
1.Python在数据挖掘中的应用
Python常被昵称为“胶水”语言,其特点是可以轻松的连接各种编程语言,粘在各个应用场景,不管是建站、爬虫、运维还是数据挖掘,都有它的身影。与其它语言相比,Python的语法简洁清晰,开发效率十分高效,通过完善的“包”往往一行代码可以实现其他语言N行代码的功能(但是某些场景执行效率不如C、Java等)。对于学习成本来讲,相对其它编程语言来讲,只要找对教程,一个对编程没有太多概念的初学者也可以轻松入门。
对于数据挖掘来讲,Python对数据清洗、数据探索、建立宽表、变量筛选、建模、模型参数优化、模型输出、模型投产等等一系列环节均有成熟的“包”进行支持。
而在建模环节,除了对传统时序、Logistic、决策树等算法的支持,Python也在不断涌现和迭代着各种最前沿且实用的算法包供用户免费使用,如:微软开源的回归/分类包LightGBM、FaceBook开源的时序包Prophet、Google开源的神经网络包TensorFlow,广泛应用于各大比赛的Xgboost等等等等。上述开源的包中,全部都支持Python。而对于其它语言来讲,上述包并不一定全部支持。由此也可以看到Python在数据挖掘领域中举足轻重的地位。
从实际使用的角度来讲,通过笔者对部分包的实际使用,对于分类、Logistics回归、传统回归等问题,上述包对效率和准确率均有十分大的提升。仅从效率角度比较,之前某项目宽表共40余万样本,480个字段,逐步回归用时2个小时,而另外一个项目通过使用xgboost的logistic Object,30余万样本,1700个字段,建模时间用时不到2分钟。(由于xgboost在各个数据挖掘竞赛中已经被广泛证实效果十分优秀,而且模型比较需要很长篇幅进行描述。所以本文仅从效率角度进行了比较,后续可以就模型比较单独写一篇公众号文,但就经验而言xgboost等算法效果通常不会比传统算法差)同时,与传统数据挖掘软件相比,Python还广泛应用于图像识别、语音识别、NLP等更丰富的数据挖掘领域。
可以看到,Python拥有应用场景广泛、开源免费、前沿算法支持、学习成本低、开发效率高等优质特点。通过这些特点,Python把遥不可及高高在上的大数据、数据挖掘、机器学习、深度学习等概念转化为每个人都可以学习、每个企业都可以实际应用的项目和程序。通过低成本的投入,可以满足更丰富的业务场景的需求、对现有业务场景的优化,帮助企业获得更高的利润并降低风险。
2.数据处理实例
对于大数据、数据挖掘的各种概念已经被炒的稀烂,类似上面写的软文一百度一大堆。作为一个干货满满的公众号,下面将从数据处理出发,从效率角度将Python及MySQL进行实际对比,展示Python对数据处理的强大能力。
背景
在数据挖掘第一步,通常会面临海量的贴源数据,也就是说一张表就有可能有上亿行数据。对于这种数据集的处理,在非集群的情况下,使用传统SQL数据库,需要通过建立索引、分表等技术才可能进行下一步处理,且效率很难保证。
如笔者曾经试图用单机MySQL(配置在下面测试中有截图,一个乞丐版的2014年mac pro)处理15g的单张表,共3亿+数据。但是发现导入进MySQL数据库都效率极低,而进行加索引或者简单的Groupby等操作更是基本无法完成。当然,通过分表处理理论上可以解决上述问题,但是代码量和效率也并不会十分迅捷。
对于上述问题,笔者最终采用Python的pandas包对数据进行分块读取,并使用pandas自带的Groupby、merge实现了与MySQL同样的功能,运行速度相比MySQL有了质的飞跃。
