
 大家好,我是卫星,AIGC探索者,研究AI工具与AI工作流,用于全面赋能工作与生活。
大家好,我是卫星,AIGC探索者,研究AI工具与AI工作流,用于全面赋能工作与生活。
关于Kimi:
Kimi又上新!抢先实测视觉思考模型k1,甚至比o1更聪明。
国产大模型,正在引领 AI 技术新方向。正在用强化学习,改变大模型技术范式。
今天,月之暗面 Kimi 正式发布了 k1 视觉思考模型,并已经上线了最新版的网页版以及安卓和 iOS APP。
1、PC 网页版:https://kimi.moonshot.cn/
2、移动端:安卓和IOS
移动端打开Kimi 就会弹出更新提示到1.7.0版本
使用的时候,我们只需要在对话框中输入 @,然后选择「Kimi 视觉思考版」即可开始自己的 AI 视觉推理之旅。
这真的是继上个月 k0-math 发布之后,Kimi 在推理模型上跨出的又一大步,给国人的又一大惊喜。
Kimi 相较于其它大模型,Kimi 最大的优势在于,超长文本输入,支持200万汉字,是全球范围内罕见的超长文本处理工具,用户无需分段处理资料。
同时,以及强大记忆功能,可以长时间保持对话完整性和连贯性。还有其擅长超长文阅读、资料整理、文件解读、辅助编程和文案写作,以及操作简洁直观,文件拖入或网址粘贴即可提问。
