
-推荐关注-
-正文-
0.下载LM Studio:
1.查找/下载模型
2.查看已经下载的模型
3.聊天
4.配置服务端,供其他程序调用
4.1 支持的接口:
4.2 使用postman调用接口
LM Studio 是一款专为本地运行大型语言模型(LLM)而设计的桌面应用程序,其主要作用是简化用户在本地环境中部署和使用这些先进的人工智能模型的过程。LM Studio 允许用户无需互联网连接即可在本地设备上运行复杂的语言模型,从而保障数据隐私和处理速度
LM Studio 的优点包括:
-
离线运行能力:用户可以在没有网络连接的情况下使用该平台,确保数据隐私和安全性。
-
用户友好的界面:LM Studio 提供直观的操作界面,使得即使是 AI 领域的新手也能轻松上手。
-
多平台支持:LM Studio 支持 Windows、Mac 和 Linux 系统,兼容多种硬件配置
-
广泛的模型兼容性:LM Studio 支持从 Hugging Face 等流行仓库下载多种流行的 LLM 模型,如 Llama、MPT 和 StarCoder 等。
-
高性能和优化:LM Studio 采用了先进的计算架构和高效的算法优化,确保模型在本地设备上的高效运行。
-
隐私保护:LM Studio 不收集、监控或存储用户数据,所有操作都在本地完成,避免了云端数据传输的风险。
