
技术思维和业务思维的核心区别,在于思考的 “起点” 和 “终点” 不同:
技术思维以 “技术落地” 为核心,解决 “如何实现【HOW】”;
业务思维以 “商业价值” 为核心,解决 “为何要做【WHY】” 和 “做什么【WHAT】”。
二者的差异可从 4 个关键维度清晰区分:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
技术思维会想:“优惠券规则(满减 / 折扣)怎么用代码逻辑实现?怎么避免刷券漏洞?用户领券数据存在哪个数据库更安全?” -
业务思维会想:“发优惠券是为了拉新用户还是促老用户复购?优惠券面额定多少能让用户愿意下单,又不亏太多?发券后能提升多少订单量?”
所谓技术思维,就是遇到问题或需求时,先想 “这事儿技术上能不能做到”,再拆成一步步能落地的技术步骤,最后选个 “稳、快、省” 的方案把商业构想落地的思考方式 —— 核心是 “把想法变成能用的商业化产品”。侧重于如何更好地实现。
为什么在AI时代,就可以放下“技术思维”了?为什么?AI让技术实现变得轻而易举,"怎么做"要交给AI,即给这个AI配个“牛马”的时代来了
不可能?那我们来看下现在实现需求的过程,你就有点感觉了。
需求:
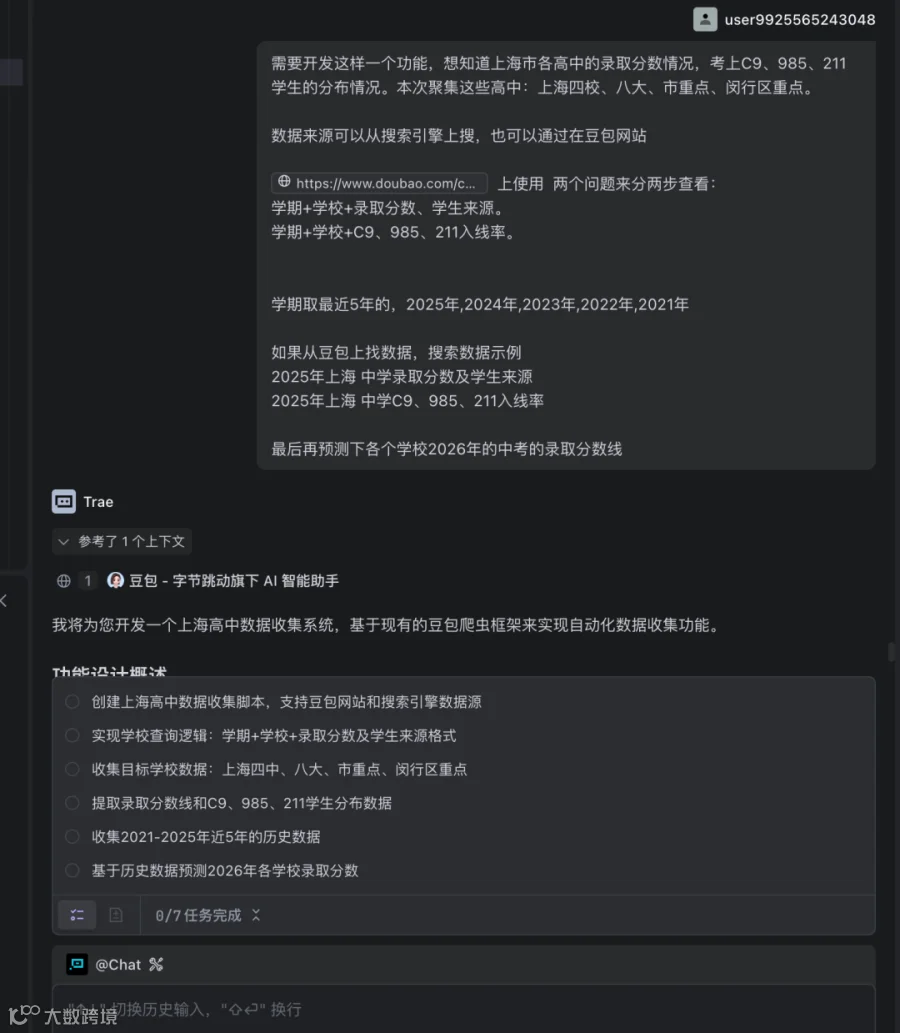
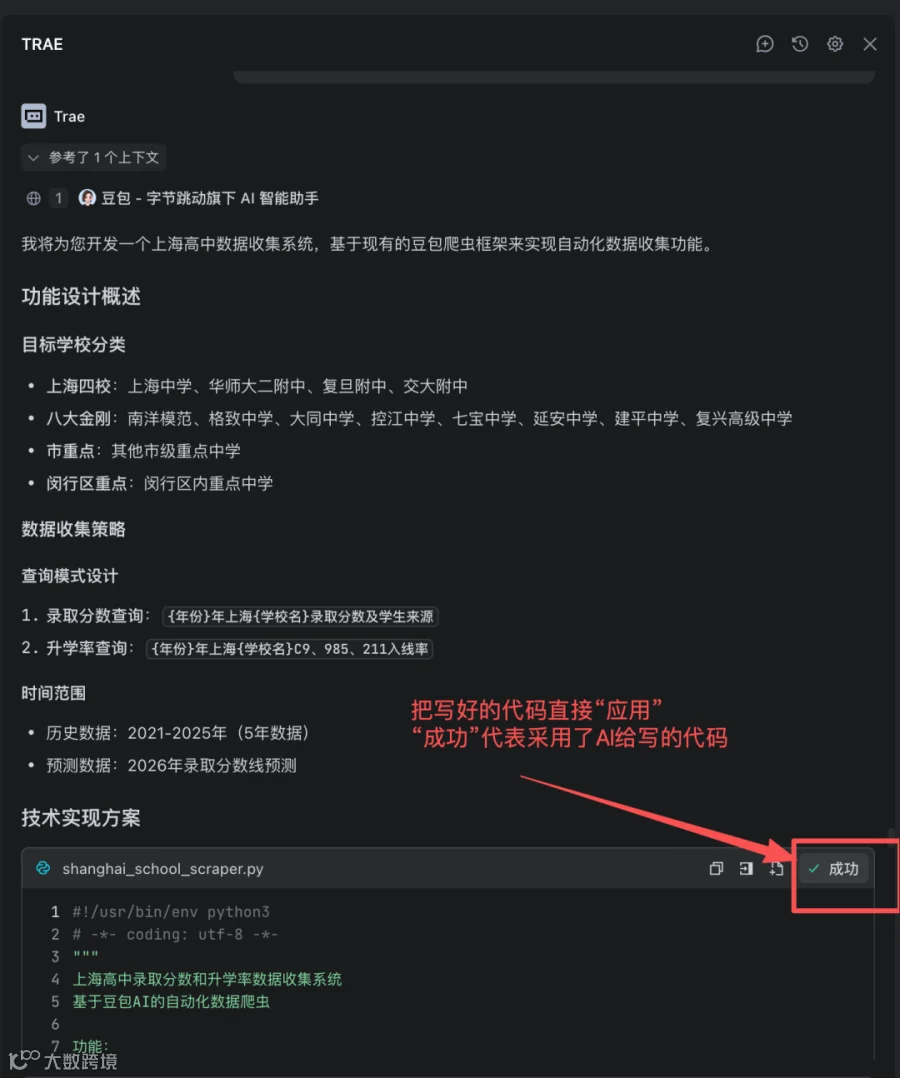
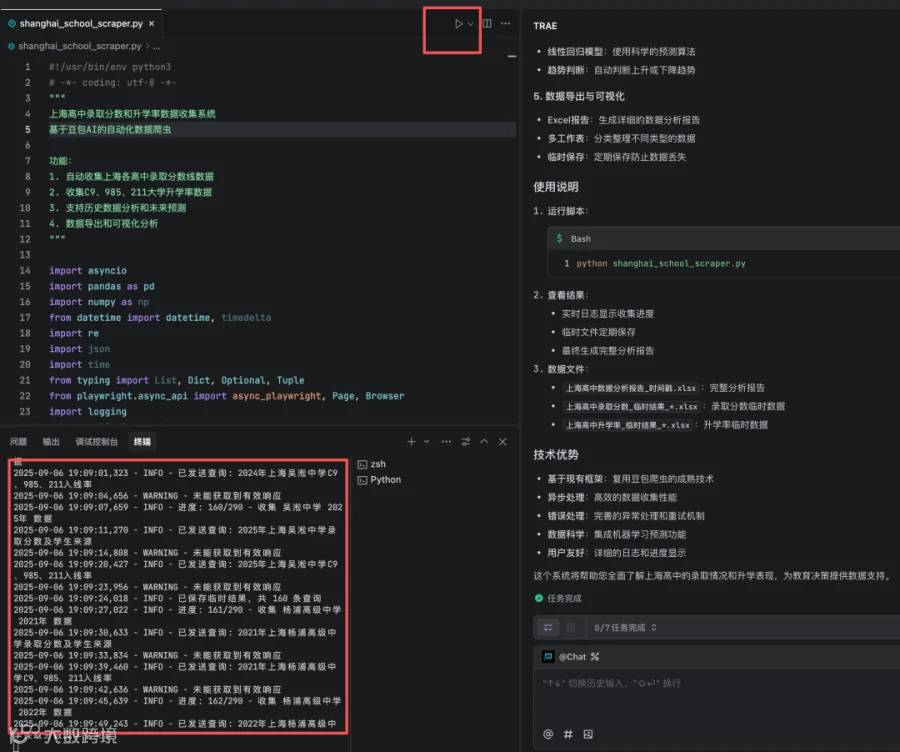
当AI让“技术实现”的门槛越来越低,作为技术人的核心价值,便从“如何实现”转向了“定义问题”。
在AI时代,如何给AI描述清楚需求才是一个关键。
你觉得对吗?
#!/usr/bin/env python3# -*- coding: utf-8 -*-"""上海高中录取分数和升学率数据收集系统基于豆包AI的自动化数据爬虫功能:1. 自动收集上海各高中录取分数线数据2. 收集C9、985、211大学升学率数据3. 支持历史数据分析和未来预测4. 数据导出和可视化分析"""import asyncioimport pandas as pdimport numpy as npfrom datetime import datetime, timedeltaimport reimport jsonimport timefrom typing import List, Dict, Optional, Tuplefrom playwright.async_api import async_playwright, Page, Browserimport loggingfrom pathlib import Pathimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.linear_model import LinearRegressionfrom sklearn.preprocessing import PolynomialFeaturesimport warningswarnings.filterwarnings('ignore')# 设置中文字体plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial Unicode MS']plt.rcParams['axes.unicode_minus'] = Falseclass ShanghaiSchoolDataCollector:"""上海高中数据收集器"""def __init__(self, headless: bool = False, slow_mo: int = 1000):self.headless = headlessself.slow_mo = slow_moself.browser: Optional[Browser] = Noneself.page: Optional[Page] = None# 配置日志logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(levelname)s - %(message)s',handlers=[logging.FileHandler('shanghai_school_scraper.log', encoding='utf-8'),logging.StreamHandler()])self.logger = logging.getLogger(__name__)# 目标学校配置self.target_schools = {"四校": ["上海中学", "华师大二附中", "复旦附中", "交大附中"],"八大": ["南洋模范中学", "格致中学", "大同中学", "控江中学","七宝中学", "延安中学", "建平中学", "复兴高级中学"],"市重点": ["向明中学", "卢湾高级中学", "敬业中学", "光明中学","市西中学", "市北中学", "回民中学", "六十中学","曹杨二中", "宜川中学", "晋元高级中学", "新中高级中学","华师大一附中", "中原中学", "华东理工大学附中", "上理工附中","上大附中", "上海师大附中", "行知中学", "吴淞中学","杨浦高级中学", "同济一附中", "理工大附中", "复旦实验中学","进才中学", "洋泾中学", "东昌中学", "川沙中学","南汇中学", "华师大三附中", "上南中学", "金山中学","张堰中学", "朱家角中学", "青浦高级中学", "白鹤中学","崇明中学", "民本中学", "扬子中学"],"闵行区重点": ["闵行中学", "莘庄中学", "闵行二中", "闵行三中","文来中学", "协和双语学校", "星河湾双语学校"]}# 查询年份self.target_years = [2021, 2022, 2023, 2024, 2025]# 数据存储self.admission_data = []self.university_data = []# 豆包网站配置self.doubao_url = "https://www.doubao.com/chat/"self.wait_time = 3 # 等待响应时间(秒)async def start_browser(self):"""启动浏览器"""playwright = await async_playwright().start()self.browser = await playwright.chromium.launch(headless=self.headless,slow_mo=self.slow_mo)context = await self.browser.new_context(user_agent="Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")self.page = await context.new_page()self.logger.info("浏览器启动成功")async def close_browser(self):"""关闭浏览器"""if self.browser:await self.browser.close()self.logger.info("浏览器已关闭")async def navigate_to_doubao(self):"""导航到豆包网站"""try:await self.page.goto(self.doubao_url, wait_until="networkidle")await self.page.wait_for_timeout(2000)self.logger.info("成功访问豆包网站")return Trueexcept Exception as e:self.logger.error(f"访问豆包网站失败: {e}")return Falseasync def send_query_and_get_response(self, query: str) -> Optional[str]:"""发送查询并获取响应"""try:# 查找输入框input_selector = "textarea, input[type='text'], [contenteditable='true']"await self.page.wait_for_selector(input_selector, timeout=10000)# 清空并输入查询await self.page.fill(input_selector, "")await self.page.fill(input_selector, query)await self.page.wait_for_timeout(500)# 发送查询(尝试多种方式)try:await self.page.press(input_selector, "Enter")except:# 如果Enter不工作,尝试点击发送按钮send_button = await self.page.query_selector("button[type='submit'], button:has-text('发送'), button:has-text('提交')")if send_button:await send_button.click()self.logger.info(f"已发送查询: {query}")# 等待响应await self.page.wait_for_timeout(self.wait_time * 1000)# 获取响应内容response_selectors = [".message-content", ".response", ".answer", ".reply","[data-testid='message']", ".chat-message", ".ai-response"]response_text = ""for selector in response_selectors:elements = await self.page.query_selector_all(selector)if elements:# 获取最后一个响应last_element = elements[-1]text = await last_element.inner_text()if text and len(text) > 50: # 确保是有意义的响应response_text = textbreakif not response_text:# 如果没有找到特定选择器,尝试获取页面中的所有文本page_text = await self.page.inner_text("body")# 简单的响应提取逻辑lines = page_text.split('\n')for i, line in enumerate(lines):if query[:10] in line and i + 1 < len(lines):response_text = '\n'.join(lines[i+1:i+20]) # 获取查询后的20行breakif response_text:self.logger.info(f"获取到响应,长度: {len(response_text)}")return response_textelse:self.logger.warning("未能获取到有效响应")return Noneexcept Exception as e:self.logger.error(f"查询过程出错: {e}")return Nonedef extract_admission_scores(self, text: str, school: str, year: int) -> Dict:"""从响应文本中提取录取分数线信息"""data = {"学校": school,"年份": year,"录取分数线": None,"最低分": None,"平均分": None,"学生来源": [],"原始文本": text[:500] # 保存前500字符用于调试}try:# 提取分数线(各种可能的表达方式)score_patterns = [r'录取分数[线]?[::]?\s*(\d{3,4})',r'分数线[::]?\s*(\d{3,4})',r'最低分[::]?\s*(\d{3,4})',r'投档线[::]?\s*(\d{3,4})',r'(\d{3,4})分',r'分数[::]?\s*(\d{3,4})']for pattern in score_patterns:matches = re.findall(pattern, text)if matches:scores = [int(score) for score in matches if 400 <= int(score) <= 700]if scores:data["录取分数线"] = max(scores) # 取最高分作为录取线data["最低分"] = min(scores)data["平均分"] = sum(scores) / len(scores)break# 提取学生来源信息source_patterns = [r'来自([^,。]+区)',r'([^,。]+区)学生',r'生源[::]?([^,。]+)',r'主要来源[::]?([^,。]+)']sources = []for pattern in source_patterns:matches = re.findall(pattern, text)sources.extend(matches)data["学生来源"] = list(set(sources)) # 去重except Exception as e:self.logger.error(f"提取录取分数信息时出错: {e}")return datadef extract_university_rates(self, text: str, school: str, year: int) -> Dict:"""从响应文本中提取大学升学率信息"""data = {"学校": school,"年份": year,"C9升学率": None,"985升学率": None,"211升学率": None,"一本率": None,"本科率": None,"原始文本": text[:500]}try:# 提取各类升学率rate_patterns = {"C9升学率": [r'C9[^\d]*(\d+(?:\.\d+)?)%', r'九校联盟[^\d]*(\d+(?:\.\d+)?)%'],"985升学率": [r'985[^\d]*(\d+(?:\.\d+)?)%', r'985院校[^\d]*(\d+(?:\.\d+)?)