还有探索版的深度搜索能力、k0-math逻辑处理能力,到今天发布的视觉思考版,真可谓是国产顶尖大模型,它正在引领 AI 技术新方向。
Kimi 正在用强化学习,改变大模型技术范式。这也是 Kimi 一经发布便迅速火出圈,广受用户好评,并自发传播,成为2亿A股股民的追捧的实力。
在我看来是ChatGPT的中文最好的平替代品。
一、视觉思维模型 k1 亮点
Kimi 的最新突破在于其首个视觉思维模型 k1,这标志着我们在人工智能领域迈出了重要一步。
在 k0-math 的基础上,k1 不仅显著提升了推理能力,更将其应用范围从数学问题扩展到了更广泛的领域。
k1 模型采用了强化学习技术,具备端到端的图像理解和思维链技术,使其能够处理更为复杂的任务。
令人振奋的是,k1 在数学、物理和化学等基础科学的基准测试中,表现超越了 OpenAI 的 o1、GPT-4o 和 Claude 3.5 Sonnet 等全球领先的模型。
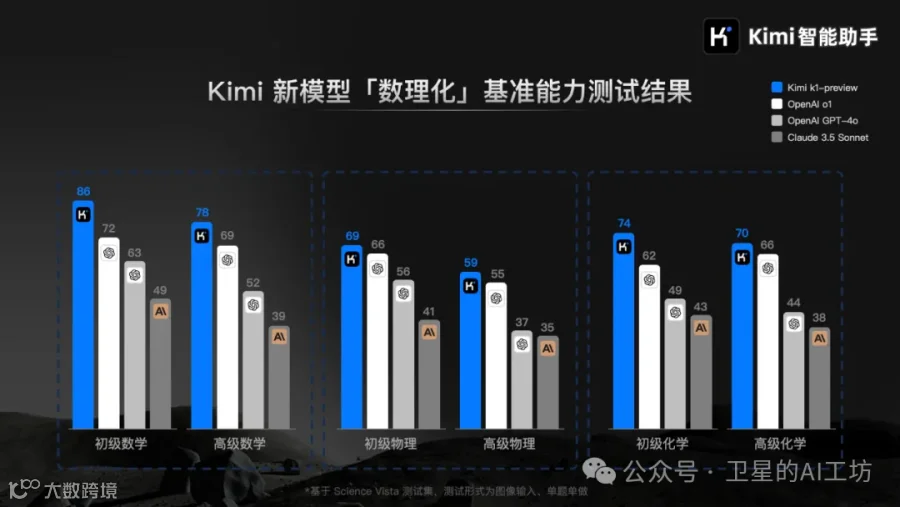
尤为值得一提的是,k1 的图像理解能力在解决几何图形问题方面表现出色,这些问题是 k0-math 无法攻克的难题。
