
大家好,我是苍何。
人刚从厦门回来,到家就被我的宝贝儿子咬了一大口。
也是,他的爸爸已经在外面一个星期了。
但这期间可可学习到不少,特别是这次厦门之行。

这次去厦门,是受了字节火山引擎的邀请,去参加他们的开发者大会。
本来以为就是去吹吹海风,听听大佬们画饼,顺便给自己的知识库充充电。
结果没想到,愣是把我整兴奋了。
特别是这个 Prompt 一站式管理产品,真有点让人欲罢不能了,忍不住想给大家分享~

他叫 PromptPilot。能通过简单交互,理解用户真实需求,自动提炼评估标准,可链接知识库,生成更好的提示词。
在 AI 时代,谁都知道提示词(Prompt)的重要性,往往是模型越强,问出好问题的正向价值就越大,好的问题能更充分发挥出模型的能力。
但现实世界中,很多高价值的问题是没有标准答案的,怎么让模型理解你的需求,服从你的产品要求,是一个将长期存在的重要实践。
而且在 Agent 开发中,Prompt 至关重要,需要让 Agent 随着用户数据自发进行改进。
比如业务上线后,就非常需要能自动抓取和分析 badcase,并自发进行提示词优化。
那这些痛点,PromptPilot 都能解决。
PromptPilot 能做什么
AI 应用开发时,我们常常无法清晰描述自己的需求和意图。事实上,用户对事物的理解,应该要在实践的过程中不断建立,不断深化。
PromptPilot 提供了两种方式,来帮助我们表达自己的真实意图。
