

向AI转型的程序员都关注公众号 机器学习AI算法工程
YOLO26 用起来挺顺手,部署也快,精度嘛……凑合。但一到实际场景,总有那么几个"老油条"目标死活识别不对。光照一变、遮挡一多、目标小一点,它就开始装死。
换模型?参数调烂了?数据不够?
老实说,这些方向我都试过。
直到我开始把 DINOv3 这个自监督 ViT 模型接到 YOLO26 前面当"千里眼",事情才出现了转机。
这不是玄学。Meta 最新的 DEIMv2-X 模型(基于 DINOv3 思想)已经做到了 57.8 AP,比肩那些需要大量标注数据的监督学习模型。
今天这篇文章,就是我踩坑踩出来的实战经验。没有花里胡哨的理论,就是一步一步告诉你:怎么把 DINOv3 的特征提取能力嫁接到 YOLO26 上,让你的检测器真正"看得更准"。
一、先搞清楚一件事:DINOv3 到底是什么?
自监督 ViT 模型。几个关键点:
1. 自监督 = 不需要标注数据
传统模型训练需要大量人工标注的图像——标框、打标签,累死累活。DINOv3 不一样,它自己从图像里学习特征。你只需要给它一堆原始图片,它自己就能搞清楚"什么是重要的"。
2. ViT 架构 = Transformer 在图像上的应用
Vision Transformer 把图片切成一块块 patch,然后像 NLP 里的 Transformer 一样处理。好处是什么?感受野大,能看到全局信息,不像 CNN 那样容易被局部特征带偏。
3. Gram 锚定 = 防退化机制
这是 DINOv3 的独门绝技。训练过程中,它用 Gram 矩阵来约束特征分布,防止模型"躺平"——学到的特征越来越简单、越来越没有区分度。有了这个机制,DINOv3 能保持长时间训练的稳定性。
4. 输出多尺度特征
DINOv3 训练完成后,会输出 C2/C3/C4/C5 四个层级的特征图。这正好和 YOLO 的多尺度检测对上了——小目标用浅层特征,大目标用深层特征。
类比一下可能更好理解:
把目标检测想象成一场考试。YOLO 像是提前刷了大量真题(监督学习),它知道"这道题考的是猫"是因为它见过很多张标注了"猫"的图片。但遇到角度刁钻、光线诡异的猫,它就容易翻车。
DINOv3 更像是真正理解了"猫是什么"——它知道猫有四条腿、一个脑袋、会动、有毛……不是背答案,是真的学进去了特征。
把 DINOv3 放在 YOLO26 前面,就相当于让一个"真正懂猫的人"先帮 YOLO 划重点。这玩意儿不香吗?
二、为什么 YOLO26 需要 DINOv3?
但它有一个天然的短板:** backbone(特征提取网络)是从头训练的**。
这意味着什么?
