搜索
首页
大数快讯
大数活动
服务超市
文章专题
出海平台
流量密码
出海蓝图
产业赛道
物流仓储
跨境支付
选品策略
实操手册
报告
跨企查
百科
导航
知识体系
工具箱
更多
找货源
跨境招聘
DeepSeek
首页
>
DeepSeek坦承不如Opus,百万Token免费背后是一场工程宣言
>
DeepSeek坦承不如Opus,百万Token免费背后是一场工程宣言
AI驱动数字化转型
2026-04-24
6
导读:我们看到一家技术公司在浮躁时代里,选择了一条更安静也更艰难的路。这条路始于对工程美学的极致追求,立足于对开发者需求的深刻洞察,通向一种罕见却强大的自信。
喧嚣之外,
DeepSeek
的工程长征
AI圈,数字是唯一的
货币
。参数量、Token
长度
、跑分榜单,每项指标像军备竞赛的刻度尺,反复拉高,反复宣传。
但4月24日,DeepSeek V4的发布显得异常安静。
最大的变化不在某个数字上。V4-Pro和V4-Flash,旗舰版和轻量版,全部标配百万Token上下文。没有等级划分,没有价格阶梯。过去被视为昂贵特权的"长窗"能力,一夜之间成了免费的基础设施。
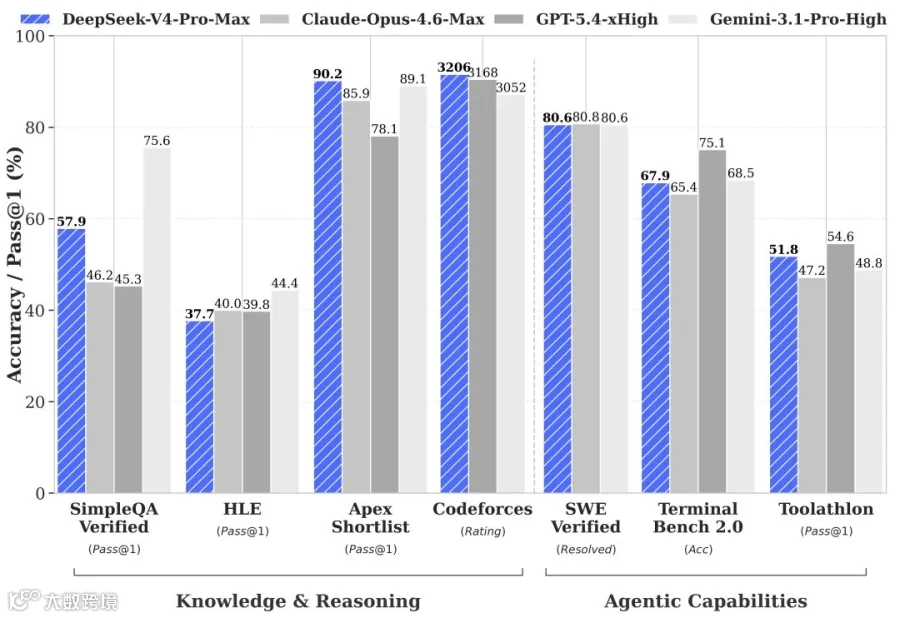
更特别的是公告里的那句话。Agentic Coding测试中,DeepSeek坦承V4-Pro体验优于Claude Sonnet 4.5,交付
质量
接近Opus 4.6的非思考模式。但一旦Opus 4.6开启深度思考,V4-Pro"仍落后于Opus 4.6"。
在国内厂商的发布会辞藻里,这种主动承认差距的表态几乎从未出现。
不诱于誉,不恐于诽。率道而行,端然正己。
这句古训,或许是理解DeepSeek此刻行为最好的注脚。这并非一次寻常的产品发布,更像一场工程哲学与商业战略的无声宣言。
长上下文的"供给侧改革"
百万Token上下文意味着什么?
V4之前,长上下文是奢侈品。无论是
OpenAI
、Anthropic还是
Google
,长上下文窗口都与更高价格直接挂钩。开发者必须像精打细算的厨师,小心翼翼地分割输入,设计复杂的RAG管道,生怕超出预算或撞上性能天花板。
这种"节制"催生了大量工程技巧,也构成了应用创新的无形枷锁。整个行业默认,与大模型交互必须是碎片化的、经过预处理的。
DeepSeek V4直接宣布,那块最贵的成本,由平台方通过技术优化吸收了。
为什么能做到?不是简单的价格战,而是对注意力机制的深度改造。传统Transformer中,计算复杂度与上下文长度的平方成正比,即O(L²)。上下文翻倍,计算量和显存暴增四倍,这正是长上下文昂贵的根本原因。
V4引入的新机制,结合Token级压缩与自研DSA稀疏注意力,从根本上重塑了成本曲线。通过"先筛选后计算"的逻辑,模型无需关注每个Token,而是用轻量级"闪电索引器"快速定位最相关的少数Token,再对稀疏集合执行精确计算。复杂度从O(L²)降至接近线性O(L×k),其中k是远小于L的小常数。
技术文档显示,128K长度推理中,
速度
提升了8.3倍,显存占用降低67%。
这并非凭空出现的魔法。从更早的NSA原生稀疏注意力到如今的DSA,DeepSeek一直在"压榨"算力。NSA侧重硬件协同,从预训练开始原生支持稀疏计算。DSA则在算法层面做更精细的筛选。
正是这些无人关注的底层优化,才支撑得起"百万Token免费"的商业决策。一种典型的工程思维:问题并非无法解决,只是解法还不够经济。如果从根源上降低成本,新模式和新应用便会自然涌现。
当代码库变成一个"字符串"
百万Token上下文普及,冲击最大的是哪个领域?