-
灵活的使用方式:用户可以通过内置聊天界面或本地服务器调用模型 API,灵活地与模型进行交互,并且可以同时运行多个模型。
0.下载LM Studio:
https://lmstudio.ai/
1.查找/下载模型
点击左侧的“发现”按钮,打开搜索页面
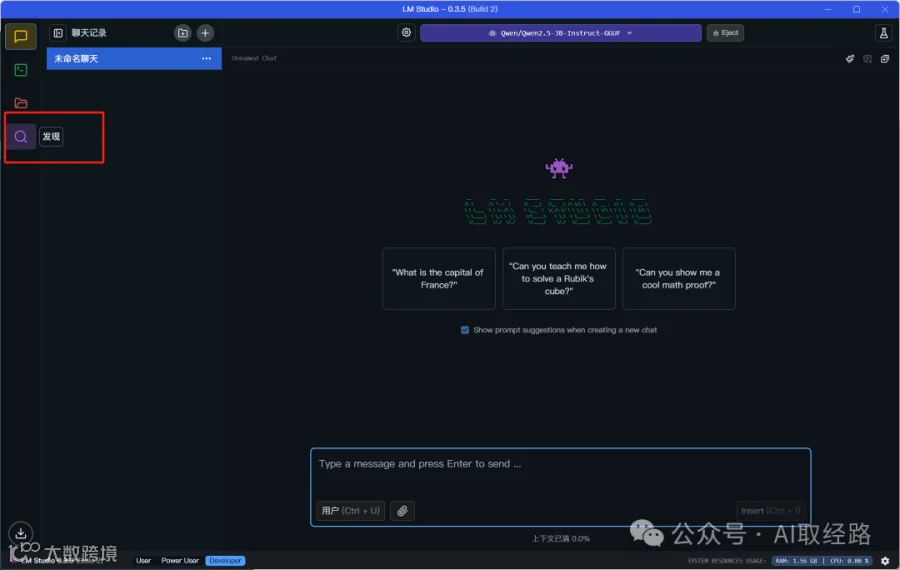
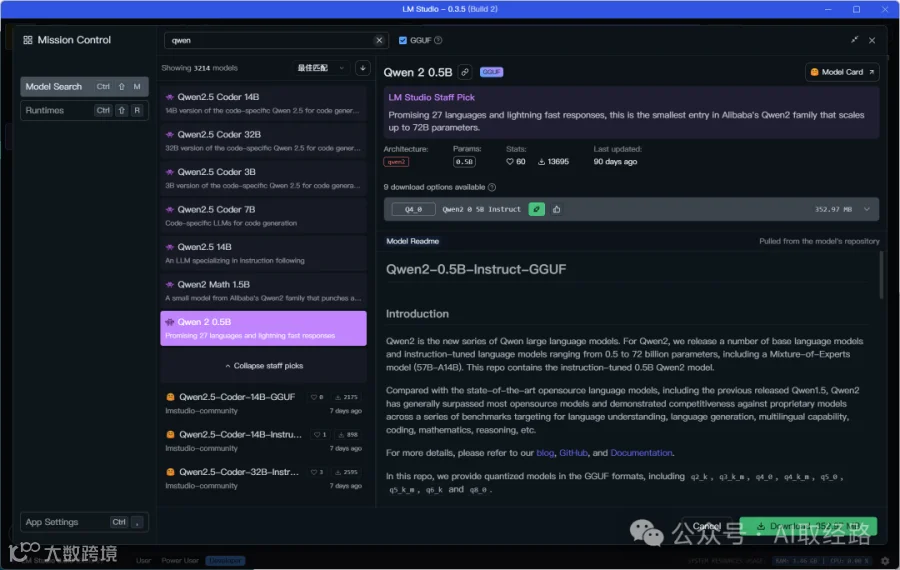
输入关键字,寻找想要下载的模型,这边找一下Qwen的模型,找到Qwen2 0.5B的模型,
模型的名称为:Qwen2-0.5B-Instruct-GGUF
0.5B的模型是千问系列最小的模型,对于设备的要求较低
模型名称的含义:
如
qwen2.5-0.5b-instruct-q5_k_m.gguf
qwen2.5: 模型的名称,千问2.5
0.5b: 参数数量,b表示billion,0.5B表示5亿参数,参数数量较少,通常是小型模型,适合资源受限的设备或较小规模的任务,可以用在移动设备、嵌入式系统
Instruct: 经过指令(问答)优化微调,让模型更擅长遵循用户给出的明确指令,避免不必要的冗余或不相关内容