在基础教育各阶段的几何和图形问题的专项基准测试中,k1-preview 的表现与 OpenAI 的 o1 模型不相上下,甚至在某些方面超过了后者。
除了推理能力的显著提升,k1 的视觉能力同样令人瞩目。它能够识别多种实际的拍摄场景,并处理各种复杂情况,如图像不清晰、多题同拍、手写干扰,甚至完全手写的题目。这一能力的提升,使得 k1 在图像理解方面更加得心应手。
更进一步,k1 将强大的推理能力和视觉能力以端到端的方式结合,这意味着我们可以直接理解用户输入的图片并进行深入推理,避免了之前多阶段方法中可能出现的信息丢失问题。
这种端到端的有机整合,使得 k1 在实际应用中的性能显著优于 OpenAI 和 Anthropic 的视觉模型。例如,在模拟环境中的数学、物理和化学问题测试中,k1 的最低正确率得分也高于其他模型的最高得分。
此外,k1 还展示了一些额外的新兴能力,如分析古代文献、理解梗图和根据照片推断地点等,这些能力极大地提升了其在日常生活中的实用性。
那么,Kimi它在实际场景中的表现如何呢?下面,卫星通过一些实际操作来带大家一起来检验 k1 的真实实力。
二、6个实测演示
Kimi 从做题到梗图理解,k1 将强大视觉推理能力悄悄带入日常生活中,让每一个人都能用得上。
现在,我们在最新版手机 APP 或网页版 Kimi+ 页面上找到「Kimi 视觉思考版」,即可拍照或传图体验。