同时,Python在处理数据过程中,可以直接完成类似Excel的透视表功能,这个功能在建立宽表过程中十分有用,且是SQL并不支持的功能。
下面,将分别使用Python和MySQL对数据进行相同的处理,同时对MySQL是否加索引分别计算时间。由于本部分涉及代码,为了方便阅读,会先介绍软硬件配置及数据集,然后给出测试结果和结论,附录中会展示测试过程及代码。(由于时间和能力有限,也许笔者对Python和MySQL不能进行最优优化,结论不能十分严谨,但是结论也能适用于绝大多数企业的实际数据和硬件场景)
数据及环境介绍
使用数据取自网络公开数据,经过简单加工,数据集共3.79G, 5060w行,13列的csv文件。硬件配置:
涉及软件版本:Python 3.5,pandas(0.19.2),MySQL Community Server (GPL) 5.7.16。
下面笔者将分别从数据读取和SQL常用操作对数据进行对比。
测试结果及结论
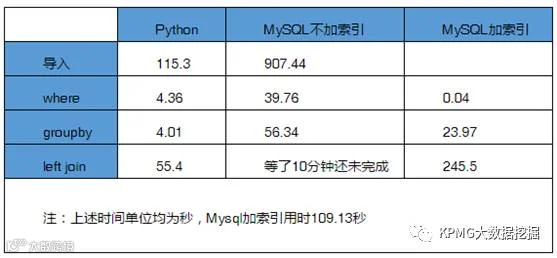
测试结论:在测试中,Python对于数据的处理速度均极大的超过了MySQL数据库。由于在测试中只是对数据进行了简单的处理,同时数据量也仅仅5000w量级,所以Python对数据的处理能力也只是展露了一小部分。而在实际的挖掘项目中,在面临着需要计算几千甚至上万特征值的情况下,通过Python将可以从代码量和运算速度两方面极大提高宽表制作效率,甚至完成传统SQL数据库难以完成的工作。
写在最后
通过文章第二部分的实验,可以看到身为免费开源的Python,在数据挖掘最基础的数据处理部分,已经远超传统方法。而这里展示的只是Python在数据挖掘中运用的冰山一角。从传统的统计模型到前沿的深度学习,从实际的生产环境到Kaggle竞赛,都充斥着Python的身影,这些都足以证明Python在数据挖掘领域的应用是多么广泛。
Google对TensorFlow的开源和社区化,让它成为深度学习里一颗璀璨的明珠,也让深度学习向前前进了一大步。如果您的企业想对数据挖掘想了解更多,欢迎您在公众号直接回复与我们联系,我们十分愿意和您共享我们知道的一切。
注:对于数据处理,Python的pandas包文档给出了十分详细的实例,其中包括与R、SQL和SAS语句的对比,如果您已经掌握R、SQL或者SAS,上手pandas将会是一件十分简单的事情。
与SQL对比的网址:http://pandas.pydata.org/pandas-docs/stable/comparison_with_sql.html
附录:过程及代码截图
数据读取
MySQL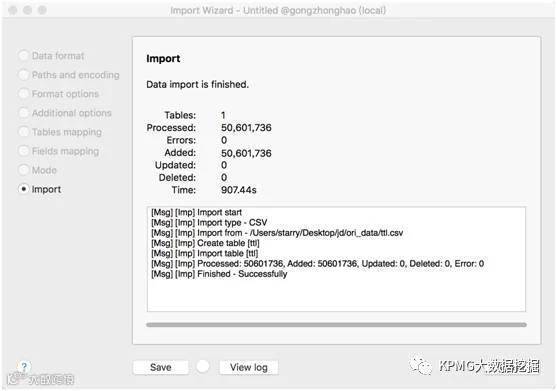
Python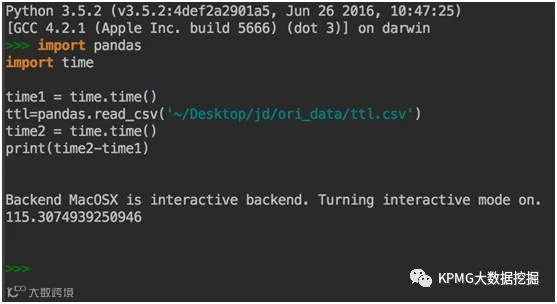
不加索引MySQL
where
groupby
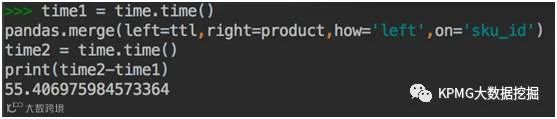
left join
加索引MySQL

where
groupby
left join
Python
where
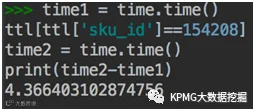
group by
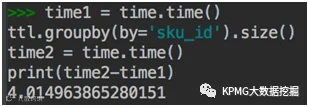
left join
长按二维码即可关注!也请随手推荐我们给你的小伙伴 ↓↓↓↓