Q5_K_M: 是一种让模型更小、更快、更省资源的技巧,简单理解为“压缩+优化”的方法;Q5比Q3信息表示能力更强,通常能够保留更多模型的原始精度
GGUF: 一种大模型文件格式,原始的大模型预训练结果经过转换后变成GGUF格式可以更快地被载入使用,也会消耗更低的资源。
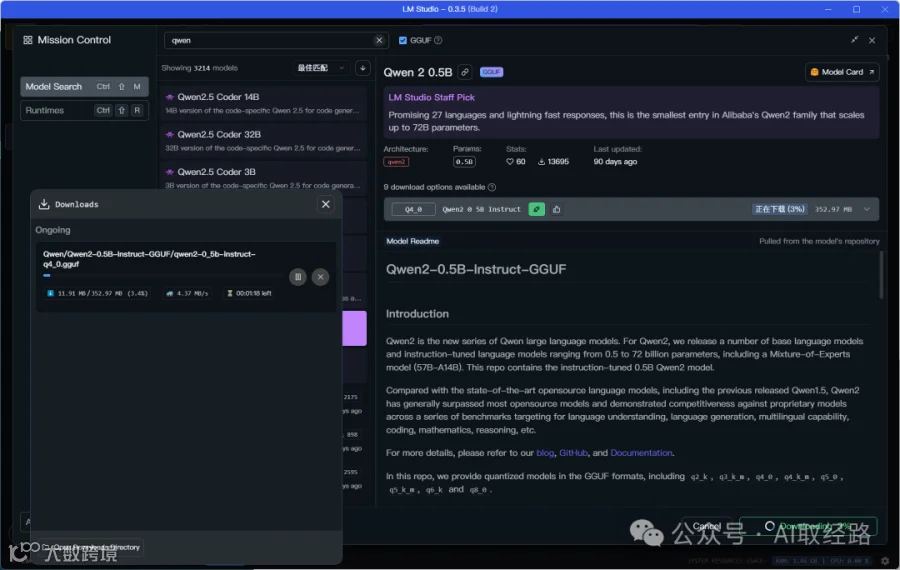
点击右下角Download开始下载
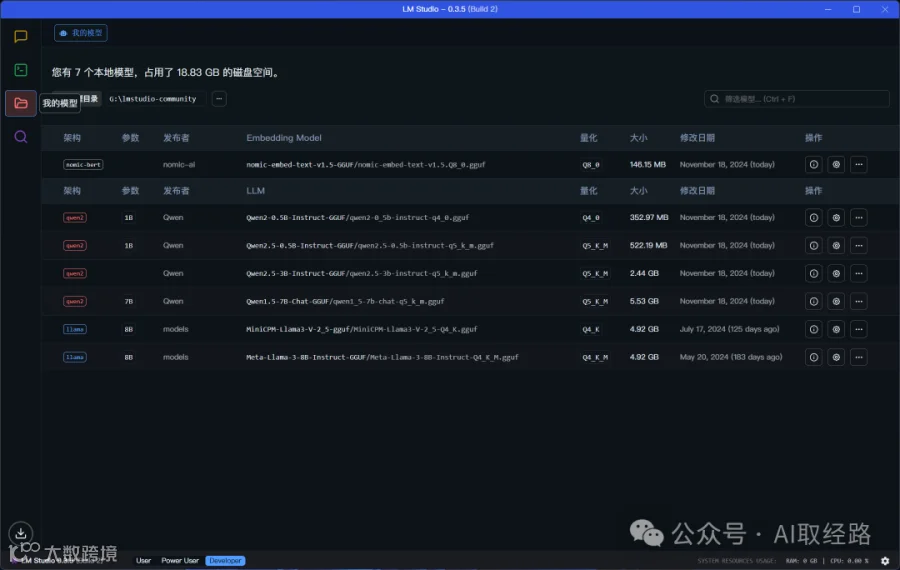
2.查看已经下载的模型
点击“我的模型”按钮,可以找到当前已经下载的所有模型
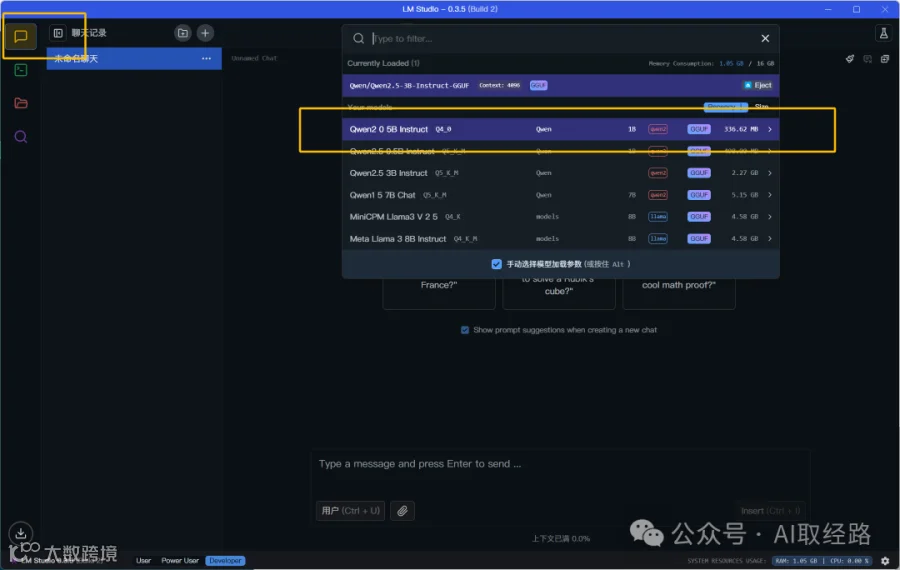
3.聊天
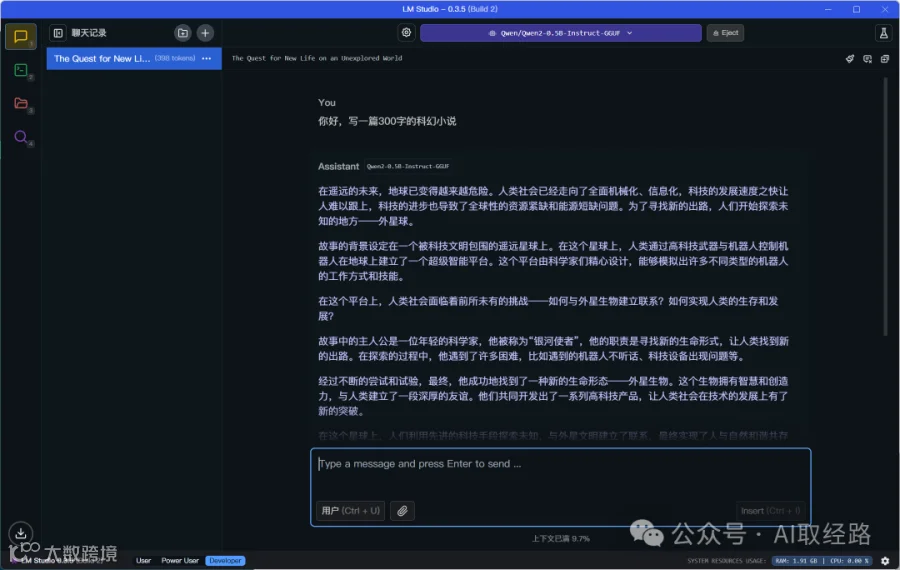
点击“聊天”页面,选择刚才下载的模型:Qwen2-0.5B-Instruct
随便说点什么,由于使用的0.5B参数的小模型,速度非常快
4.配置服务端,供其他程序调用
点击“开发者”按钮,配置服务端
1.选择一个已有的模型,如刚下载的Qwen2-0.5B-Instruct
2.启动服务
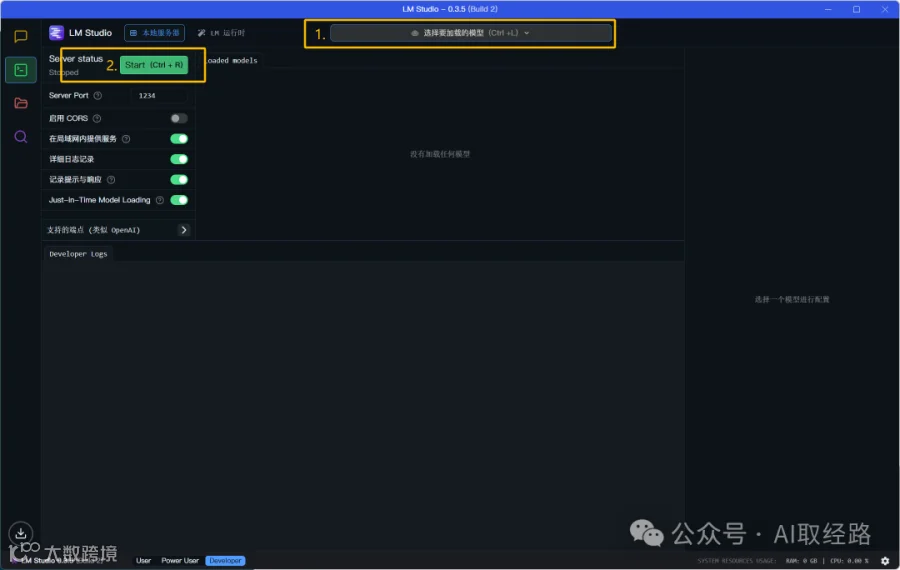
服务启动完成
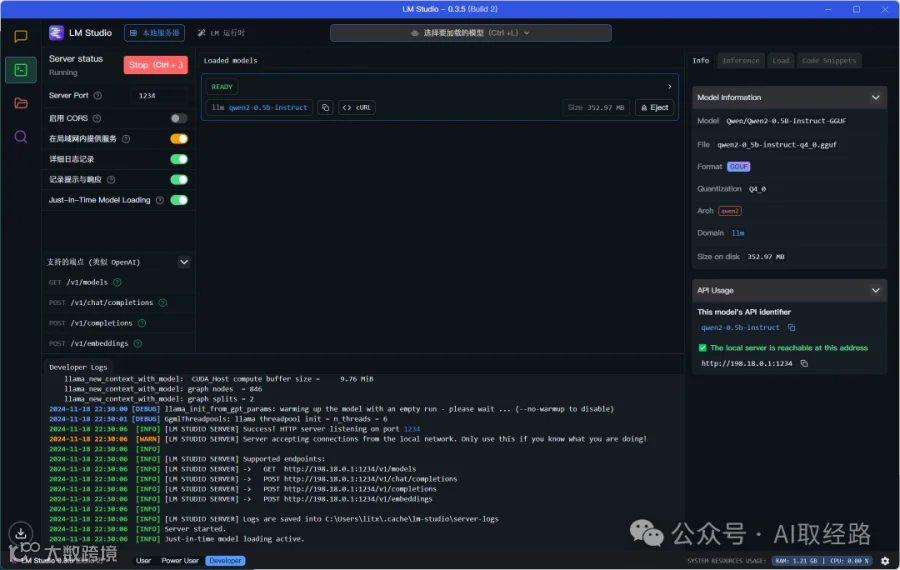