1、可针对答案进行评论和局部修改
2、可以通过好与坏的对比,体现自己的判断,对哪一种数据的回答更满意。 PromptPilot 会比较和分析用户的偏好,猜测用户的逻辑,积累出更完整的真实意图。
逐渐建立了真实意图和标准之后,系统就能开始自动迭代,寻找更好的Prompt 版本。
AI应用上线之后,我们可以调用 PromptPilot 的 SDK,把模型的输入输出反馈回系统。
由于系统中已经记录了我们的评判标准,因此系统可以像裁判一样,自动对上线之后的模型表现进行评分,把得分很低的 badcase 和得分很高的 goodcase 不断记录下来。持续运行一段时间之后, PromptPilot 就能开启新一轮的提示词自动优化。

PromptPilot 还支持任意模型的提示词优化。无论是任意公有云上的模型、封闭部署的私有化模型、还是自主训练后的定制模型,都能支持。
最牛逼的,PromptPilot 能够调用专业知识库,解决不少的专业难题。
比如官方的这个对比视频,可以看到有了 PromptPilot 能很好的帮助模型在垂直领域实现更深入、更精准、更可信的理解与输出。
那究竟怎么使用,下面苍何用 2 个实用 case 带你沉浸式体验一下。
如何使用
首先打开网站:https://promptpilot.volcengine.com/
点击 Prompt 生成,输入需求:
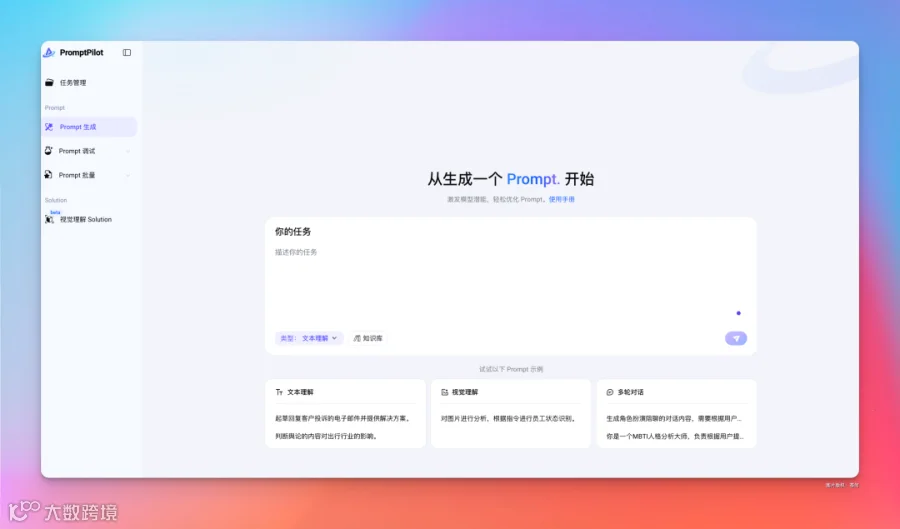
比如我的这个任务,只需要在这里描述好需求就好。
为了安全生产,你需要根据生产车间的图片,判断生产车间是否存在违规操作设备和未佩戴安全帽的情况,需要给出违规类别。 这是个常用的质检巡检任务,需要大模型理解图片并做风险识别。
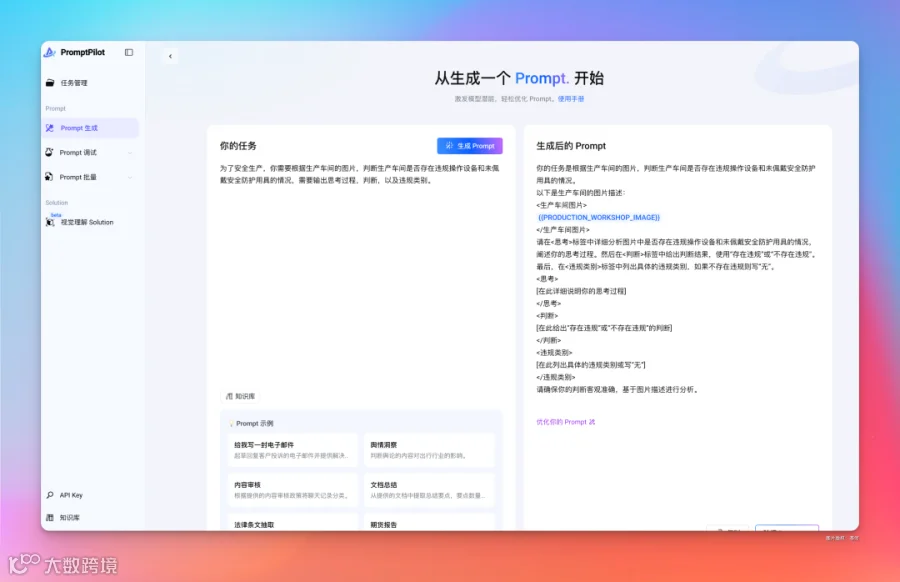
可以看到右侧生成后的 Prompt 有加了图片变量和控制模型输出的内容。
对于输出结果不满意,可以直接选择并优化,比如我觉得这个变量太长了,不够优雅。
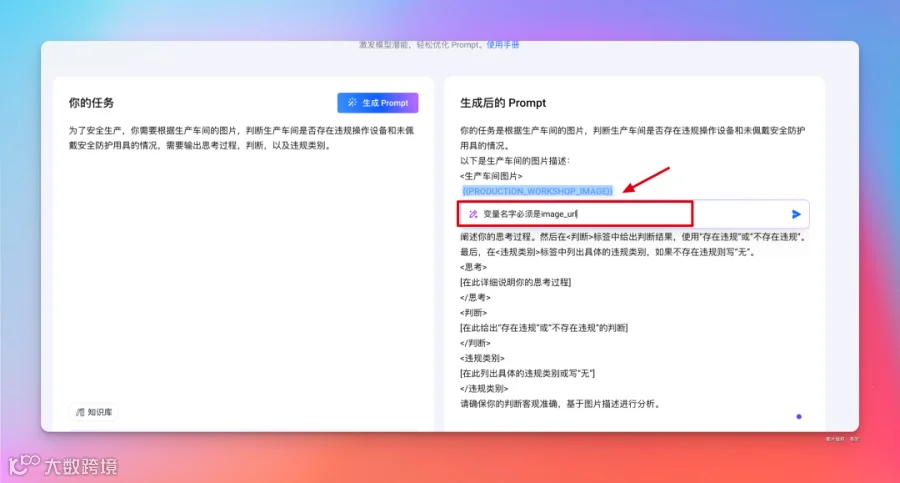
第一个版本的提示词吐下:
你的任务是根据生产车间的图片,判断生产车间是否存在违规操作设备和未佩戴安全防护用具的情况。 以下是生产车间的图片描述: <生产车间图片> {{image_url}} </生产车间图片>
请在<思考>标签中详细分析图片中是否存在违规操作设备和未佩戴安全防护用具的情况,阐述你的思考过程。然后在<判断>标签中给出判断结果,使用“存在违规”或“不存在违规”。最后,
在<违规类别>标签中列出具体的违规类别,如果不存在违规则写“无”。 <思考> [在此详细说明你的思考过程] </思考>
<判断> [在此给出“存在违规”或“不存在违规”的判断] </判断>