是软件开发。
以前,AI编程助手处理复杂代码库时,像个戴着眼罩的拼图玩家。它能看到手边的几块碎片,却无法感知整个拼图的全貌。跨文件依赖、全局状态管理、复杂的继承关系,都超出了理解范畴。
开发者不得不借助RAG,将代码库切片、向量化、存入数据库,再通过检索来"喂养"模型。流程繁琐,信息在检索过程中必然有损失。
V4展示了另一种可能:将整个中等规模代码库(约50万行)一次性塞进上下文,让模型直接在"工作记忆"中完成理解、分析和重构。
带来的工作流变革是颠覆性的。
一家头部互联网企业的研发安全团队,基于V4实现了全量代码库自动化安全审计。传统分块处理加RAG方案,审计一个仓库需要近4小时。利用V4的全局上下文能力,整个过程缩短至12分钟。高危漏洞检出率提升至98.7%,漏报率和误报率大幅降低。
为什么差异如此大?许多安全漏洞并非孤立存在于单行代码中,而是源于多模块、多文件的不安全交互。只有当AI能"看见"完整调用链时,才能精准识别这类"上下文漏洞"。
另一家电商公司使用V4进行全量代码评审。AI不仅100%检出代码规范问题,还能发现人工评审容易忽略的逻辑缺陷。需求开发周期缩短了40%。
从"检索片段"到"通读全文",看似简单的变化,跨越了AI编程能力的巨大鸿沟。AI从一个"代码片段补全
工具
",开始扮演"系统分析师"和"架构师助理"的角色。
开发者可以直接提问:重构支付模块需要修改哪些API?评估对订单系统的影响。分析这个开源项目的依赖关系,画出核心模块交互图。
过去需要资深工程师数天的任务,现在被压缩到分钟级。代码库,正在从复杂的工程结构,降维成AI可以完整读写的"长字符串"。
"我们还不如Opus 4.6"
再看看那罕见的坦诚。
国内AI发布会通常是性能的"秀肌肉"舞台。各家热衷于各类跑分榜登顶,用精心设计的图表证明"全面超越"。主动披露与顶级模型的差距,具体到某个功能点的不足,几乎不存在。对模型局限性的讨论往往语焉不详。
DeepSeek打破了这个默契。
这背后是什么逻辑?
首先,极度务实。开发者是AI模型最核心也最挑剔的用户。浮夸的宣传在实际API调用和项目集成中都会迅速证伪。与其用营销辞藻建立脆弱预期,不如用诚实数据和清晰边界赢得长期信任。承认在"深度思考"上落后,恰恰为开发者提供了一份真实可用的"选型指南"。
其次,深刻的战略自信。真正的自信不是在所有指标上排第一,而是清楚自己的核心优势在哪里,知道未来的路径。DeepSeek传递的信号很清晰:
长板在于通过底层工程创新,将极限性能普惠化,构建庞大的开发者生态。它选择的战场,是成本、效率和工程落地性。
承认短板,恰恰是为了聚焦长板。
这种坦诚也为行业树了标杆。AI的进步不应该是营销数字的堆砌,而应建立在可复现、可验证的工程实践上。当领跑者开始正视差距,并将其作为公开目标时,行业的焦点才会从"宣传战"回归到"技术战"。
这大概就是"
端然正己
"的现代诠释。在喧嚣市场里保持清醒,不因赞誉自满,不因落后回避。专注于自己的路,用工程的语言,而非市场的辞藻,与世界对话。
技术的长征,没有终点
将百万Token从一个昂贵的"特性"变成免费的"标配",DeepSeek没有结束战斗,而是开启了新篇章。当上下文不再是瓶颈,竞争自然会转移到更高维度:长上下文的信息提取精度、多步推理准确性、复杂指令遵循能力。
DeepSeek坦承与Opus 4.6在深度思考上的差距,既是终点,也是起点。它指出了下一阶段需要攻克的山峰。
在今天,我们看到一家技术公司在浮躁时代里,选择了一条更安静也更艰难的路。这条路始于对工程美学的极致追求,立足于对开发者需求的深刻洞察,通向一种罕见却强大的自信。
敢于在聚光灯下,直面自己的不完美。
【声明】内容源于网络
0
0
AI驱动数字化转型
专注AI,促进智造行业数据衍生,服务智能制造企业的数字化、智能化,聚焦大模型私域部署、大模型微调、数据清洗、AI模型训练、私域知识库及agent技术延展等。行业智能,落地为先。
内容
974
粉丝
0
关注
在线咨询
AI驱动数字化转型
专注AI,促进智造行业数据衍生,服务智能制造企业的数字化、智能化,聚焦大模型私域部署、大模型微调、数据清洗、AI模型训练、私域知识库及agent技术延展等。行业智能,落地为先。
总阅读
3.6k
粉丝
0
内容
974





 AI驱动数字化转型
AI驱动数字化转型