-
Server Port: 设置本地服务器使用的网络端口。默认情况下,LM Studio 使用端口 1234。如果该端口已被占用,您可能需要更改此设置
-
启用 CORS: (跨源资源共享)允许您访问的网站向 LM Studio 服务器发起请求。从网页或 VS Code / 其他扩展程序发起请求时可能需要启用 CORS
-
在局域网内提供服务: 是否允许来自网络中其他设备的连接。如果未选中,则服务器仅监听本地主机。
-
记录提示与响应: 是否在本地服务器日志文件中记录提示和/或响应。
-
Just-in-Time Model Loading: 启用后,如果请求指定了一个未加载的模型它将被自动加载并使用。此外,"/v1/models"端点还将包括尚未加载的型号。
4.1 支持的接口:
GET http://198.18.0.1:1234/v1/models: 列出当前加载的模型
POST http://198.18.0.1:1234/v1/chat/completions: 聊天补全。将聊天历史发送给模型以预测下一个助手响应
POST http://198.18.0.1:1234/v1/completions: 文本补全模式。根据给定的提示预测下一个token(或多个)。注意:OpenAI 认为此端点已'弃用'。
POST http://198.18.0.1:1234/v1/embeddings: 文本嵌入。为给定的文本输入生成文本嵌入。接受字符串或字符串数组。
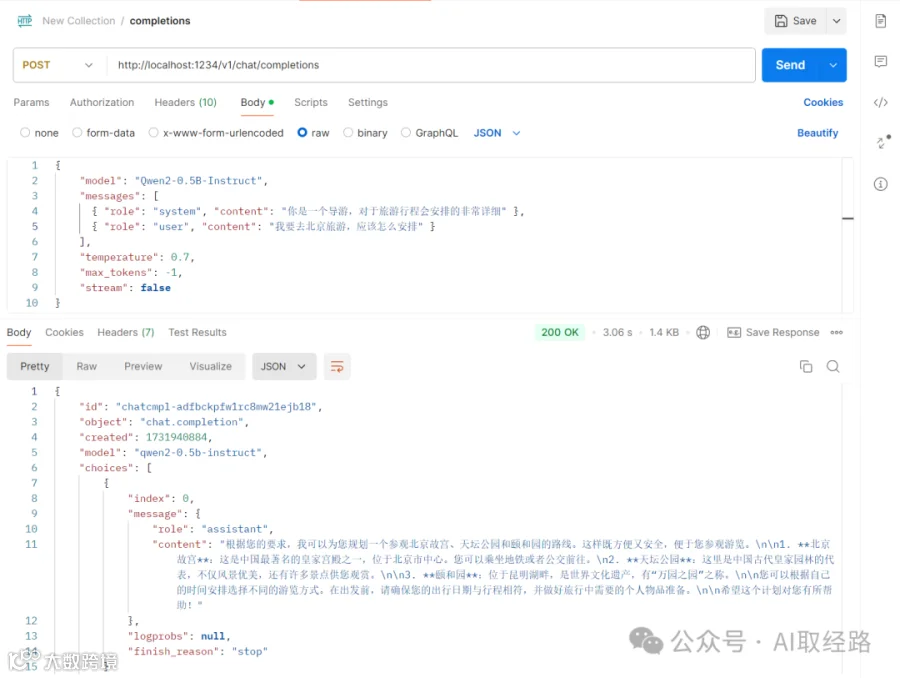
4.2 使用postman调用接口
请求聊天接口:http://localhost:1234/v1/chat/completions
请求内容:
{
"model": "Qwen2-0.5B-Instruct",
"messages": [
{ "role": "system", "content": "你是一个导游,对于旅游行程会安排的非常详细" },
{ "role": "user", "content": "我要去北京旅游,应该怎么安排" }
],
"temperature": 0.7,
"max_tokens": -1,
"stream": false
}
返回:
{
"id": "chatcmpl-adfbckpfw1rc8mw21ejb18",
"object": "chat.completion",
"created": 1731940884,