<违规类别> [在此列出具体的违规类别或写“无”] </违规类别> 请确保你的判断客观准确,基于图片描述进行分析。 好,接下来,就可以对这个 Prompt 进行调试了,因为是一个图片理解任务,在 Prompt 调试这需要选择对应的视觉理解。
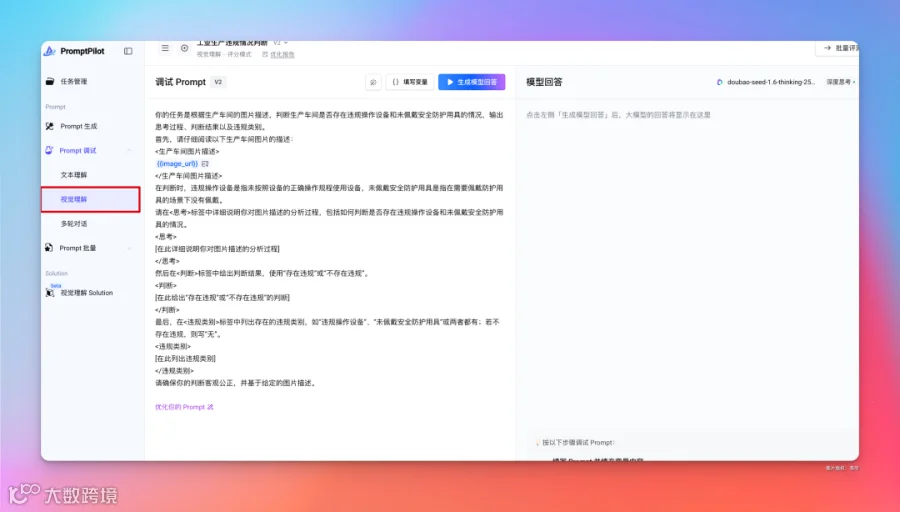
也可以在右下方选择「验证 Prompt」,选择合适的调优模式。
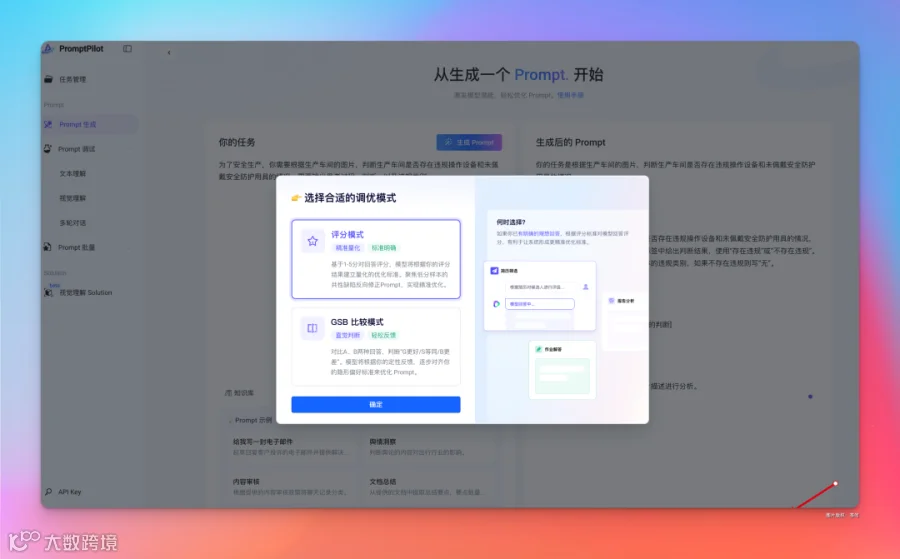
一个是打分来评判,一个是通过两种回答的对比来评判。
比如我们选择了评分模式,这里默认进来了「文本理解」,需要手动切换下到『视觉理解』。
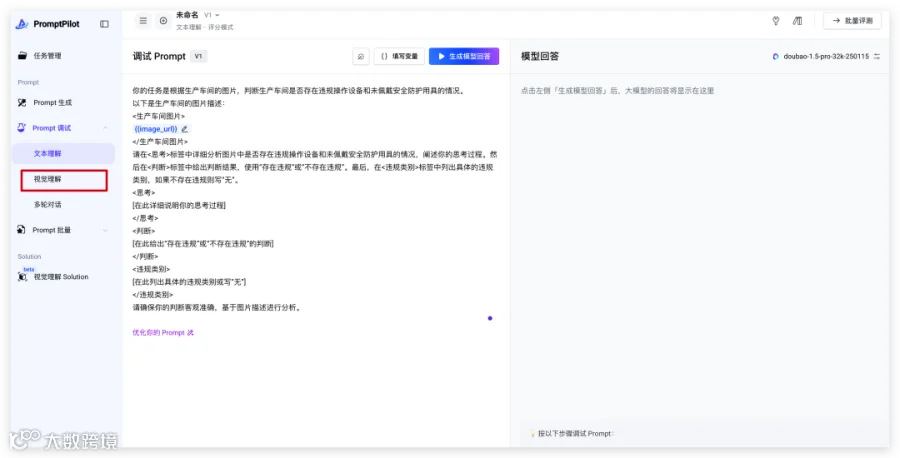
相比较而言,这样的好处是不要再复制刚才生成的 Prompt 了,丝滑一些。
可以给本次任务取个名字,方便对比评优任务不同的 case。
先来做个单 case 验证,现在我们需要传入一张图片,然后让大模型跑一遍我们的 Prompt,看看效果就好。
选择填写变量,上传一张图片。
比如这里我在网上找一张图片直接上传后。
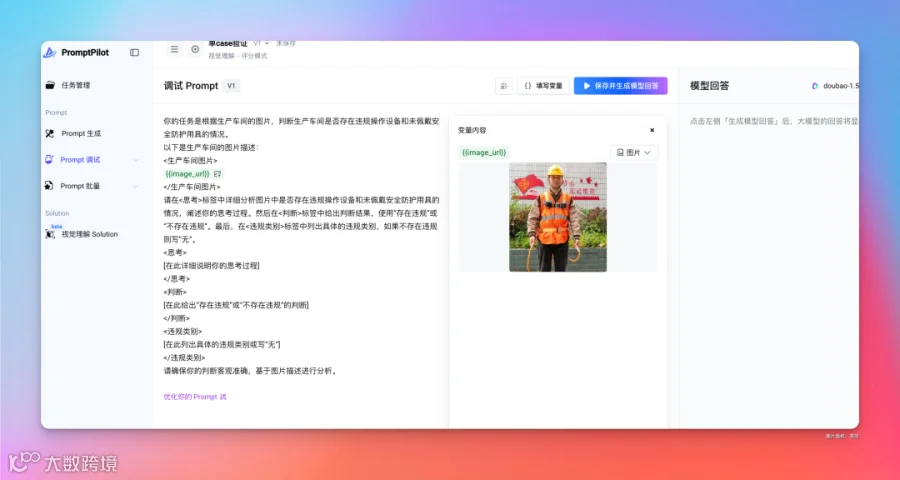
然后选择一下大模型,选择 doubao-seed-1.6-thinking 模型,拥有推理和多模态能力。
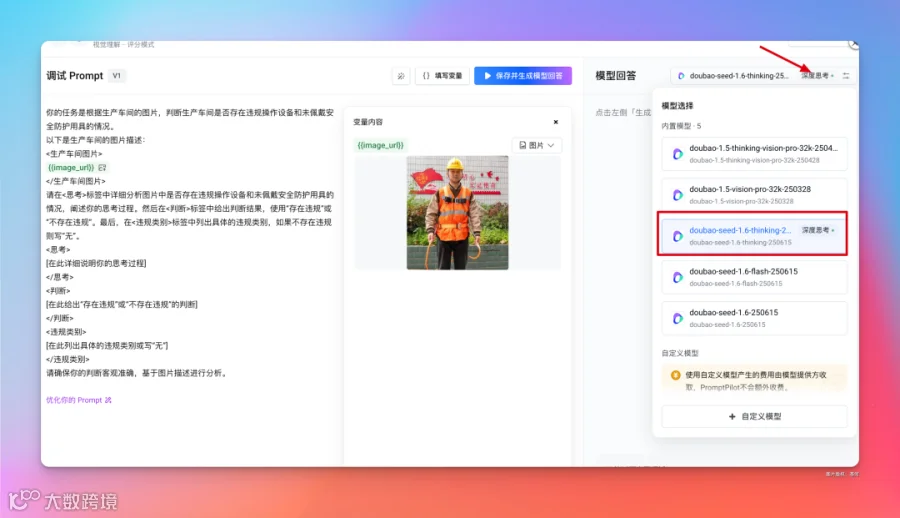