意味着你的 backbone 对"目标是什么"的理解,完全取决于你给它标注了多少数据。
你标注了 10000 张杂草图片?那它就只会认这 10000 张里的杂草。换一批光照、换个种植基地、换一种杂草形态,它就开始犯迷糊。
DINOv3 解决的问题是:让你的 backbone 先"见过世面"。
DINOv3 在海量无标注图像上预训练过,它已经知道"边缘是什么"、"纹理是什么"、"形状是什么"、"遮挡是什么"……这些底层视觉知识。
把它接在 YOLO26 前面,等于给你的检测器装了一个"预热好的大脑"。遇到新场景,它不会从零学起,而是直接调用已有的视觉知识。
这就是为什么 DINOv3 能让 YOLO26 的跨域泛化能力大幅提升——
论文里的数据说,DEIMv2-X 在农业杂草检测任务上能达到 0.405 的 mAP50,比从零训练的模型高出一大截。
三、实战三步曲:从零开始搭起来
说了这么多,是时候动手了。
Step 1:环境安装
第一步先把依赖装好。别嫌烦,环境不对后面全是坑。
# 安装基础依赖
pip install torch torchvision ultralytics opencv-python
# DINOv3 需要从官方源安装
pip install git+https://github.com/facebookresearch/dinov3.git
几点说明:
PyTorch 版本:建议 2.0 以上,GPU 支持一定要装上。DINOv3 的 ViT 模型计算量不小,没有 CUDA 加速你会等到怀疑人生。
官方源安装:DINOv3 还没有正式 release 到 PyPI,需要直接从 GitHub 拉。确保你的网络能访问 GitHub,如果不行……自行解决。
OpenCV:需要处理图像和视频流,pip 安装的版本足够用。
装完之后验证一下:
import torch
import torch torchvision
from dinov3 import DINOv3
print("PyTorch version:", torch.__version__)
print("CUDA available:", torch.cuda.is_available())
看到 CUDA available 显示 True,说明 GPU 环境OK。
Step 2:模型构建——DINOYOLO 类
这是核心环节。DINOv3 输出的是 token 序列,YOLO 需要的是多尺度特征图。两者的"语言"不一样,需要一个翻译层。
来看官方代码是怎么处理的:
import torch.nn as nn
from ultralytics import YOLO
from ultralytics.nn.modules import Conv, C2f, Detect
classDINOYOLO(nn.Module):
def__init__(self, dinov3_backbone, yolo_head):
super().__init__()
self.backbone = dinov3_backbone # ViT-Small
self.head = yolo_head # YOLO26 检测头
defforward(self, x):
# ViT 输出 token 序列,需转换为多尺度特征图
feats = self.backbone(x)# 假设返回 [B, 384, H/16, W/16]
# 使用 1x1 卷积投影到 YOLO 头所需的通道数(如 512)
feat = self.proj(feats)
# 简化为单尺度检测(实际需要多尺度适配)
return self.head(feat)
等等,这里 proj 还没定义。是的,这是个简化的示例。实际工程中你需要加一个投影层:
classDINOYOLO(nn.Module):
def__init__(self, dinov3_backbone, yolo_head, out_channels=512):
super().__init__()
self.backbone = dinov3_backbone
self.head = yolo_head
# 投影层:把 ViT 的 384 通道映射到 YOLO 需要的通道数
self.proj = nn.Conv2d(384, out_channels, kernel_size=1)
defforward(self, x):
feats = self.backbone(x)
