的是一次完整的交付比十次追热点更有价值。
4月24日这天DeepSeek交了卷。Pro版1.6万亿参数,Flash版284B,100万token上下文,CSA+HCA混合注意力,mHC流形约束超连接,Muon优化器,MegaMoE双平台推理内核,MIT开源。技术报告结尾那句《荀子》能当成过去15个月选择的注脚。

