

阿里妹导读
文章内容基于作者个人技术实践与独立思考,旨在分享经验,仅代表个人观点。
前言
Linux有一句经典名言:“Talk is cheap, show me the code。”
近期学习AI Agent开发时,理论知识密集输入却缺乏实感,如同搭建“空中楼阁”——看得见、摸不着。计算机工程的本质在于实践:听千遍不如看一遍代码,看一遍代码往往胜过百遍讲解。由此催生一个核心想法:“最好的学习资料是代码;既然学AI Agent开发,就让AI Agent本身帮我生成学习资料。”
本文项目代码主体由AI生成,作者角色为架构设计者与效果验收者。
说明:
- 本项目为纯学习型Demo,聚焦展示“理论背后的可运行代码”;
- 文中Agent概念涵盖LLM,不做LLM与Harness的严格区分;
- 不深入探讨设计哲学(如Skill渐进式披露),专注实现细节;
- Function Calling本质由Harness执行,LLM仅输出调用意图;它是Agent能力的地基,Skill、SubAgent、RAG等复杂能力均以Tool形式封装并交由LLM决策调用。
快速开始
本项目是一个基于Spring AI构建的AI Agent应用(纯学习用途),集成RAG检索增强生成、Function Calling工具调用、MCP协议、SubAgent子代理、Skill技能系统等核心能力。下文将围绕六大核心模块,解析其架构设计与关键实现。
代码仓库
GitHub地址:https://github.com/q644266189/aiagentdemo
克隆命令:git clone git@github.com:q644266189/aiagentdemo.git
环境要求
- Java 21+
- Maven 3.9+
核心模块
| 模块 | 说明 |
| AgentCore | 核心编排器,支持意图识别、记忆管理与大模型调用。 |
| ChatMemory | 对话记忆管理,采用三层上下文压缩策略:摘要压缩 → Assistant消息裁剪 → 滑动窗口。 |
| Tool(Function Calling) | 可插拔工具注册机制,通过InnerTool统一接口注册,由LLM自主决策调用。 |
| RAG | 完整检索增强生成流水线:文档加载 → 分块 → 向量化 → 向量存储 → 多路召回(语义+BM25+查询改写)→ RRF融合 → Rerank重排 → LLM生成。 |
| Command & Skill | 两种Markdown驱动的Prompt模板机制:Command由用户主动触发;Skill作为Tool由LLM决策调用。 |
| SubAgent | 拥有独立记忆的子代理,支持内部SubAgent与外部IdeaLab Agent两种形态。 |
| MCP | 双向MCP支持:作为Client连接外部MCP服务,作为Server对外暴露服务能力。 |
配置
编辑src/main/resources/application.properties,配置大模型API:
spring.ai.openai.base-url=https://open.bigmodel.cn/api/paas/v4
spring.ai.openai.api-key=你的API密钥
spring.ai.openai.chat.options.model=glm-4
spring.ai.openai.embedding.options.model=embedding-3访问
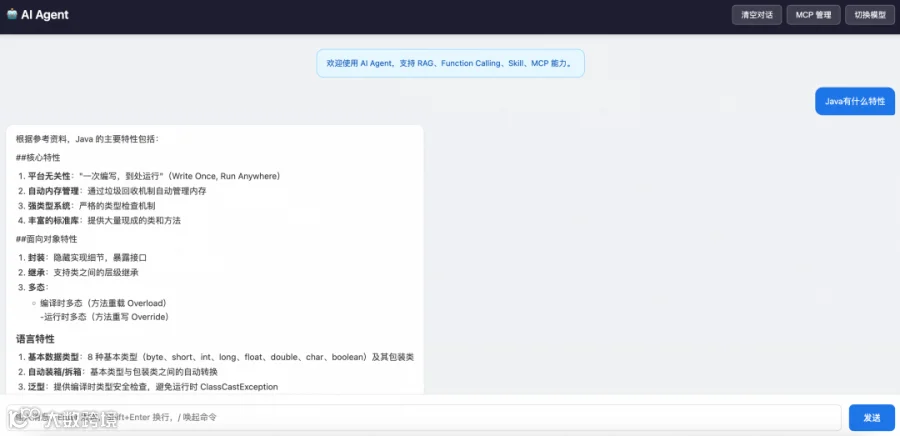
前端页面
启动成功后,浏览器访问:
http://localhost:8080项目内置完整Web聊天界面(src/main/resources/static/index.html),支持:
- 流式对话:实时逐字输出AI回复(SSE);
- Markdown渲染:自动渲染代码块、表格、列表等;
- 命令面板:输入
/唤起快捷命令列表; - 会话管理:支持清空对话历史。
API 直接调用
# 非流式对话
curl -X POST http://localhost:8080/api/chat \
-H "Content-Type: application/json" \
-d '{"message":"你好,介绍一下你的能力","sessionId":"test-001"}'
# 流式对话(SSE)
curl -X POST http://localhost:8080/api/chat/stream \
-H "Content-Type: application/json" \一、核心编排器:AgentCore
AgentCore是系统“大脑”,负责编排完整对话流程:意图识别 → RAG注入 → 记忆管理 → 模型调用 → 工具执行。
1.1 对话流程
用户输入
│
▼
意图识别(IntentRecognizer)
│ 判断:知识问答 or 通用对话?
