
本期【观视界】邀请到达观数据市场总监 孙亚彬
坐客“数字化行业峰会”向大家分享心得

孙亚彬
达观数据市场总监
拥有多年互联网行业产品和企业服务运营经验,专注于市场数据研究,对数字化发展有独到的眼光及见解,曾任连力资本创新事业部运营总监,现任达观数据市场总监,负责公司整体品牌市场推广及运营工作,负责公司政府及协会机构的深度合作,在客户项目运营上也具备完善的经验。
大家好,我是达观数据的市场总监孙亚彬。
达观数据是一家专注于文本智能化处理的企业,利用先进的文字语义自动分析技术,提供文本的自动化抽取、审核、纠错、搜索、推荐、写作等智能软件系统,让计算机代替人工完成业务流程自动化,大幅度提高企业的效率。所以呢,今天我想和大家一起谈谈文本智能处理的发展与应用。
我们达观数据是专注于长文本的分析处理,所谓的长文本也就是书面文本,比如合同、资讯、财报、文书等较长的文本,广泛地存在于企业中。
文档处理也是企业中最常见、最耗费人力、最需要自动化改造的场景,一个正常白领每天的工作时间有50%以上都是在和文字打交道,校对、撰写、填表等等,文本的自动智能化处理也是企业信息化发展的最重要一个方面。
随着人力成本的上升,文本技术的进步,文本智能化处理的市场机遇逐步显现,以我们达观服务的某知名保险公司为例,达观帮助其合同审核团队从800人降低到400人,而且双方期望最终能减少到100人,这对于企业来说节省了非常的支出,可以把人力有效利用到更有创造性价值的工作中去。
那么我们对于文本的智能化处理是如何实现的呢?
其实让计算机具备这些能力,就跟小时候老师教我们学语文一样,小学一年级的时候语文老师教我们认汉字,三千个常用汉字+很多很多的词,认识词以后会造句,然后是段落、句子,然后让计算机写文章,一篇文章由二十句话构成。
计算机也是一样,首先我们需要让计算机理解字和词,而中文几乎是所有语言中最难处理的一门语言,因为中文不像英文,词与词之间相对独立,句子的结构表达也十分规范,是非常标准的语言,而中文博大精深,同样一句话,不同环境,甚至不同语气,可能表达的意思都不一样,所以呢,让要计算机准确地做文本分析,第一步就是要进行词性分析,也就是中文分词,理解每个词的词性,是名词,动词,介词,还是量词等等。
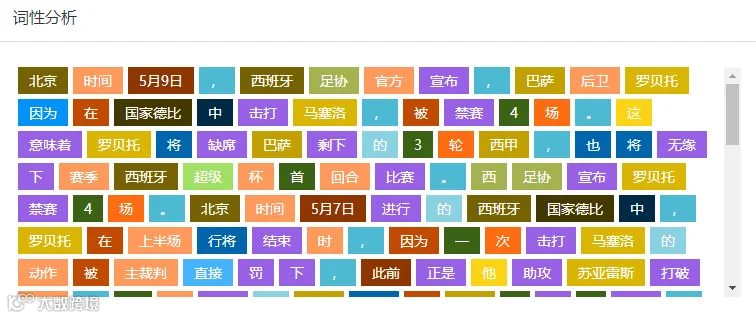
(点击放大可看更清晰)
词性的分析是为了识别文本中具有特定意义的实体,包括主要包括人名、地名、机构名、专有名词等。比如非常经典的一个案例就是“南京市长江大桥”,如果是“南京市/长江大桥”,那说的就是一个地名,如果是“南京/市长/江大桥”,那江大桥就变成一个人名了,所以说准确的分词和实体识别对语义理解非常重要,而准确的含义就需要结合上下文语境了。

(点击放大可看更清晰)
对字、词的理解完成以后,就需要让计算机去理解一个句子,处理句子我们使用依存句法,去分析分析语言单位内词语之间的搭配关系,揭示其句法结构,也就是我们上学的时候老师教的主谓宾定状补,这样,可以帮忙我们的计算机更好地理解你这句话的意思。
对句子分析的时候我们还会运用到语言模型,语言模型是通过计算词语搭配的概率分布来评估上下文连接的相对可能性。语言模型技术最直观的应用就是文本纠错,举个例子来说,计算机阅读了几万条新闻,每当提到“李克强”的时候,99.9999%的前面搭配都是“总理李克强”,那么当新的待处理的文本中如果因为笔误出现了总经理李克强,系统就是自动报警,觉得是不是有错误了,从而来帮助我们的进行纠错。