点击「保存并生成模型回答」。
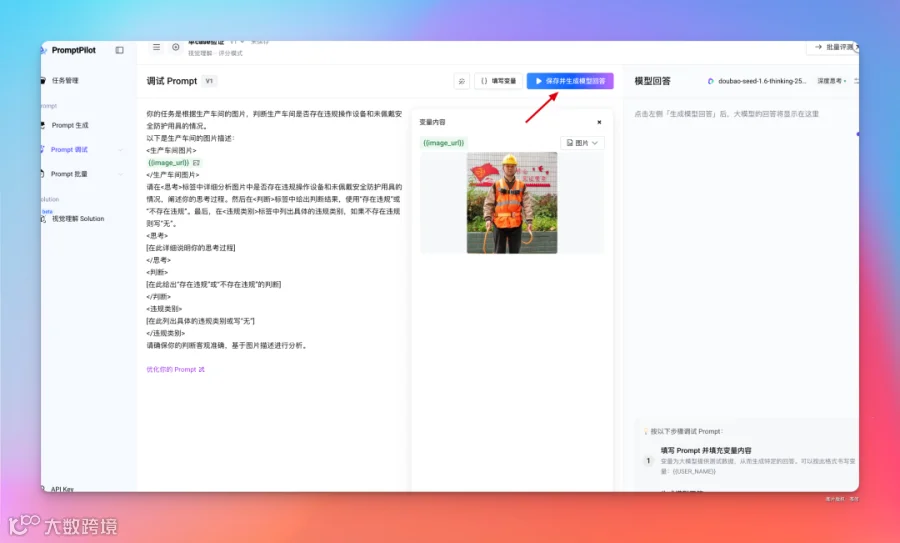
这个是根据初始 Prompt 生成的模型回答。可以看到输出是严格按照我们的要求,以及做了图片理解。
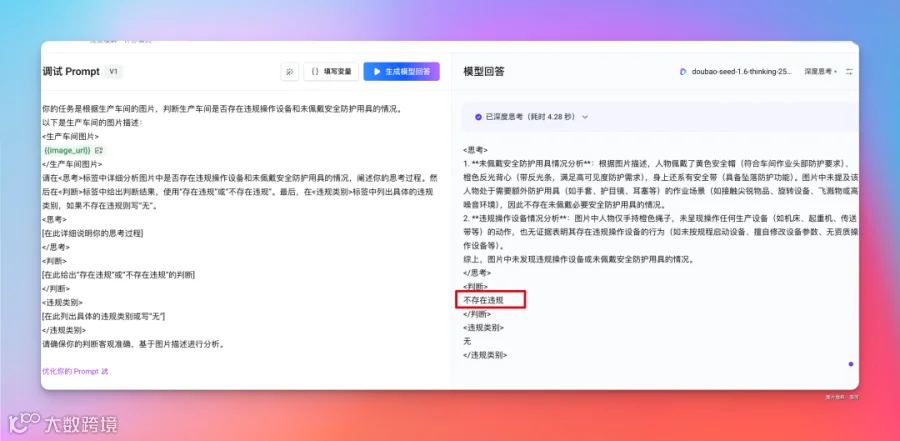
对于回答不满意,可以直接改写,点击「基于模型回答改写」:
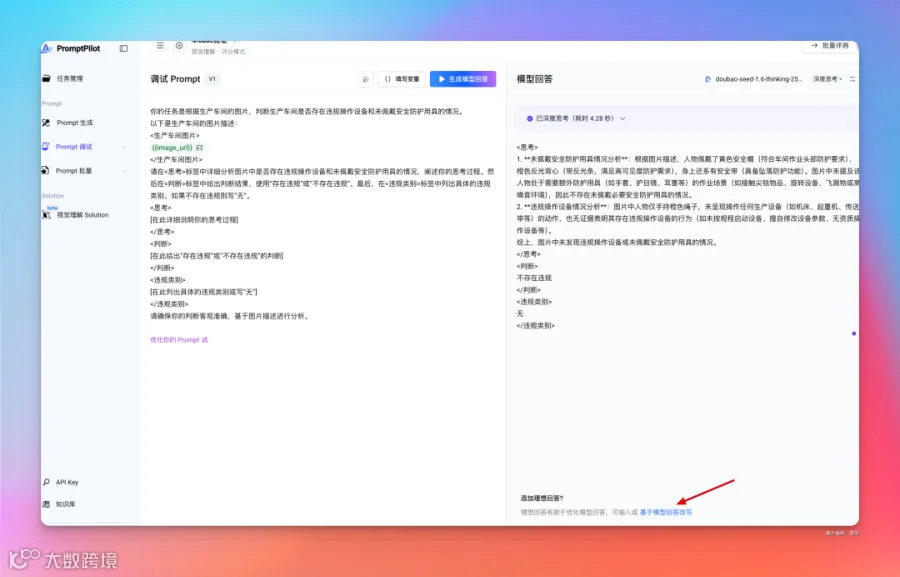
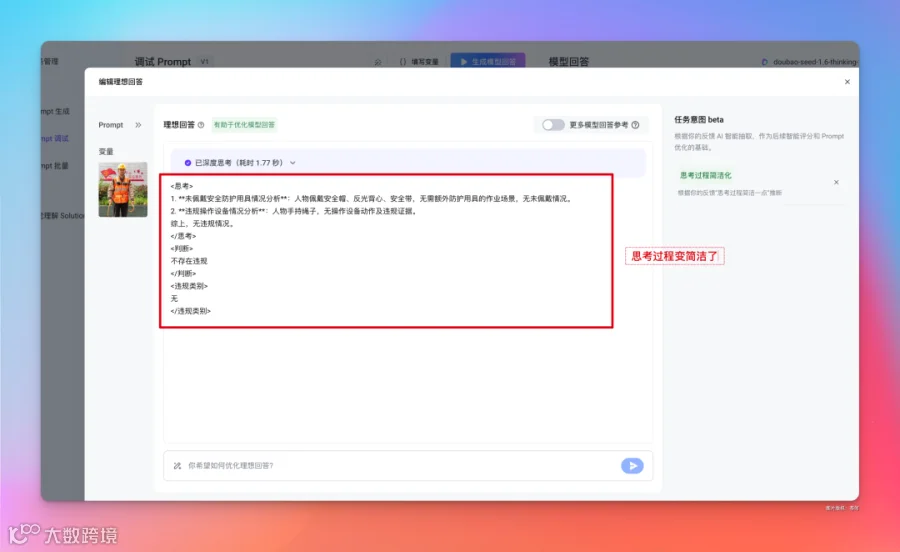
比方说,这里我觉得思考过程太长了,让他简洁一点吧:
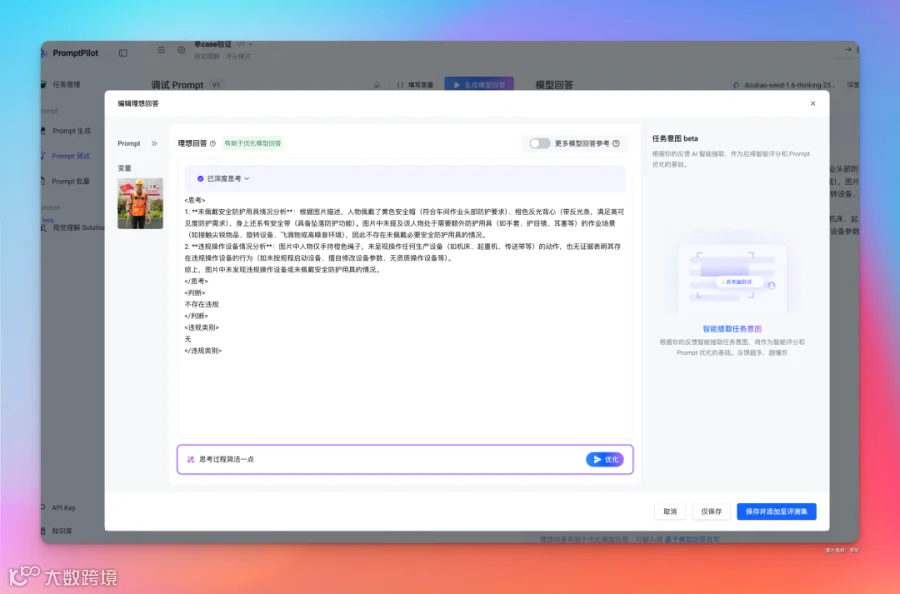
优化后,思考过程果然简洁多了。
可以选择将此次调试结果添加到评测集。在这里就能看到刚才我们的评测结果:
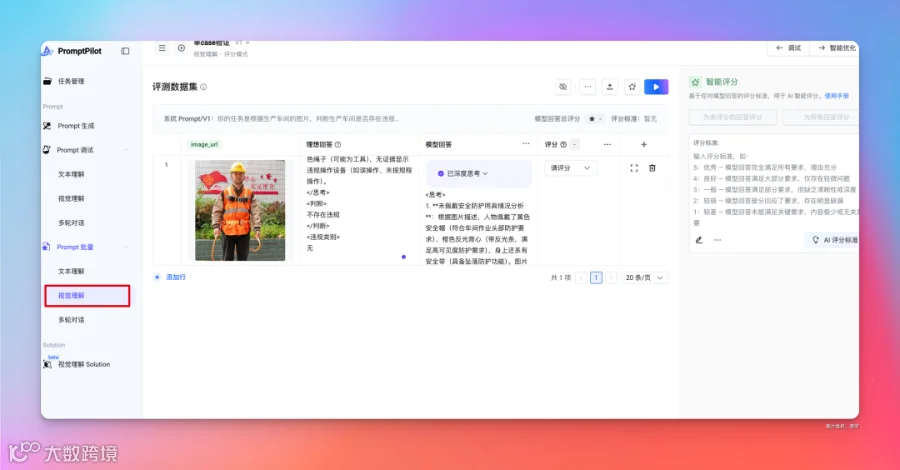
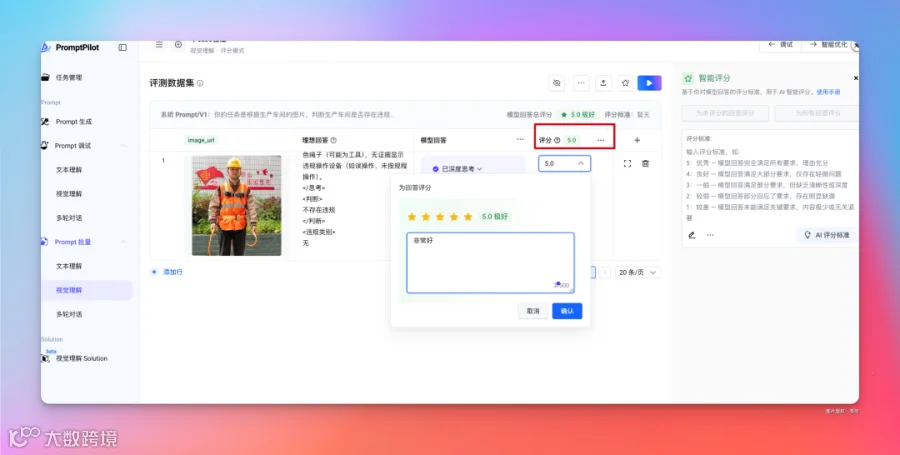
可以在评分的地方对该结果进行评分。
这里实践下来,用 2 分制方式效果更好,比如采用 5 分制,5 是满分,1 是最低分。满意就 5,不满意就 1.
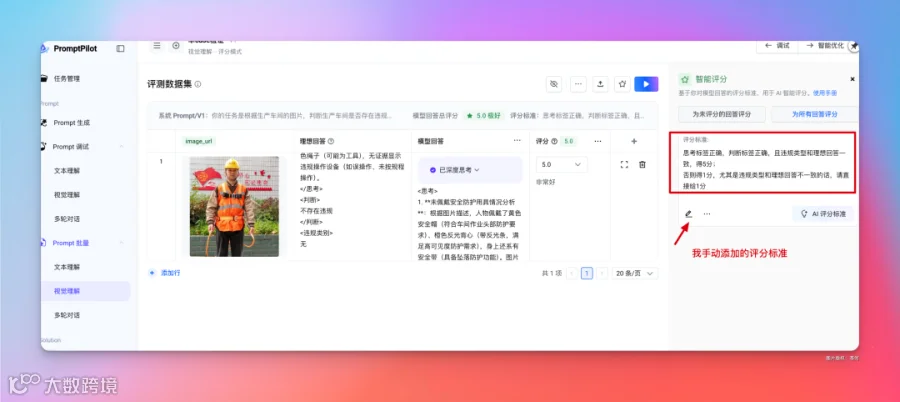