%'],"211升学率": [r'211[^\d]*(\d+(?:\.\d+)?)%', r'211院校[^\d]*(\d+(?:\.\d+)?)%'],"一本率": [r'一本[^\d]*(\d+(?:\.\d+)?)%', r'重点大学[^\d]*(\d+(?:\.\d+)?)%'],"本科率": [r'本科[^\d]*(\d+(?:\.\d+)?)%', r'本科院校[^\d]*(\d+(?:\.\d+)?)%']}for rate_type, patterns in rate_patterns.items():for pattern in patterns:matches = re.findall(pattern, text)if matches:rates = [float(rate) for rate in matches if 0 <= float(rate) <= 100]if rates:data[rate_type] = max(rates) # 取最高值breakif data[rate_type] is not None:breakexcept Exception as e:self.logger.error(f"提取升学率信息时出错: {e}")return dataasync def collect_school_data(self, school: str, year: int) -> Tuple[Dict, Dict]:"""收集单个学校的数据"""admission_data = Noneuniversity_data = Nonetry:# 查询1: 录取分数及学生来源query1 = f"{year}年上海{school}录取分数及学生来源"response1 = await self.send_query_and_get_response(query1)if response1:admission_data = self.extract_admission_scores(response1, school, year)self.logger.info(f"已收集 {school} {year}年 录取分数数据")await self.page.wait_for_timeout(2000) # 等待2秒避免请求过快# 查询2: C9、985、211升学率query2 = f"{year}年上海{school}C9、985、211入线率"response2 = await self.send_query_and_get_response(query2)if response2:university_data = self.extract_university_rates(response2, school, year)self.logger.info(f"已收集 {school} {year}年 升学率数据")except Exception as e:self.logger.error(f"收集 {school} {year}年 数据时出错: {e}")return admission_data, university_dataasync def collect_all_data(self):"""收集所有学校的数据"""await self.start_browser()if not await self.navigate_to_doubao():await self.close_browser()returntotal_schools = sum(len(schools) for schools in self.target_schools.values())total_queries = total_schools * len(self.target_years)current_query = 0try:for category, schools in self.target_schools.items():self.logger.info(f"开始收集 {category} 数据")for school in schools:for year in self.target_years:current_query += 1self.logger.info(f"进度: {current_query}/{total_queries} - 收集 {school} {year}年 数据")admission_data, university_data = await self.collect_school_data(school, year)if admission_data:admission_data["学校类别"] = categoryself.admission_data.append(admission_data)if