"model": "qwen2-0.5b-instruct",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": "根据您的要求,我可以为您规划一个参观北京故宫、天坛公园和颐和园的路线。这样既方便又安全,便于您参观游览。\n\n1. **北京故宫**:这是中国最著名的皇家宫殿之一,位于北京市中心。您可以乘坐地铁或者公交前往。\n2. **天坛公园**:这里是中国古代皇家园林的代表,不仅风景优美,还有许多景点供您观赏。\n\n3. **颐和园**:位于昆明湖畔,是世界文化遗产,有“万园之园”之称。\n\n您可以根据自己的时间安排选择不同的游览方式。在出发前,请确保您的出行日期与行程相符,并做好旅行中需要的个人物品准备。\n\n希望这个计划对您有所帮助!"
},
"logprobs": null,
"finish_reason": "stop"
}
],
"usage": {
"prompt_tokens": 32,
"completion_tokens": 150,
"total_tokens": 182
},
"system_fingerprint": "qwen2-0.5b-instruct"
}
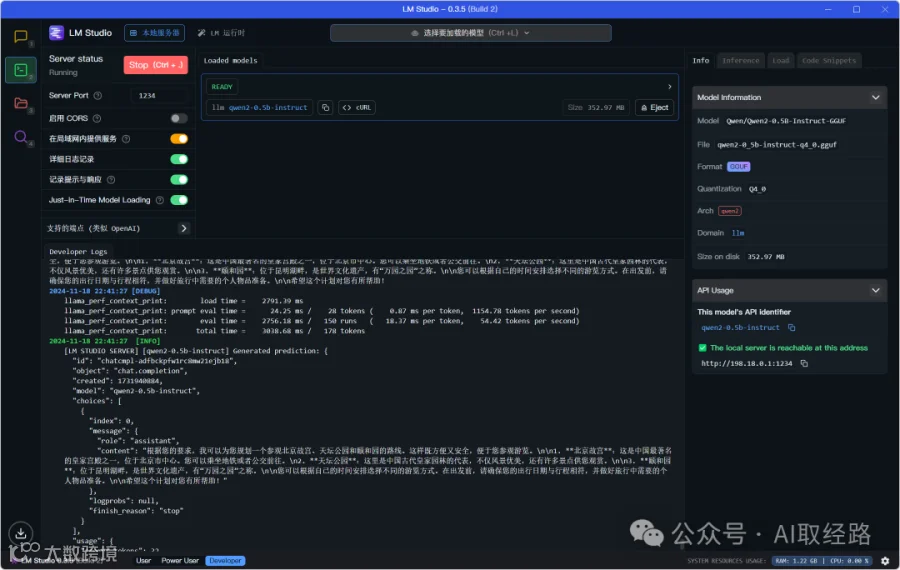
LM Studio后台输出调用日志:
往日文章:
--END--