在右侧还可以添加评分标准,或者让 AI 自动生成评分标准(不过需要先手动评分至少 3 个数据集,AI 才能揣摩你的评分标准是啥)。
但很多时候,我们需要大量的评测数据对提示词进行批量评测,在 PromptPilot 中就可以 togethe 通过添加行或者上传评测数据的方式。
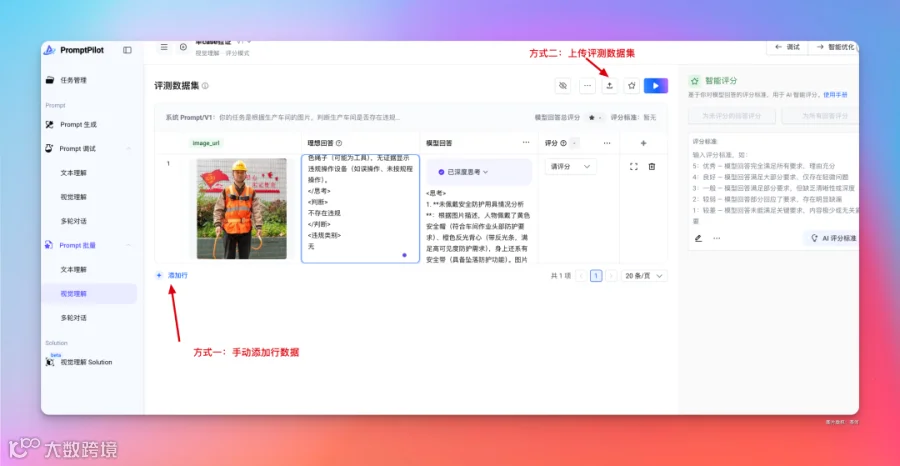
比如我上传准备好的数据集,然后点击生成模型回答,选择对应评分。
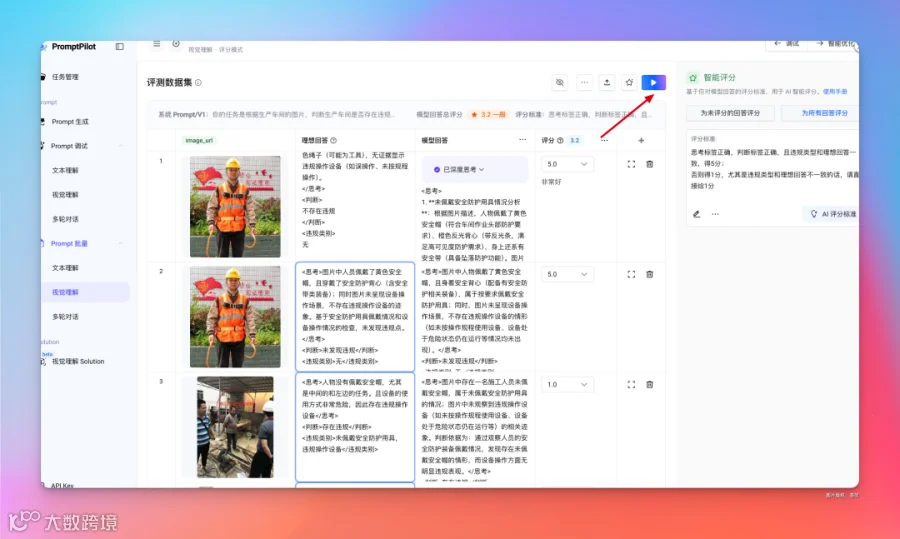
到这里,批量评测相关数据集都准备好了,然后选择「智能优化」,基于批量调试的数据集,进行提示词优化。
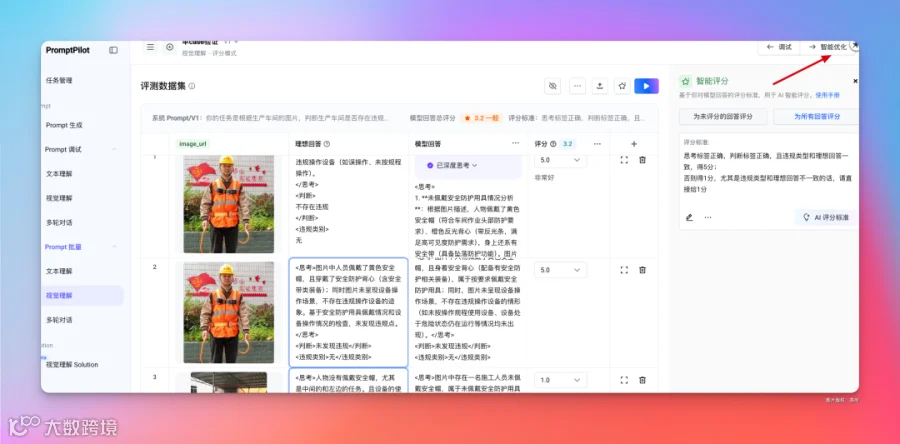
选择开启优化。
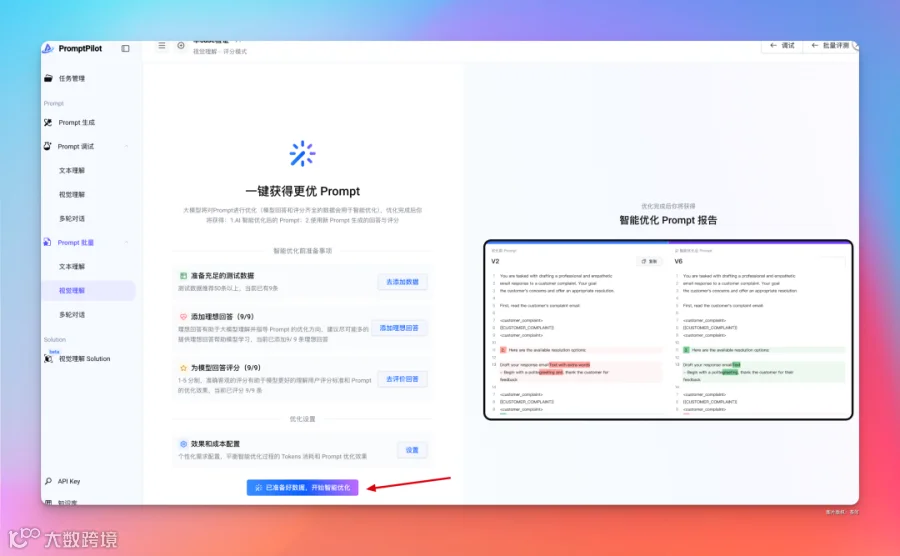
这个时候随着评测数据集的增多,优化结果也会需要等待一段时间。
等一段时间后,就可以查看评分报告,还有优化后的 Prompt 版本。
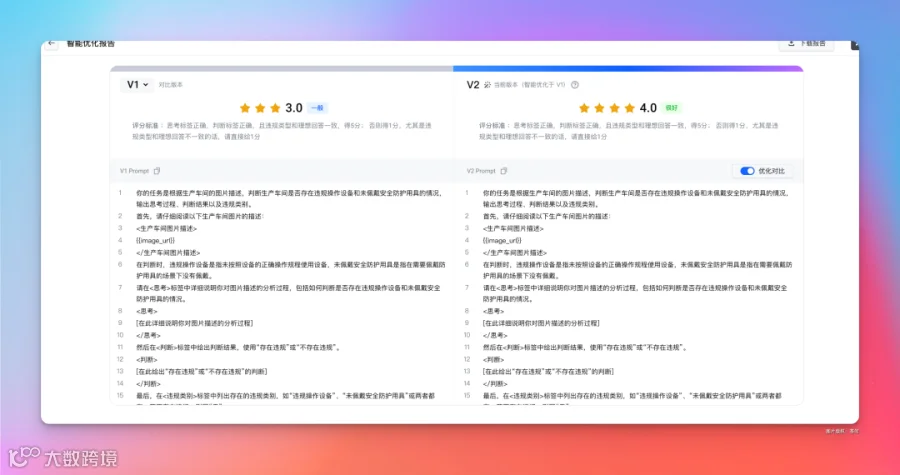
报告结果会对评分进行一轮数据对比。
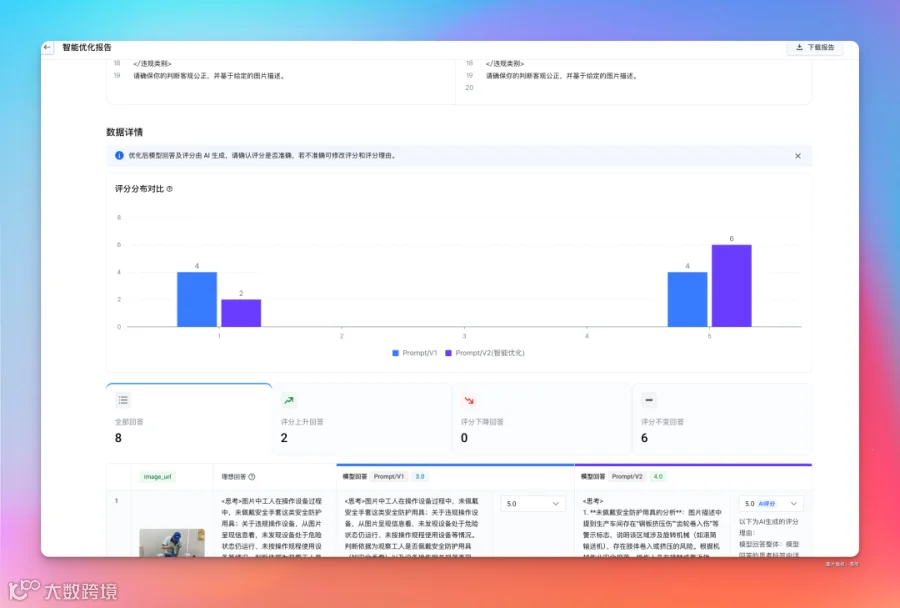
经过上面的操作,得到最终的提示词就更符合我们想要的标准了。
而且如果应用上线后,还可以基于线上数据对提示词进行多轮的优化。
可以理解成有了 PromptPilot,提示词专业优化这事就有了更好的保障。
无论是 Agent 开发还是 AI 应用开发,用 PromptPilot 基于数据指标进行的提示词优化,效果会更好。
当然了,这次开发者大会,可不止 PromptPilot 这一款产品,还有不少亮点的地方,因为篇幅有限,我就简单给大家介绍一下吧。
这次豆包模型 1.6 又有了能力的升级。代码、推理、视觉理解都有了很大的升级,特别是视觉理解能力,测下来,强的离谱。

你能信,我手写的鸡爪字,人都认不清,他给我识别出来了?
这次还发布了新的模型 doubao-Seed 1.6-Embedding,这是个最新的全模态向量化模型,引入了视频向量化能力,也就是在视频理解和搜索上,更加强大了。
还推出了 Responses API,这是火山方舟平台的 API 体系升级,降低 API 成本和开发难度,能自主选择调用工具,解决复杂 Agent 任务。

还有 AI 知识管理产品也很不错,有点类似 NotebookLM 的产品,可以支持多模态文件数据,进行知识问题。
体验下来,最厉害的地方是可以个性化进行知识分享,比如一个知识库分享给不同人,不同人收到的结果是不一样的,比如用户是开发,那就会针对开发关注的点给答案,用户是产品,就会给产品关注的答案。

还有 VikingDB 这款向量数据库产品,在 RAG 的时候,展现出很好的效果。