▼
RAG 注入(RagService)
│ 若为知识问答,检索知识库并拼入上下文
▼
记忆管理(ChatMemory)
│ 自动摘要压缩 → 构建消息列表
▼
模型调用(ChatClient + ToolCallbacks)
│ LLM决策:直接回答 or 调用工具?
│ 若调用工具 → 执行 → 结果返回LLM → 继续决策(ReAct循环)
▼
返回最终回复核心方法AgentCore.chat():
public String chat(String sessionId, String userInput) {
ChatMemory memory = getOrCreateMemory(sessionId);
// 1. 意图识别
Intent intent = intentRecognizer.recognize(userInput);
// 2. 若为RAG意图,先检索知识库并注入上下文
if (intent == Intent.RAG && ragService.isKnowledgeLoaded()) {
String ragContext = ragService.query(userInput);
if (ragContext != null && !ragContext.isBlank()) {
String enrichedInput = "以下是从知识库中检索到的相关参考资料,"
+ "请结合这些资料回答用户的问题:\n\n"
+ ragContext + "\n\n用户问题:" + userInput;
memory.addMessage(new UserMessage(enrichedInput));
} else {
memory.addMessage(new UserMessage(userInput));
}
} else {
memory.addMessage(new UserMessage(userInput));
}
// 3. 构建Prompt并调用大模型(getMessages内部自动触发摘要压缩)
List<Message> messages = memory.getMessages();
Prompt prompt = new Prompt(messages, buildChatOptions());
ChatClient.ChatClientRequestSpec requestSpec = chatClient.prompt(prompt);
if (!toolCallbacks.isEmpty()) {
requestSpec.toolCallbacks(toolCallbacks.toArray(new ToolCallback[0]));
}
String response = requestSpec.call().content();
memory.addMessage(new AssistantMessage(response != null ? response : ""));
return response != null ? response : "";
}1.2 Agent Loop
Spring AI已内置Agent Loop,路径为:org.springframework.ai.chat.client.advisor.ToolCallAdvisor#adviseCall。
1.3 意图识别
IntentRecognizer通过LLM判断用户输入意图,当前支持:
RAG:需检索知识库后再作答;GENERAL:通用对话,直接交由LLM处理。
前置意图识别可避免无效RAG检索,显著节省向量检索与Rerank开销。
1.4 对话记忆:ChatMemory
每个sessionId对应独立ChatMemory实例,天然支持多客户端并发。
ChatMemory采用三层递进式上下文压缩策略,防止token溢出与成本失控:
第一层:摘要压缩(智能压缩)
当历史消息超16条时,自动调用LLM将早期消息总结为≤300字摘要,注入system prompt,原消息移除。
核心逻辑位于ChatMemory.getMessages()与compressIfNeeded():
public List<Message> getMessages() {
compressIfNeeded(); // 构建消息前自动压缩
List<Message> messages = new ArrayList<>();
if (systemMessage != null || (summaryText != null && !summaryText.isBlank())) {
String systemContent = systemMessage != null ? systemMessage.getText() : "";
if (summaryText != null && !summaryText.isBlank()) {
systemContent += "\n\n【以下是之前对话的摘要,请参考】\n" + summaryText;
}
messages.add(new SystemMessage(systemContent));
}
// ... 添加历史消息(跳过早期Assistant消息)
return Collections.unmodifiableList(messages);
}
private void compressIfNeeded() {
if (chatClient == null || history.size() <= COMPRESS_THRESHOLD_MESSAGES) {
return;
}
int compressEndIndex = history.size() - PRESERVE_RECENT_MESSAGES;
// 确保不在TOOL消息前截断
while (compressEndIndex < history.size()
&& history.get(compressEndIndex).getMessageType() == MessageType.TOOL) {
compressEndIndex--;
}
if (compressEndIndex <= 0) return;