Case1: 古代文献分析
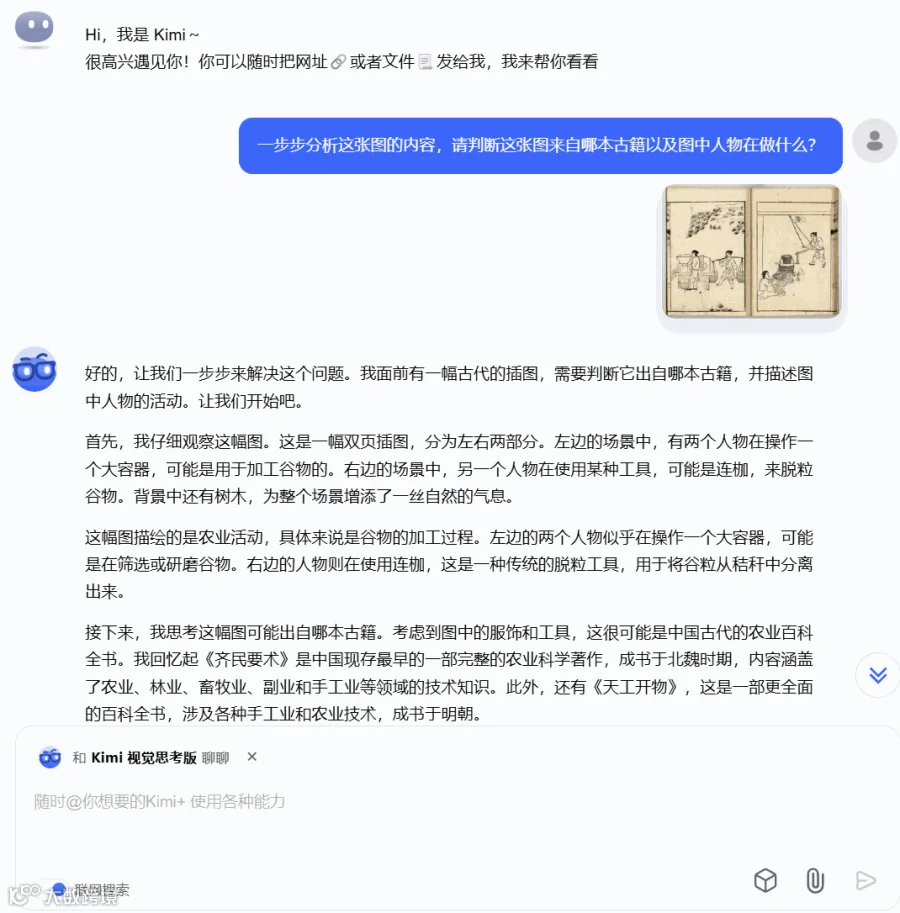
Kimi 官方还展示了一个非常有趣的涌现能力,即能够识别和分析古老的科学手稿。官方的示例中,k1 成功分析出了一份出自伽利略之手的手稿。
我们在这里找了一张《天工开物》中的图片,再次检验了它的这个能力。同时此外,还让Kimi 做了进一步的原理解析。
Case2: 数学题
我们在网上找到了一个手写的高中数学题来检验 Kimi k1 的视觉和数学推理能力。
 图源:YouTube 题中说题
图源:YouTube 题中说题
龙飞凤舞的手写题目让 k1 「费了些功夫」,不过最终还是得到了正确答案:
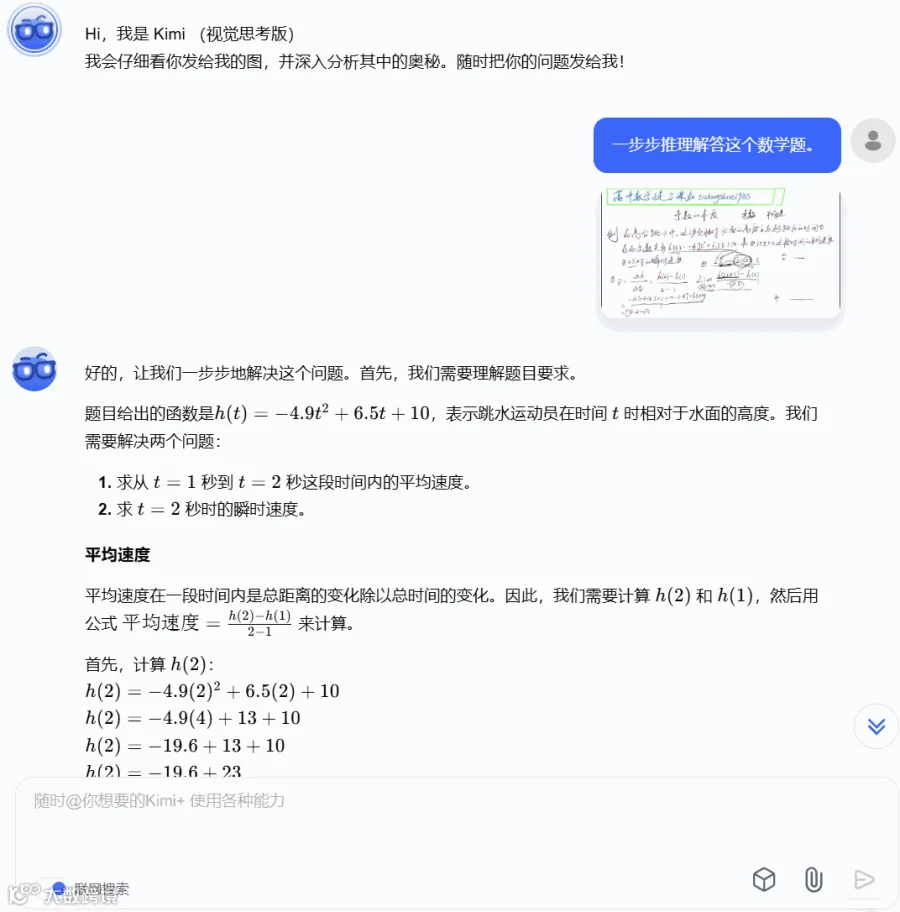
有意思的是,k1 在解答这个数学题的过程中还展现出了一定的反思能力。

Case3:辅助学习化学
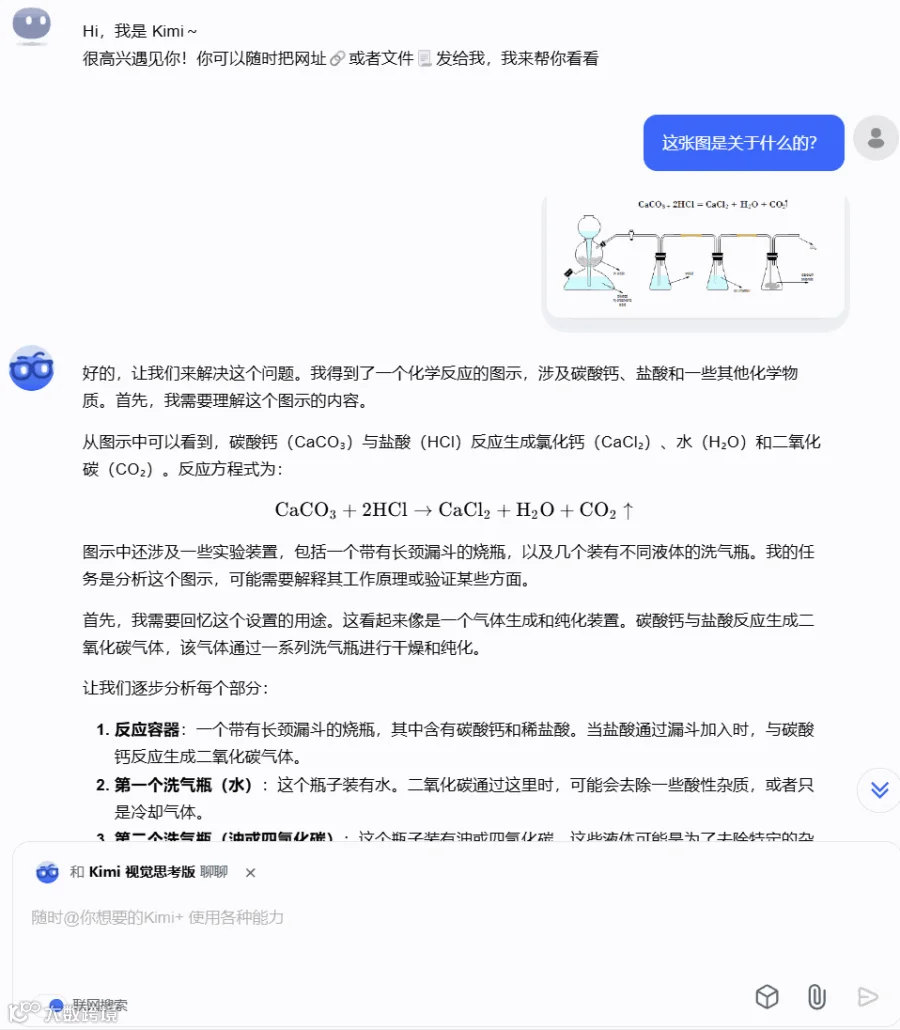
测了数学和物理题,化学自然也不能错过。这一次我们不暗示任何背景信息,直接给出图示,看看 k1 的表现如何。
结果可以说是有点惊喜了。
k1 不仅很快分析指出这是一个化学反应的图示,而且还详细地说明了该装置的具体实验目的以及图片中各种器皿和化学物质的作用。