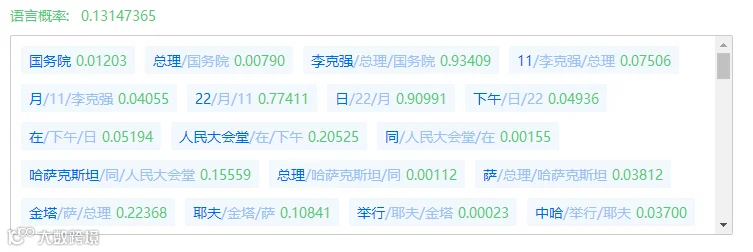
(点击放大可看更清晰)
句子讲完了,接下来就是长篇幅的文章了,计算在理解篇章级的文本的时候,经常运用的技术叫语义网络,所谓语义网络是指文本进行语义分析,提取出相互关联的实体关系,进而整体构建语义网络,并使用构建的网络对关键词进行联想,获取到与其相关的词语。
通俗来说就是让计算机具备像人一样去思考的能力,当我说起西游记的时候,你的脑海里会立马浮现孙悟空,猪八戒,四大名著,吴承恩等等这些信息,对于计算机也是同样如此,只有建立起非常复杂而庞大语义网络,具备了这样的知识体系,计算机才能更好地理解这段文本在讲述的内容。
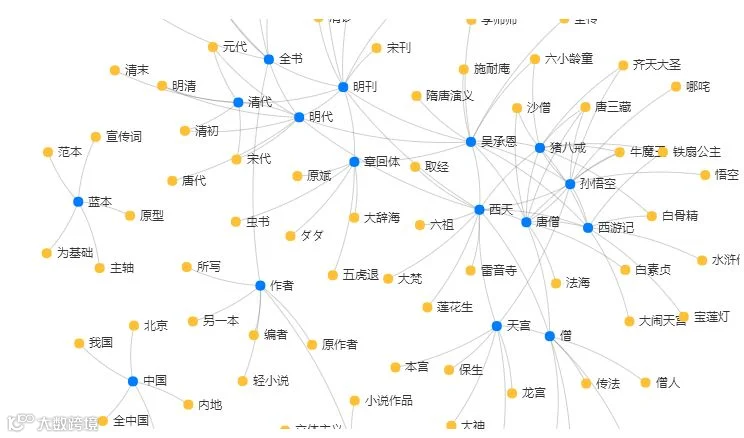
(点击放大可看更清晰)
通过以上从词性,到句法,到篇章的逐层深入的分析技术,我们的计算机已经具备了一定的文本智能化处理能力,那么这种能力有哪些具体的应用呢?
首先,我们的媒体,每天都是产生海量的新闻,计算机可以快速地对这些新闻进行标签提取,自动分类,这是讲体育的,这是讲娱乐的,计算机可以秒级地处理上万条资讯,看了新闻以后,我们会发表评论,那么我们可以会用户发表的评论进行文本审核,是不是广告,是不是色情内容,是不是反动言论等等,对于传媒来说是非常实际的运用。
最近我们也推出了一款产品,叫文档智能审阅系统,主要应用于我们企业内部的文本处理,在很多企业,尤其是制作、银行、保险、法律等行业类型企业,内部堆积了大量的文本数据,通过我们的系统,可以来帮助他进行文本数据的挖掘,从而可以帮助他们简化整个工作的流程,提高他们整体的运营效率。
举个例子来说,在银行的信贷部门,当有很多消费者申请借款,无论是提交的申请报告,还是银行签订的合同,都需要进行大量的内容审核。用人工进行审核会耗费大量的时间和精力,而且因为人的精力有限,工作效率的降低,让审计的准确率也随之降低。但对于基于数据处理的机器来说,就可以避免这样的问题,机器的效率会快很多,准确率也可以达到更高的水平。
我们的系统就是代替人来完成做机械化和重复性的工作。机器可以自动阅读文档内容,阅读合同,我们把关键核心信息进行提取,把可能存在的错误内容标识出来,这样审核人员就不需要检查整个文档,只要看标注出来的可能存在的错误信息便可,大大减少了人员的处理时间,也提升了整个的工作流程效率。
除了合同以外,人事部门的简历,客户部门的工单,产品部门的使用说明等等,这些常见的文本类型都可以进行处理,通过我们的系统将关键信息抽取出来以后,可以协助我们的业务人员进行后续的审核,纠错,比对,自动填表等等一系列工作。
所以我们说,今天的计算机在做文字自动化处理领域已经可以做很多意想不到的工作,这些工作都是非常有意义的,未来还会有更多的应用场景,尤其是机械性、重复性地文字操作工作,计算机的能力很快会超过人类。最近微软的一篇文章很火,说NLP将迎来黄金十年,我们也坚信,NLP会跟计算机视觉,语音识别一样,即将迎来爆发式的增长,我们也会和大家一起做好迎接未来的准备,谢谢大家!
-End-
本文为“数字化学会”会员单位成员原创文章
如需转载请联系本公众号
