


引言.
沉寂了一段时间的 DeepSeek,这次终于放大招把 V4 给放出来了!
预览版一上线,信息量直接拉满:双管齐下,一个是性能强到没边的 V4-Pro,一个是主打唯快不破的 V4-Flash。

最抓人眼球的亮点在哪?大伙儿第一反应可能是 1M(一百万)超长上下文。
但有一说一,百万上下文在目前的 AI 圈其实算不上什么独家黑科技,毕竟隔壁 GPT 早就支持了。DeepSeek 这次真正的“大杀器”,其实是这俩字:普惠!
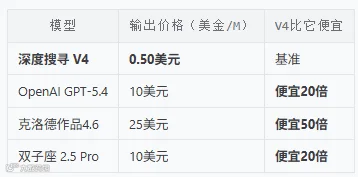
以前咱想让 AI 啃个大部头文档、盘个复杂的长代码库,虽然知道市面上有百万上下文的模型,但看着那高昂的 API 调用成本,或是必须升级昂贵的付费会员,钱包实在肉疼,最后还是只能小心翼翼地把文件切碎了喂。
并且它的优势不止这些。

现在倒好,DeepSeek 直接把它们拉下了神坛,这么多功能当成了这代模型的“标配基础设施”!
你不仅可以在网页端、App 里直接无门槛上手,通过 API 接进自己的工作流也是极其友好的“白菜价”,官方甚至还极其硬核地甩出了开源权重。
这波操作,才是实打实地把“百万上下文普惠时代”拍在了咱们面前!

这波更新真有点当年划时代那味儿了,必须单独开一篇跟大伙儿好好盘盘。

思考.
有一说一,DeepSeek 过去一年在国内 AI 圈的位置,确实挺特殊的。
它从来不是那种靠天天刷屏、整活儿做噱头的产品。但大伙儿心里都明白:只要这哥们儿一出手,全行业的目光绝对得死死盯着。原因也简单,它之前硬是靠着 V3 和 R1,把“国产开源模型到底能不能打”这个天花板,直接往上捅破了一大截。
最让我觉得有意思的是 DeepSeek 身上那种不一样的“气质”。它不像有些厂子,一上来就想怎么“手搓”个爆款 App 赚快钱,或者把商业化故事讲得天花乱坠。梁文锋早就在采访里亮过底牌:人家的目的地是 AGI。

所以他们更愿意去啃模型结构、训练效率这些最难啃的“硬骨头”。说白了,这就一帮纯粹的技术极客,靠着好奇心和技术预判,在帮国产模型探路。
但人红是非多,成了焦点,压力也就跟着来了。
R1 爆火之后,DeepSeek 被推到了聚光灯的正中央。国外媒体、国内大厂、资本市场,甚至猎头公司全都在盯着它。
最近圈子里传闻不少:一边是估值狂飙,另一边却是核心成员被大厂“挖墙脚”。有报道说 R1、OCR、多模态这些方向的大拿,不少都去了腾讯、字节、元戎启行。
这事儿咱得理性看,大模型行业现在抢人实在太狠了。一个真正打过硬仗的高手,市场肯定分分钟给出定价。

所以,这次 V4 出来,意义早就超过了一次单纯的模型更新。它更像是 DeepSeek 给外界的一份“回应”:在光环之后、在人才流动之后,这支团队还能不能继续保持那种“硬核”的创新力?能不能从一个纯研究团队,慢慢补齐工程、算力、产品和生态这些短板?
当然,跑分数据依然挺“哇塞”的。官方直接把 V4-Pro Max 拉去跟 Opus 4.6 Max 贴脸开大,长上下文、代码、Agent 这些项目全摆在明面上。能进这个级别的参照系,本身就说明国产模型已经过了“关起门来自己玩”的阶段了。
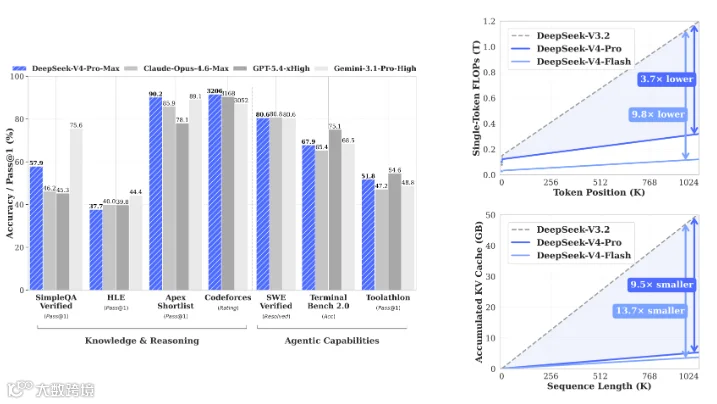
最后,还有一个最炸裂的看点:国产算力。
DeepSeek-V4 这次是跑在华为先进芯片上的,还跟华为、寒武纪做了深度的底层适配。咱得知道,过去国内大模型最难受的就是被海外 GPU 卡脖子。模型再好、应用再多,底层如果不顺,天花板始终在那儿。V4 这一步要是跑顺了,对国产大模型来说,那就是实打实的里程碑。
它会告诉全世界:国产模型不能只会陪聊刷榜,咱们长文本、Agent、API、开源样样精通,而且国产算力这条路,咱也慢慢蹚平了!