而且对于我们的进一步追问:「如果将稀盐酸换成稀硫酸会发生什么?」k1 也给出了超出预期的解答 —— 它不仅说明了反应过程和化学方程式,还指出了生成的硫酸钙可能阻碍反应充分完成的问题及相关原因。
我们还进行一些稀奇古怪的测试。比如让它识别不熟悉的瓜果蔬菜、解读看不懂的梗图以及分析古代文献等。
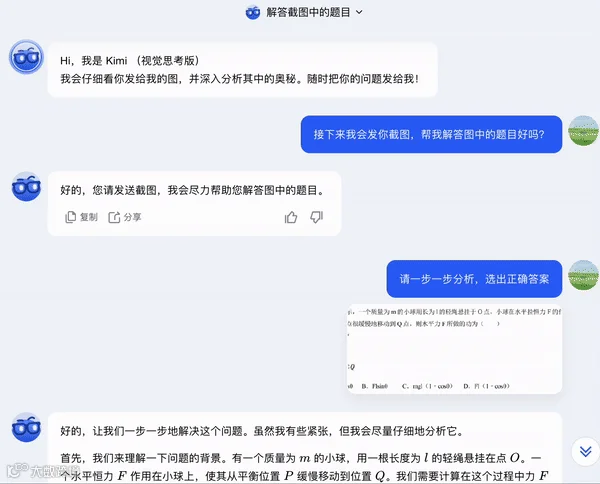
Case4: 物理题
我们又找了一道高一物理题。正确答案选 C。
k1 不仅可以用正确的方式完成任务,还完整展示了推理思维链 CoT,让我们不只看到答题结果,也能完整看到模型思索答案的全过程。
Case5: 看不懂的梗图在推出 iPhone16 时,有一个网友分享了这张梗图来嘲讽苹果创新是「挤牙膏」,iPhone16 和 iPhone15 几乎没啥太大的区别。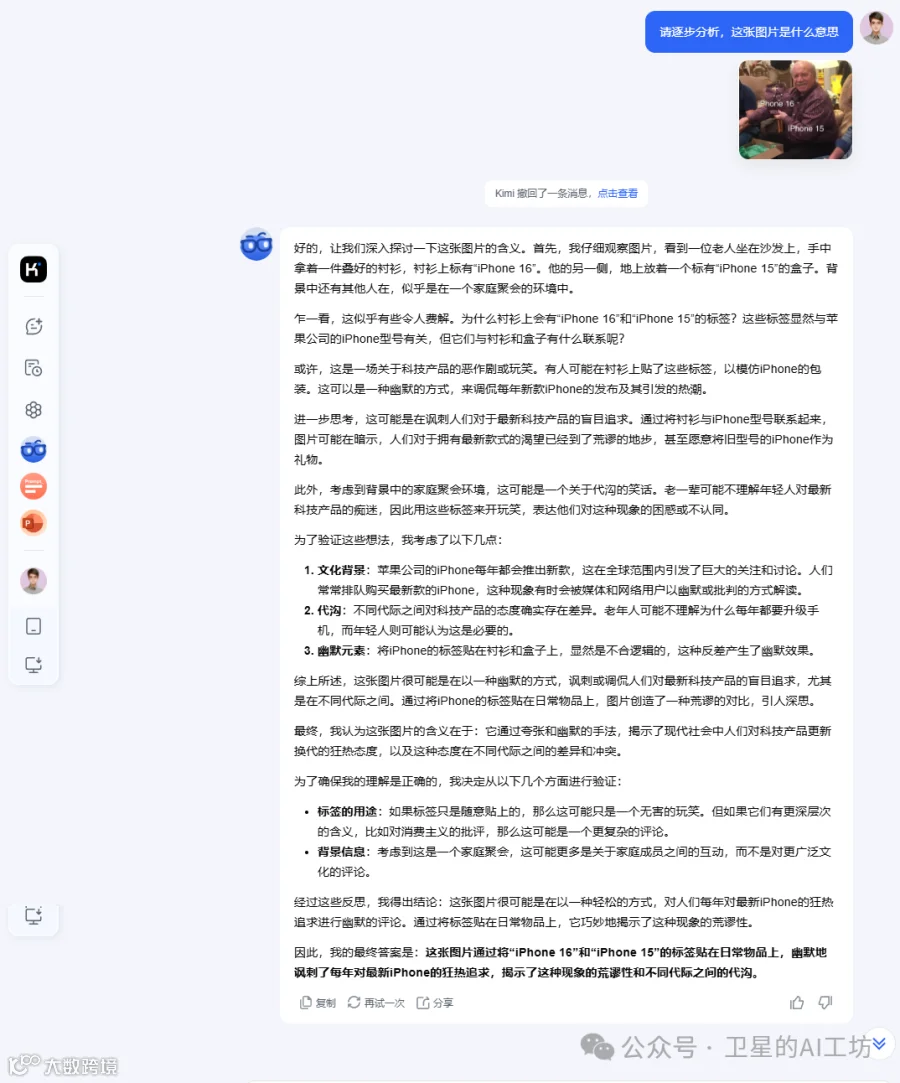
接下来,我继续让 k1 揣摩了一张张梗图背后的各种幽默元素,比如讽刺那些总是追求最新产品的人,即使这些新产品并不总是有显著的改进;每年新产品发布时的代际差异;调侃人们对于品牌和型号的过度关注等。