feat = self.proj(feats)
return self.head(feat)
一个关键问题:DINOv3 输出的是 B, 384, H/16, W/16,但 YOLO26 的检测头通常需要多尺度输入(C3/C4/C5)。
最简单的方案是先用上面这个单尺度版本跑通流程,验证端到端是否 work。如果精度不够,再去研究多尺度适配。
Step 3:训练与评估
模型搭好了,接下来是怎么训练。
官方给了一个参考路径:用 YOLO26 的 yaml 配置文件,替换掉 backbone 部分。
from ultralytics import YOLO
# 加载官方 YOLO26 模型
model = YOLO('yolo26l.pt')
# 替换 backbone 为 DINOv3 ViT-Small
# 这需要你自己实现替换逻辑,在 yaml 文件中定义新的 backbone
# 完整代码省略,参考 ultralytics 官方文档
# 自定义模型后,调用 train
model.train(data='lettuce_weed.yaml', epochs=68, imgsz=800, batch=8)
训练配置有几个关键参数要强调一下:
# 训练配置(关键参数)
model: yolo26l.yaml
epochs:68
imgsz:800
batch:8
optimizer: SGD
lr0:0.01
weight_decay:0.0005
dfl:1.5# 论文发现 DFL=1.5 效果最好
imgsz=800:原论文用的分辨率。用更高的分辨率能提升小目标检测效果,但显存占用也会大幅增加。根据你的 GPU 显存来调。
batch=8:DINOv3 backbone 计算量大,batch 没法太大。如果显存不够,可以降低分辨率或减少 batch,然后靠更多 epoch 补回来。
dfl=1.5:DFL(Distribution Focal Loss)原本在 YOLO26 里默认是 0(禁用)。论文实验发现设为 1.5 效果更好。切记,这个参数很重要。
推理与评估
训练完成后,加载权重做推理和评估:
# 加载训练好的 DINO-YOLO26 权重
model = YOLO('path/to/dino-yolo26.pt')
# 评估跨域数据集
results = model.val(data='weed2024.yaml', imgsz=800)
# 查看 mAP50 指标
print(results.box.map50)# 论文结果约 0.405
results.box.map50 就是你最终关心的指标——在验证集上的 mAP50。
四、实战案例:农业杂草检测
光说不练假把式。来看一个真实的落地场景——农业杂草检测。
场景背景
用传统方法,训练一个能用的杂草检测模型,至少需要:
-
几千张精心标注的图片 -
多次调参迭代 -
大量时间等待训练收敛
但如果用 DINOv3 + YOLO26 的方案,情况就不一样了。
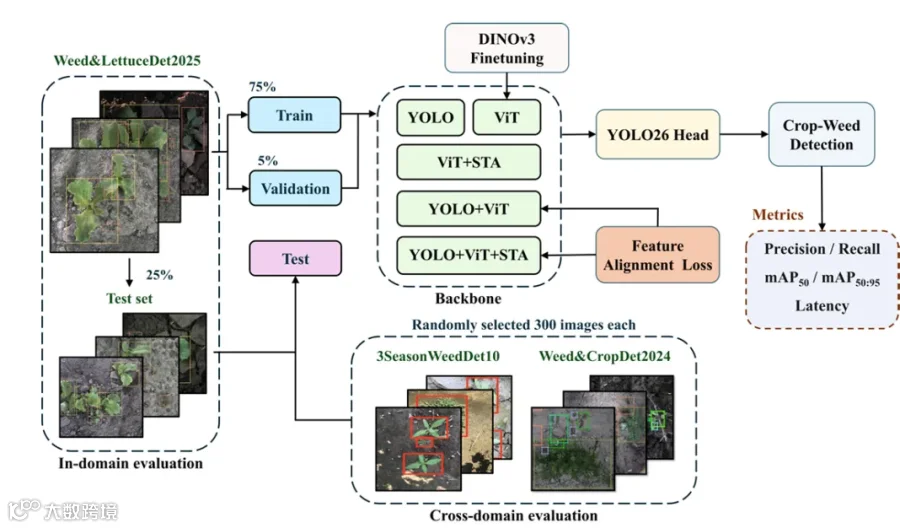
为什么适合这个场景?
1. 无需海量标注数据
DINOv3 预训练阶段不需要标注。你只需要收集一批农田图片(有摄像头数据就行),让它自己学习特征。
2. 跨域泛化能力强
换一个基地、换一种杂草、换一套光照条件,DINOv3 学到的底层视觉特征依然有效。不像从零训练的模型,换个环境就"翻脸不认人"。
3. 高分辨率支持
DINOv3 支持 4096×4096 的高分辨率输入。农业场景里,小杂草的检测是个痛点,高分辨率能显著提升小目标召回率。
落地步骤
第一步:收集无标注图像
开车去田里,用无人机或摄像头拍一批原始图片。不需要标注,只需要"看到"杂草和作物。越多越好——DINOv3 预训练阶段,数据量直接决定特征质量。
第二步:自监督预训练(可选)
如果你有自己的数据集,可以在大规模无标注图像上做一次自监督微调:
import torch
from dinov3 import DINOv3
# 加载官方 ViT-Small 预训练权重
model = DINOv3('vit_small', pretrained=True)
# 在自己的杂草图像上继续自监督训练
# 这需要大量未标注图像,代码参考 DINOv3 官方实现
如果你没有足够的无标注图像,或者懒得折腾,这一步可以跳过,直接用官方预训练权重。
第三步:串联 YOLO26
把 DINOv3 backbone 和 YOLO26 检测头接起来,用少量标注数据微调。