List<Message> messagesToCompress = new ArrayList<>(history.subList(0, compressEndIndex));
String newSummary = SummaryCompressor.compress(chatClient, messagesToCompress, summaryText);
if (newSummary != null && !newSummary.isBlank()) {
this.summaryText = newSummary;
history.subList(0, compressEndIndex).clear();
}
}设计亮点:
- 内聚透明:压缩逻辑封装于
getMessages()内部,调用方无感知;SummaryCompressor为私有静态内部类; - 增量压缩:新压缩融合旧摘要,避免信息随多次压缩衰减;
- TOOL消息边界保护:截断时避开TOOL消息,确保其紧随对应ASSISTANT消息,维持工具调用上下文。
第二层:Assistant消息裁剪(精准裁剪)
仅保留最近3条Assistant回复。因LLM输出冗长,此策略显著降低token消耗。
第三层:滑动窗口(兜底保护)
当消息总数超maxRounds × 4时,丢弃最早消息,硬性保障上下文可控。
三层协同:摘要压缩优先(保信息)、Assistant裁剪持续(省token)、滑动窗口兜底(强约束)。
1.5 多会话隔离与运行时配置
- 多会话:通过
ConcurrentHashMap<String, ChatMemory>按sessionId隔离,支持高并发; - 运行时切换模型:通过API动态切换模型提供商(如智谱→通义千问),无需重启;
- 运行时调参:支持动态调整temperature、maxTokens、topP等推理参数。
二、Tool机制(Function Calling)
LLM负责“想”,Tool赋予其“做”的能力。LLM本身不执行调用,Agent服务端接收其工具调用意图后,完成真实执行并返回结果。
本项目基于Spring AI Function Calling,构建可插拔工具注册机制。
2.1 工具注册机制
所有工具实现统一接口InnerTool:
public interface InnerTool {
List<ToolCallback> loadToolCallbacks();
}启动时,Spring自动扫描所有InnerTool Bean,调用loadToolCallbacks()收集并统一注册至AgentCore。新增工具仅需实现该接口,零侵入扩展。
ToolCallbackBuilder提供简洁API,将工具名、描述、JSON Schema参数定义及执行函数组装为Spring AI标准ToolCallback。
2.2 工具调用流程
用户:"杭州今天天气怎么样?"
│
▼
LLM分析意图,决定调用get_weather工具
│
▼
Spring AI自动执行工具:get_weather({"city": "杭州"})
│
▼
工具返回结果:"杭州,晴,22°C"
│
▼
LLM基于结果生成最终回复:"杭州今天天气晴朗,气温22°C,适合出行。"Spring AI ChatClient内置ReAct循环:LLM可连续调用多个工具,直至信息充分后生成终稿,全程对开发者透明。
2.3 内置工具一览
| 工具名 | 功能 | 说明 |
knowledge_search |
知识库检索 | 将RAG能力封装为Tool,供LLM主动调用 |
create_sub_agent |
创建子代理 | 创建拥有独立记忆的SubAgent |
chat_with_sub_agent |
与子代理对话 | 在SubAgent独立上下文中继续对话 |
destroy_sub_agent |
销毁子代理 | 释放SubAgent资源 |
call_ideas_{name} |
调用IDEAs应用 | 调用外部IdeaLab平台AI应用(支持多实例) |
{skill_name} |
执行技能 | 由Markdown文件定义的Skill,动态注册 |
{mcp_tool_name} |
MCP工具 | 从外部MCP Server发现并注册的工具 |
get_weather |
天气查询 | 示例工具 |
get_stock_price |
股票价格查询 | 示例工具 |
三、RAG模块:检索增强生成
RAG(Retrieval-Augmented Generation)使Agent具备基于私有知识库问答的能力。
3.1 RAG完整流水线

3.2 文档分块策略
分块质量决定检索效果。项目提供两类策略:
确定规则分块(Definite)
| 策略 | 原理 | 适用场景 |
TextSplitter(默认) |
递归语义分块:按标题→段落→句子→固定字符优先级切分 | 通用文档,兼顾语义完整性 |
FixedSizeSplitter |
按固定字符数切分 | 结构不明确的纯文本 |
ParagraphSplitter |
按段落(连续换行)切分 | 段落结构清晰的文档 |
SentenceSplitter |
按句子(句末标点)切分 | 需细粒度检索的场景 |
SlidingWindowSplitter |
滑动窗口切分,相邻块重叠 | 需保留上下文连续性的场景 |
智能分块(Intelligent)
| 策略 | 原理 | 适用场景 |
SemanticChunkSplitter |
基于语义相似度判断切分点 | 语义边界模糊的长文本 |
PropositionSplitter |
将文本拆解为独立命题 | 需精确事实检索 |
AgenticSplitter |
使用LLM判断最佳切分方式 | 复杂混合格式文档 |
默认使用TextSplitter(递归语义分块),块大小500字符,重叠50字符。
3.3 检索流程核心代码
RagService.query()封装完整检索流程:
public String query(String question) {
// 1. 多路召回(语义 + BM25 + 查询改写,共9个候选)
List<Document> candidates = multiRecaller.recall(question, RECALL_CANDIDATE_COUNT);
// 2. Rerank重排(取最相关的3个)
List<Document> relevantDocuments = llmReranker.rerank(question, candidates, TOP_K);
// 3. 拼接上下文
StringBuilder contextBuilder = new StringBuilder();
for (int i = 0; i < relevantDocuments.size(); i++) {
contextBuilder.append("【参考资料 ").append(i + 1).append("】\n");
contextBuilder.append(relevantDocuments.get(i).getContent()).append("\n\n");
}
return contextBuilder.toString().trim();
}3.4 召回策略
单一召回存在盲区,项目采用“多路召回 + RRF融合”方案:
| 召回器 | 原理 | 擅长 |
SemanticRetriever |
基于EmbeddingModel的向量余弦相似度检索 | 语义相近但措辞不同的查询 |
Bm25Retriever |
基于BM25算法的关键词匹配(TF-IDF变体) | 精确关键词匹配 |
QueryRewriteRetriever |
先用LLM将问题改写为3种表达,再分别向量召回 | 扩大语义覆盖面 |
三路结果通过RRF(Reciprocal Rank Fusion)算法融合:
// MultiRecaller核心逻辑
public List<Document> retrieve(String query, int topK) {
Map<String, Double> rrfScores = new HashMap<>();
Map<String, Document> keyToDocument = new LinkedHashMap<>();
for (Recaller retriever : retrievers) {
List<Document> results = retriever.retrieve(query, PER_ROUTE_CANDIDATE_COUNT);
// RRF公式:score(d) = Σ 1 / (k + rank),k=60为平滑常数
accumulateRrfScores(results, rrfScores, keyToDocument);
}
return rrfScores.entrySet().stream()
.sorted(Map.Entry.<String, Double>comparingByValue().reversed())
.limit(topK)
.map(entry -> keyToDocument.get(entry.getKey()))
.toList();
}RRF仅依赖排名,天然适配异构算法结果融合。
3.5 Rerank重排
多路召回后得9个候选文档,经专用Rerank模型精排,选取最相关3个。
3.6 向量存储
VectorStore为轻量级内存向量存储,基于Spring AI EmbeddingModel生成向量,以余弦相似度检索。适用于中小规模知识库;生产环境可替换为Milvus、Pinecone等专业向量数据库。
四、Command与Skill:两种Prompt模板机制
Command与Skill均为Markdown定义的Prompt模板,但设计理念与调用方式不同。
4.1 Skill:LLM自主调用的工具
Skill文件采用YAML Front Matter + Prompt模板格式:
---
name: summarize
description: 对用户提供的文本内容进行摘要总结
---
请对以下文本进行摘要总结,提取核心要点:
{{input}}SkillManager启动时扫描classpath:skill/*.md,解析元数据后由SkillTool转换为ToolCallback并注册。LLM依据description自主判断是否调用。
4.2 Command:用户主动调用的快捷指令
Command文件为纯Prompt模板,文件名即命令名:
请对以下代码进行 Code Review,从代码质量、潜在Bug、性能、可读性等维度给出改进建议:
{{input}}CommandManager启动时扫描classpath:command/*.md并加载至内存。用户通过REST API(POST /api/command/execute)指定命令名执行。
4.3 核心区别对比
| 维度 | Command | Skill |
| 设计理念 | 用户快捷指令 | LLM可调用的工具 |
| 文件格式 | 纯Prompt模板 | Front Matter(name+description)+ Prompt |
| 是否注册为工具 | ❌ 不注册 | ✅ 注册为ToolCallback |
| 调用触发方 | 用户主动指定命令名 | LLM根据description自主决策 |
| 执行路径 | 用户 → Controller → AgentCore | 用户 → AgentCore → LLM决策 → SkillTool |
| 适用场景 | 用户明确所需功能 | 需LLM理解上下文后智能判断 |
一句话总结:Command是“用户告诉Agent做什么”,Skill是“Agent自己判断该做什么”。两者互补——Command提供确定性入口,Skill提供智能化扩展。
五、SubAgent:独立记忆的子代理
5.1 为什么需要SubAgent
部分任务需独立上下文。例如“帮我写一篇技术文章”,需多轮完善,但不应污染主对话记忆。SubAgent为此而生。
5.2 记忆隔离机制
SubAgent核心是记忆隔离:每个SubAgent拥有独立ChatMemory实例,与主Agent完全解耦。
public SubAgent(String id, String name, String systemPrompt, ChatClient chatClient) {
this.memory = ChatMemory.forSubAgent(); // 独立记忆!