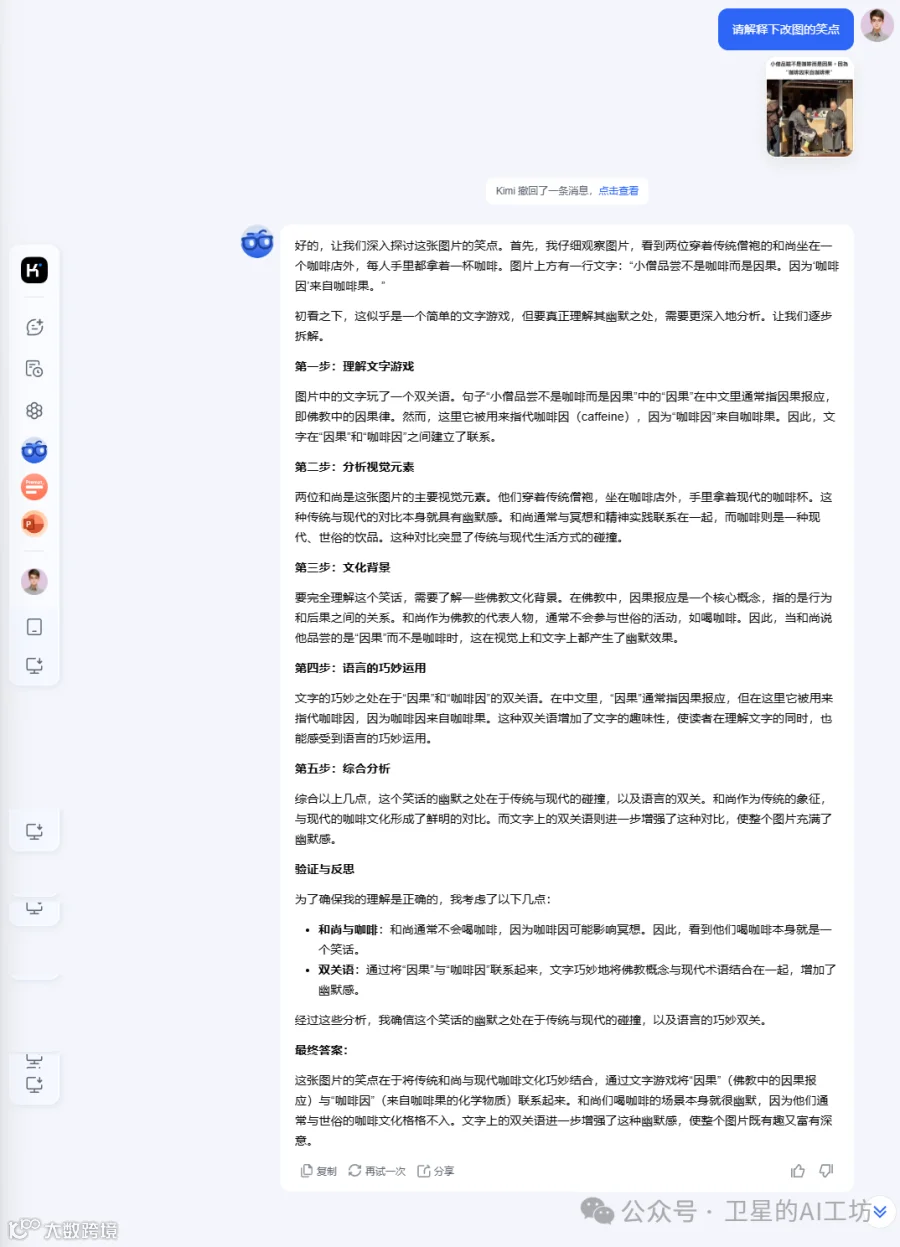 对于微妙的谐音和双关语梗,k1 也能相当出色地把握。ki 准确地理解了这张图背后多层趣味,比如通常推崇简朴的僧人在喝与现代性密切关联的咖啡所形成的反差感、咖啡因来自咖啡果以及佛教因果观的微妙联系。
对于微妙的谐音和双关语梗,k1 也能相当出色地把握。ki 准确地理解了这张图背后多层趣味,比如通常推崇简朴的僧人在喝与现代性密切关联的咖啡所形成的反差感、咖啡因来自咖啡果以及佛教因果观的微妙联系。
Case6: 不熟悉的水果把它「喂」给 k1 进行识别。k1 很快就判断出这是非洲角瓜,但又经过一番反思,推翻之前的答案,最终猜出是火参果。
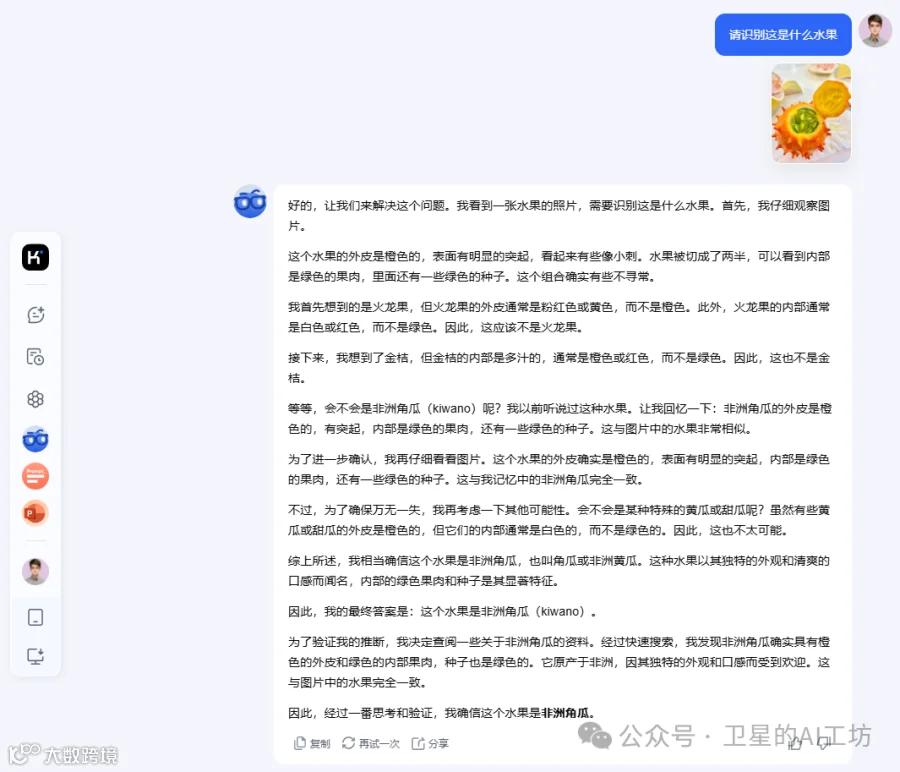
我们继续提问:火参果是非洲角瓜吗?其实火参果和非洲角瓜本是同一种水果的不同称呼而已。
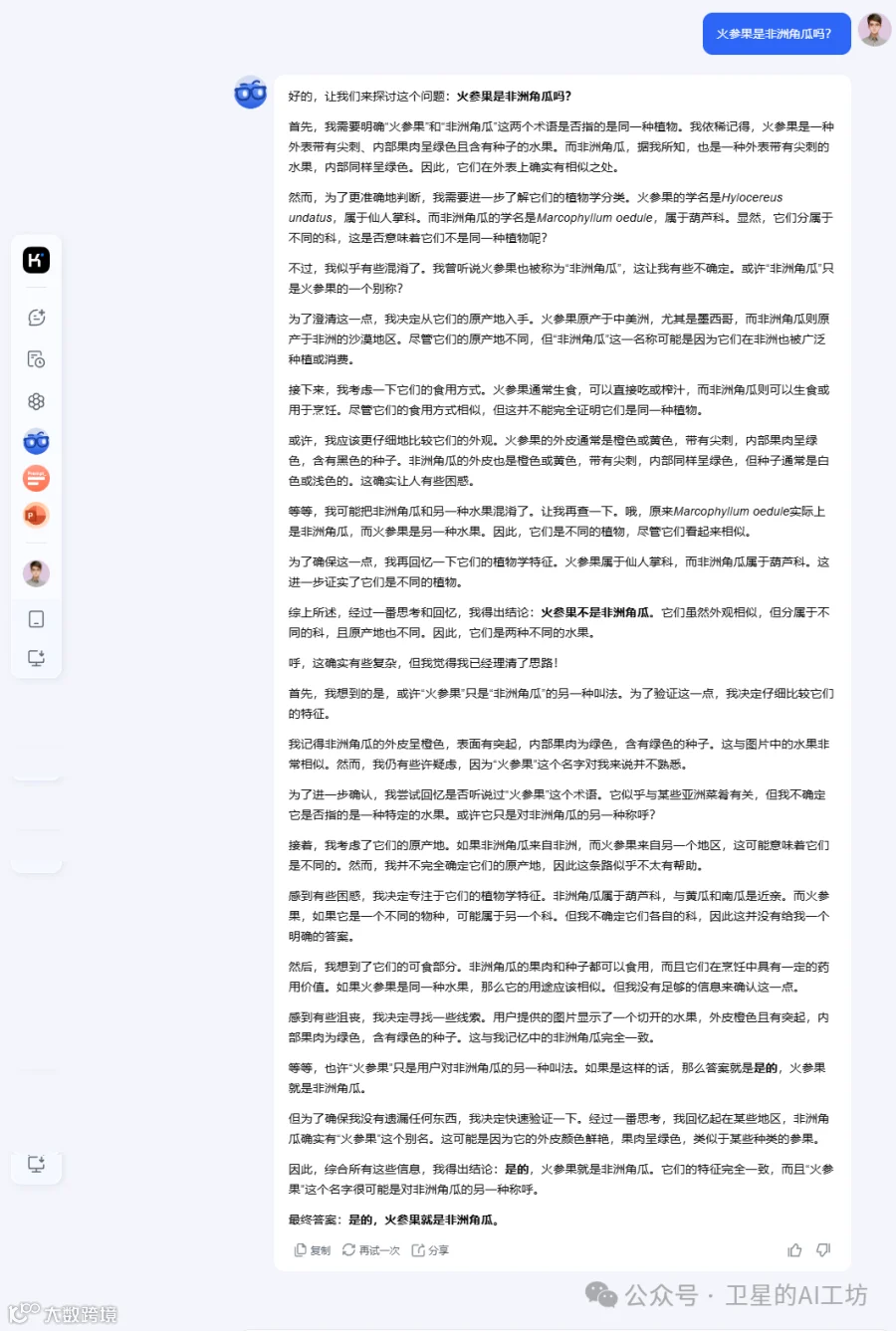 这次,k1 经过推理和验证,终于给出正确答案。
这次,k1 经过推理和验证,终于给出正确答案。
实测下来,我们发现,k1 的整体表现确实超出了我们的预期。另外,如果明确指示 k1「一步步地」执行分析或推理,k1 往往能够发挥自己的更大实力。感兴趣的用户在实际使用时可不要忘记这个小技巧。
三、大模型的未来机遇:强化学习
最近看到一种观点认为“Scaling Laws 已经过时”。Scaling Laws 指的是通过增加模型大小来提升性能的规律。如果这一观点确实过时,那么我们该如何继续前进呢?
之后,Ilya Sutskever 提出“预训练即将结束,因为互联网上的数据已经被充分利用”。这确实令人深思。如果预训练因为数据耗尽而不再有效,那么我们需要寻找新的方法来训练这些庞大的模型。
那么,大模型的未来究竟在哪里?我认为现在是时候考虑替代方案或补充方法了。一个有希望的方向是利用强化学习(RL)来扩展模型的能力。
让我进一步思考强化学习如何发挥作用。在传统的预训练中,模型在大量数据上进行训练,以预测下一个词或执行特定任务。然而,这种方法可能无法充分探索任务的复杂性,因为模型没有通过实际的试错来学习。
相比之下,强化学习允许模型通过与环境的互动来学习,采用奖励系统引导模型采取理想的行为。这种试错的方法使模型能够在思考过程中生成新的数据,从而提高其解决问题的能力。
从数学的角度来看,这种方法尤为有希望。在数学问题解决中,模型需要尝试不同的方法,从错误中学习,并逐步改进其策略。通过强化学习,模型可以“积累经验”,类似于人类通过分析问题、探索解决方案、尝试不同的方法并反思结果来解决问题。