这次还有个重磅消息,火山方舟正式开启协作奖励计划,通过提供每日一定量的免费tokens,降低用户接入测试门槛,鼓励用户持续使用方舟,鼓励用户授权调用数据给方舟和内部算法团队优化模型效果奖励和返还机制。目前的活动主要面向企业认证用户和个人认证用户,同一主体下仅有一个账号可参与。
参与时用户需指定可授权的推理接入点(endpoint),授权后将发放一个 500 万 tokens(企业) / 50 万 tokens(个人)资源包,该资源包仅能用于授权的模型,有效期 1 个月,用于降低冷启动门槛。
参与后方舟每日会在授权 endpoint 范围内从 0 点开始顺序采集每个模型不超过 500 万tokens(企业) / 50 万 tokens(个人)tokens的数据,并于次日发放和采集量相等的有效期 1 个月的资源包。

作为个人开发者,我一直在深度使用火山的产品,说句实在的,给人感觉是用的很放心舒心,稳定、性价比和速度上都很给力。
最关键的,他们每次有新产品或模型发布,想的总是先让开发者做一波体验和反馈,会收集我们的反馈,针对产品做优化迭代。
试问,这样做产品的态度和以开发者为根本的团队,怎么会做不好产品。
而我们始终会会优秀的产品而疯狂。
好啦,以上全文 3272 字,20 张图,如果这篇文章对你有用,可否点个关注,给我个三连击:点赞、转发和再看。若可以再给我加个⭐️。
文章同步我的 AI 开源知识库:AI 开源知识库,,或者回复 AI 即可直接获取。