AI+.
DeepSeek-V4 这次该怎么用,我建议大家根据自己的需求,分三条路走。
01 普通用户:别折腾,直接去网页端或 App
如果你只是想体验 1M 上下文到底有多强,最简单的方式就是打开官网。不需要配显卡,也不需要看那些劝退的部署教程。(网站地址:https://chat.deepseek.com/)
它最适合拿来干这几件事:
长文档“扫毒”:几十万字的合规合同、技术白皮书,一次性丢进去。
代码库解读:把整个项目的文档和核心代码塞给它。
这里有个实测的小心得:别一上来就让它“总结全文”,这太浪费 1M 上下文的能力了。你可以换个问法:“先不要总结,帮我把这份资料按逻辑分成 5 个部分,每部分的核心差异点列出来。”
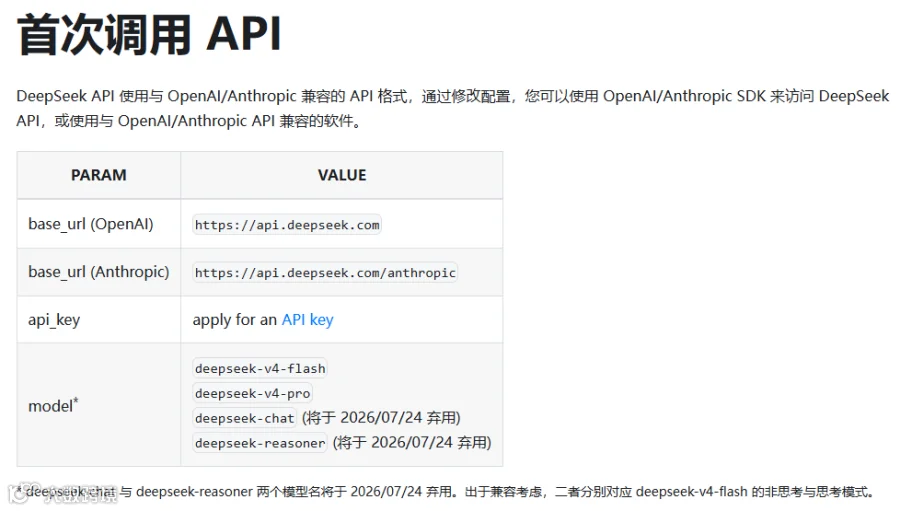
02 开发者:API 已经对齐,先测 Flash 再上 Pro
官方 API 文档已经更新了,格式完全兼容。模型名记得改,追求极致效果的调deepseek-v4-pro,追求响应速度和成本的调deepseek-v4-flash。
建议在实际产品流里做一个分层:普通的摘要、分类、客服咨询,全推给 Flash,成本能省下一大截;只有遇到复杂推理或超长资料处理时,再调用 Pro 模式。
03 极客与工作室:本地部署前,先算一笔账
V4 虽然开源了,但它对显存和算力的胃口,不是普通家用电脑能满足的。
就算是轻量级的 V4-Flash,也需要 128GB 以上的内存,配上至少 4 张大显存卡(华为系32g显卡)。如果你想跑顺 V4-Flash 的完整能力,一套机器的成本大概率要往60-90 万看。

如果要冲 V4-Pro,那就不再是“装台机器”的事,而是“算力工程”了。8 卡服务器起步,整机落地的成本可能在120-180 万之间。
所以,如果你是小团队:
想尝鲜,先用网页版。想业务集成,走 API 租用。只有涉及极高密级的私有化需求,才去考虑买服务器。

三句话.
关于 DeepSeek-V4 这次更新,前面该说的基本都说完了,最后简单总结三句话:
第一,V4 对 DeepSeek 来说,不只是一次技术发布,也是一次重新证明自己的机会:经历爆火、质疑、人才流动之后,它需要用新模型告诉大家,自己不是只靠一波热度冲上来的。
第二,1M 上下文真正值钱的地方,不是“能塞更多字”,而是让 AI 有机会从聊天工具变成生产工具,去处理长文档、长代码、知识库和复杂 Agent 任务。
第三,DeepSeek 这次给中国 AI 行业打了一针强心剂,真正属于国产 AI 的大时代,即将拉开序幕!

彩蛋.
为了方便大家深度研读,我把 DeepSeek-V4 的官方技术细节、各版本参数对比以及 1M 上下文的官方说明汇总成了一份文件。
想看看 V4 到底在国产芯片上跑了多少分的同学,可以拿回去细看。

回复关键词:DeepSeek-V4 获取。