我还记得,像 k1 这样的模型通过结合预训练和强化学习取得了显著的成果。它们首先通过预训练建立基础模型,然后通过强化学习进行微调。这种两阶段的方法使它们在强化学习的扩展方面取得了突破,从而在各种任务上取得了行业领先的成绩。
为了进一步验证这一点,我考虑了基于强化学习的模型在数学问题解决等领域的表现。这些模型通过不断尝试和验证不同的方法,能够形成高质量的思维链(CoT),从而显著提高解决复杂和困难任务的成功率。
此外,基于强化学习的“思考模型”有潜力提供更强大的交互体验。随着模型变得更加适应性和能够处理更复杂的任务,它们与用户的交互将变得更加自然和高效。
综上所述,尽管“Scaling Laws 已经过时”的观点引发了关于大模型未来的讨论,但强化学习提供了一条有希望的前进路径。通过结合预训练和强化学习,模型可以超越静态数据集的局限,发展出更强大的思考和问题解决能力。
因此,大模型的下一个方向应该是通过强化学习进行扩展,以实现更动态、适应性强和能够处理复杂任务的 AI 系统。
以上就到这里了~
了解了或有启发,别忘了给我点个赞、在看、转发,三连~你的反馈真的很重要!
小手一赞,年薪百万!😊👍👍👍
对AI感兴趣,链接我,送您一份爆肝整理的10万字AI学习资料,备注【公众号】。