university_data:university_data["学校类别"] = categoryself.university_data.append(university_data)# 保存临时结果if current_query % 10 == 0:await self.save_temporary_results(current_query)await self.page.wait_for_timeout(3000) # 等待3秒except Exception as e:self.logger.error(f"数据收集过程中出错: {e}")finally:await self.close_browser()async def save_temporary_results(self, query_count: int):"""保存临时结果"""timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")if self.admission_data:df_admission = pd.DataFrame(self.admission_data)filename = f"上海高中录取分数_临时结果_{query_count}条_{timestamp}.xlsx"df_admission.to_excel(filename, index=False, engine='openpyxl')if self.university_data:df_university = pd.DataFrame(self.university_data)filename = f"上海高中升学率_临时结果_{query_count}条_{timestamp}.xlsx"df_university.to_excel(filename, index=False, engine='openpyxl')self.logger.info(f"已保存临时结果,共 {query_count} 条查询")def predict_2026_scores(self) -> pd.DataFrame:"""预测2026年录取分数线"""if not self.admission_data:self.logger.warning("没有录取分数数据,无法进行预测")return pd.DataFrame()df = pd.DataFrame(self.admission_data)df = df[df['录取分数线'].notna()]predictions = []for school in df['学校'].unique():school_data = df[df['学校'] == school].sort_values('年份')if len(school_data) >= 3: # 至少需要3年数据进行预测X = school_data['年份'].values.reshape(-1, 1)y = school_data['录取分数线'].values# 使用线性回归进行预测model = LinearRegression()model.fit(X, y)# 预测2026年predicted_score = model.predict([[2026]])[0]# 获取学校类别category = school_data.iloc[0]['学校类别']predictions.append({'学校': school,'学校类别': category,'2026年预测分数线': round(predicted_score, 1),'历史平均分': round(school_data['录取分数线'].mean(), 1),'数据年数': len(school_data),'趋势': '上升' if model.coef_[0] > 0 else '下降'})return pd.DataFrame(predictions)def generate_analysis_report(self):"""生成分析报告"""timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")with pd.ExcelWriter(f"上海高中数据分析报告_{timestamp}.xlsx", engine='openpyxl') as writer:# 录取分数数据if self.admission_data:df_admission = pd.DataFrame(self.admission_data)df_admission.to_excel(writer, sheet_name='录取分数数据', index=False)# 升学率数据if self.university_data:df_university = pd.DataFrame(self.university_data)df_university.to_excel(writer, sheet_name='升学率数据', index=False)# 2026年预测df_predictions = self.predict_2026_scores()if not df_predictions.empty:df_predictions.to_excel(writer, sheet_name='2026年预测', index=False)# 统计分析if self.admission_data:df_admission = pd.DataFrame(self.admission_data)df_stats = df_admission.groupby(['学校类别', '年份'])['录取分数线'].agg(['count', 'mean', 'median', 'std']).round(2)df_stats.to_excel(writer, sheet_name='分数统计分析')self.logger.info(f"分析报告已生成: 上海高中数据分析报告_{timestamp}.xlsx")async def run(self):"""运行完整的数据收集流程"""self.logger.info("开始上海高中数据收集")self.logger.info(f"目标学校总数: {sum(len(schools) for schools in self.target_schools.values())}")self.logger.info(f"目标年份: {self.target_years}")# 收集数据await self.collect_all_data()# 生成报告self.generate_analysis_report()self.logger.info("数据收集完成")# 打印统计信息print(f"\n=== 数据收集统计 ===")print(f"录取分数数据条数: {len(self.admission_data)}")print(f"升学率数据条数: {len(self.university_data)}")if self.admission_data:df_admission = pd.DataFrame(self.admission_data)valid_scores = df_admission[df_admission['录取分数线'].notna()]print(f"有效录取分数数据: {len(valid_scores)}")if self.university_data:df_university = pd.DataFrame(self.university_data)valid_rates = df_university[df_university['985升学率'].notna()]print(f"有效升学率数据: {len(valid_rates)}")# 使用示例async def main():"""主函数"""collector = ShanghaiSchoolDataCollector(headless=False, # 设置为True可以无头模式运行slow_mo=1000 # 操作间隔时间(毫秒))await collector.run()if __name__ == "__main__":print("上海高中数据收集系统")print("=" * 50)print("功能说明:")print("1. 自动收集上海各高中录取分数线数据")print("2. 收集C9、985、211大学升学率数据")print("3. 支持历史数据分析和未来预测")print("4. 生成详细的数据分析报告")print("=" * 50)# 运行数据收集asyncio.run(main())
## 安装依赖
pip install playwright pandas numpy matplotlib seaborn scikit-learn openpyxlplaywright install chromium
## 使用说明
1. 1 运行脚本 :
python shanghai_school_scraper.py感谢 Vibe Coding,又撸完上线一个新服务 又撸完上线一个新服务:UnifiedTTS,为需要接入多供应商TTS能力的开发者构建的统一API接口。
为什么要做这个?
因为自己的其他应用需要接入多个供应商的TTS
公众号:程序猿DD感谢 Vibe Coding,又撸完上线一个新服务
Part3:
Vibe Coding
「vibe coding」这个概念最早就是由Karpathy提出的。简单说就是通过对话让LLM编写代码,而你只需要沉浸在解决问题的「氛围」中,同时忽略生成的代码细节。用Karpathy大神的话说就是,「我只是看到东西,说出东西,运行东西,复制粘贴东西,而且大部分情况都奏效。」
新智元,公众号:新智元Karpathy带火「Vibe Coding」!YC证实:1/4新初创,95%代码全由AI生成