this.memory.setSystemPrompt(systemPrompt);
// ...
}SubAgent共享主Agent的ChatClient(即同一模型连接),但对话历史完全独立,确保:
- SubAgent内部多轮对话不影响主对话上下文;
- 主Agent可同时管理多个互不干扰的SubAgent;
- SubAgent销毁后,其记忆同步释放。
5.3 交给LLM:Tool
SubAgent能力通过3个Tool暴露给主Agent,本质为Function Calling,由LLM决策启用:
| 工具 | 参数 | 说明 |
create_sub_agent |
name、system_prompt、task | 创建SubAgent并执行首个任务 |
chat_with_sub_agent |
agent_id、message | 与已有SubAgent继续对话 |
destroy_sub_agent |
agent_id | 销毁SubAgent,释放资源 |
主LLM根据上下文自主决策是否创建SubAgent,整个生命周期(创建→多轮→销毁)均由LLM通过Tool调用驱动。
六、MCP:连接一切外部服务
MCP(Model Context Protocol)是Anthropic提出的开放协议,用于AI应用标准化接入外部工具与数据源。本项目同时实现MCP Server(对外暴露能力)与MCP Client(连接外部服务)。
6.1 MCP Server:对外暴露知识库检索能力
通过SimpleMcpServer对外提供知识库检索工具,供其他AI应用通过MCP协议调用:
工具:knowledge_query
| 参数 | 类型 | 说明 |
keyword |
String | 检索关键词 |
category |
String | 知识分类(java_basic / jvm / concurrent / spring / design_pattern / all) |
maxResults |
int | 返回最大结果数,默认3 |
内部调用RagService执行检索并格式化返回,使本项目RAG能力可被任意支持MCP的AI应用复用。
6.2 MCP Client:动态连接外部MCP服务
McpClient封装连接外部MCP Server的完整逻辑:
核心方法McpClient.connect():
public ToolCallback[] connect(String serverUrl) {
McpSyncClient mcpClient;
McpSchema.InitializeResult initResult;
// 优先尝试Streamable HTTP,失败后回退SSE
try {
mcpClient = connectWithStreamableHttp(serverUrl);
initResult = mcpClient.initialize();
} catch (Exception streamableException) {
mcpClient = connectWithSse(serverUrl);
initResult = mcpClient.initialize();
}
// 自动发现远程工具
SyncMcpToolCallbackProvider provider = SyncMcpToolCallbackProvider.builder()
.mcpClients(mcpClient).build();
ToolCallback[] toolCallbacks = provider.getToolCallbacks();
// 持久化URL,下次启动自动恢复
store.add(serverUrl);
return toolCallbacks;
}关键特性:
- 传输协议自动适配:优先Streamable HTTP(2025-03-26规范),失败自动降级SSE(2024-11-05规范);
- 工具自动发现:连接成功后自动获取远程工具,转换为
ToolCallback注册至Agent; - 持久化与自动恢复:URL存入
mcp-servers.json,应用重启时自动重连。
运行时动态管理(REST API):
| 接口 | 方法 | 说明 |
/api/manage/mcp/connect |
POST | 连接新MCP服务,工具立即可用 |
/api/manage/mcp/disconnect |
POST | 断开MCP服务,移除对应工具 |
/api/manage/mcp/list |
GET | 查看所有MCP服务及其工具列表 |