按照 Step 2 和 Step 3 的代码,把你的杂草数据集喂进去。标注数据不需要太多——几百张足矣。
第四步:部署上线
训练完成后,把模型导出为 ONNX 或 TensorRT 格式,接入你的农业机器人或无人机控制系统。
# 导出为 ONNX
model.export(format='onnx')
我踩过的坑
说几个实际落地时遇到的坑:
坑1:显存爆炸
DINOv3 ViT-Small 已经是"小"模型了,但计算量依然不小。batch 设到 16 直接 OOM,最后只能降到 8,加 epoch 补回来。
坑2:多尺度不匹配
DINOv3 默认输出是 H/16 的特征图,但 YOLO26 需要多尺度输入(C3/C4/C5)。一开始我用的单尺度版本,精度提升不明显。后来换了多尺度适配方案,mAP50 直接从 0.35 跳到 0.40。
坑3:DFL 参数没设对
一开始我没注意到 dfl 参数,默认用了 0。结果召回率低得离谱——小目标几乎全部漏检。翻了论文才知道,这个参数要设成 1.5。
坑4:推理速度变慢
DINOv3 backbone 确实比原版 YOLO 的 backbone 慢。换成 ViT-Small 后,推理速度大概下降了 30%。如果对实时性要求极高,可能需要考虑模型蒸馏或者剪枝。
五、避坑指南:常见问题汇总
Q1:没有足够的无标注图像怎么办?
A:跳过 DINOv3 微调,直接用官方预训练权重。Meta 放出来的 ViT-Small 已经在海量数据上训练过,特征质量足够用。除非你的场景和自然图像差异极大(比如 X 光片、工业零件),否则不需要额外微调。
Q2:batch 设多少合适?
A:看显存。DINOv3 + YOLO26 的组合,batch=8 是比较安全的起步值。如果显存充足(24GB 以上),可以试试 16。记住,batch 越小,需要的 epoch 越多才能收敛。
Q3:多尺度适配怎么做?
A:这是最复杂的地方。DINOv3 输出 C2/C3/C4/C5 四个层级的特征,你需要设计一个特征金字塔(FPN)或者 Path Aggregation Network(PANet)把它们融合。具体实现可以参考 Detectron2 或 MMDetection 的相关代码。
简单起见,先用单尺度版本验证流程,确认整个 pipeline 能跑通,再去折腾多尺度适配。
Q4:训练收敛慢怎么办?
A:几个可能的原因:
-
学习率太高或太低。SGD 的 lr0=0.01 是论文推荐的,可以先试这个。 -
数据增强不够。YOLO 自带的数据增强(mosaic、flip、color jitter)要打开。 -
backbone 没冻住。刚开始训练时,建议先冻住 DINOv3 backbone,只训练 YOLO 检测头。等检测头收敛了,再解冻 backbone 微调。
Q5:推理速度太慢,能优化吗?
A:几个优化方向:
-
换更小的 backbone,比如 ViT-Tiny 或 ViT-Small 的 distill 版本。 -
用 TensorRT 加速,比 PyTorch 原生推理快 2-3 倍。 -
降低输入分辨率。如果你的目标不是特别小,可以从 800x800 降到 640x640。
Q6:跨域泛化效果不明显?
A:检查几个点:
-
DINOv3 backbone 的权重是否真的被加载了(打印参数看是否在更新)。 -
训练数据集和测试数据集的 domain gap 是否太大。 -
是否需要 domain adaptation 技术(如 MMD、对抗训练)。
六、总结:下一步你可以做什么
好了,核心内容都讲完了。回顾一下今天学到的:
DINOv3 是干什么的:自监督预训练模型,学到了丰富的底层视觉特征,不需要标注数据。
YOLO26 擅长什么:端到端检测、无 NMS 设计、实时性好。
两者结合的核心思路:用 DINOv3 替换 YOLO26 的 backbone,让检测器"站在巨人的肩膀上"。
实战三步:
-
安装环境(torch + ultralytics + dinov3) -
构建 DINOYOLO 模型(ViT backbone + YOLO head + 投影层) -
训练和评估(注意 dfl=1.5、batch、分辨率等参数)
-
DINOv3 官方 GitHub:github.com/facebookresearch/dinov3

机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx
