
ZJU REAL Lab团队投稿 | 量子位
3B、7B小模型如何成为智能体专家?
浙大、美团龙猫团队与清华大学推出SKILL0,提出技能内化(Skill Internalization)理念:小模型应将技能内化为参数本能,而非依赖推理时外部调用。

这一思路源自人类学习过程:从参照说明书操作过渡到凭肌肉记忆自主执行。
SKILL0通过上下文强化学习和课程学习机制,逐步撤除技能参考,使模型参数掌握过程性知识,实现零样本直接上手。
技能增强的局限性
Skills作为结构化知识和可执行资源集合,增强了大模型推理时调用外部技能的能力。但研究指出此范式不适用于小模型,原因如下:
- 检索噪声致命:可能引入无关信息污染有限上下文,极度依赖外部检索质量。
- Token开销爆炸:技能增多导致多轮对话中token急剧累积。
- 缺乏深度理解:模型仅照本宣科,撤除技能后能力显著退化。

△ 技能增强(左)vs技能内化(右)。传统方案需实时检索技能文档;SKILL0训练时用技能,推理时完全自主。
从技能增强到技能内化
SKILL0复刻人类学技能过程:从参照说明书到自主执行。核心创新分为三步:
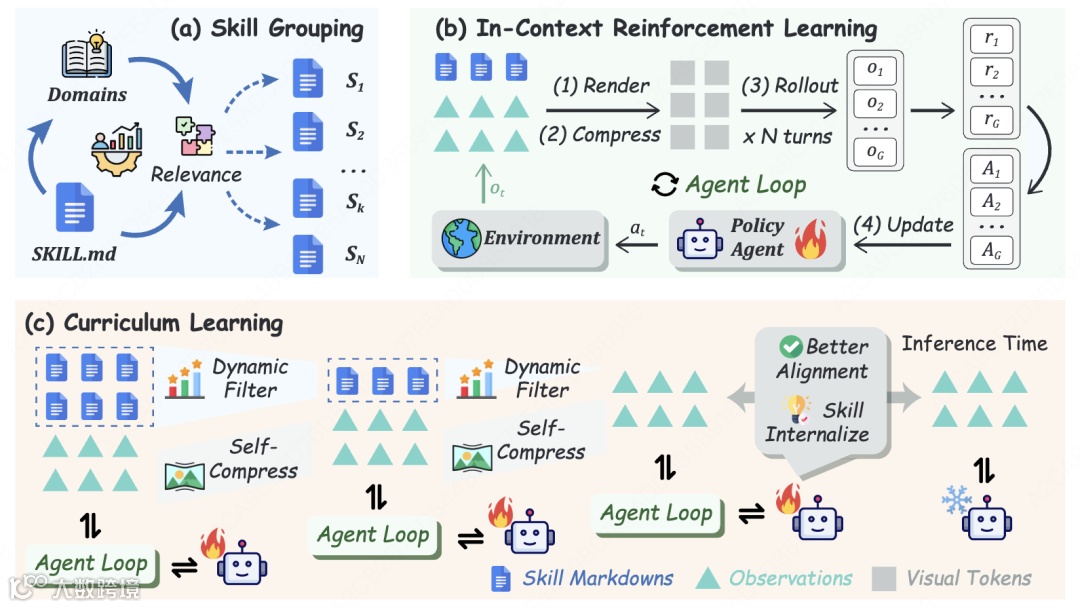
图2:SKILL0框架全景。(a)相关性驱动技能分组;(b)带技能的Agent训练循环;(c)训练动态课程。
建立技能脚手架
训练前构建层级SkillBank:
- 通用技能:跨任务策略,如"先探索再行动"
- 任务特定技能:领域专门知识,如"搜索任务的实体属性查询"
按相关性分类的Markdown文件作为训练参考,支持后续课程学习筛选。
上下文强化学习:让模型真学会
SKILL0在训练时提供技能上下文,但推理评估时完全撤除。为降低Token开销,技能信息经视觉编码器压缩为图片格式,保留结构语义的同时大幅减少文本冗余。
模型同步优化环境奖励和自压缩奖励,推动参数高效更新:

动态课程学习
训练分阶段线性衰减技能预算。以ALFWorld为例(6个技能文件、3个阶段),预算序列[6,3,0]。每阶段执行在线筛选:
- 评估帮助度:间隔10步对比有无技能的准确率差
- 过滤排序:仅保留帮助度>0的技能,按值降序排列
- 按预算选取:选择高排序技能文件
训练现象表明:早期模型未有效利用技能(帮助度低),中期学会利用(帮助度上升),后期完全内化(帮助度回落)。
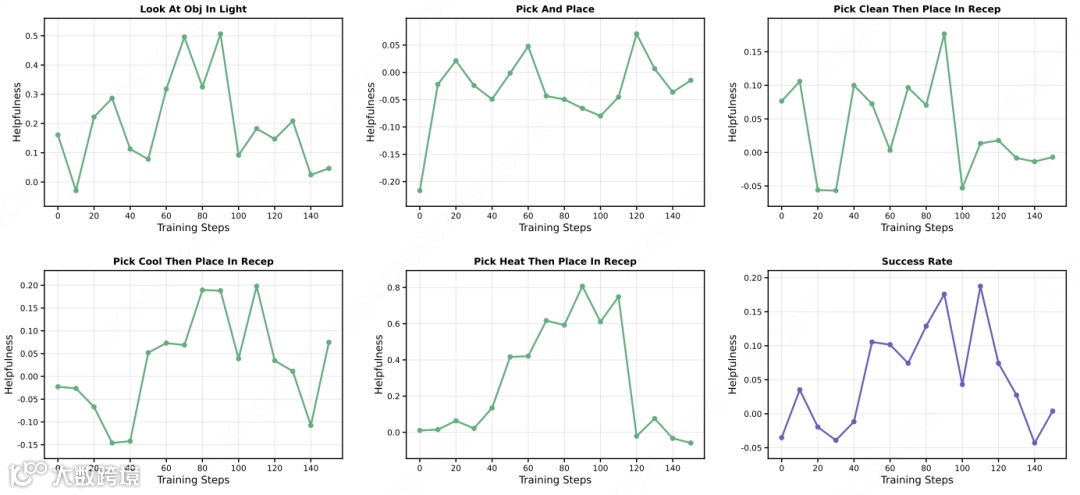
实验数据

ALFWorld任务:3B模型SKILL0平均成功率87.9%,较基线高9.7%,优于带技能SkillRL(82.4%)
Search-QA任务:3B模型平均分40.8%,比基准高6.6%,与SkillRL持平
7B模型优势显著:ALFWorld成功率89.8%,大幅领先GPT-4o(48.0%)和Gemini-2.5-Pro(60.3%)
Token效率提升明显:ALFWorld每步仅0.38k token,Search-QA仅0.18k,成本降低超5倍。
训练曲线证实技能内化:初期带技能模型占优,但SKILL0随训练推进持续反超,最终稳定领先。

消融实验关键发现:训练全程满技能[6,6,6]会导致推理撤技能后性能暴跌12.3点;而渐进课程[6,3,0]反使性能提升1.6点。动态课程机制至关重要——移除过滤性能降2.7%,随机选技能则大跌13.7%。


总结
当前Agent研究多聚焦技能检索优化,SKILL0另辟路径:通过内化将技能转化为模型参数。这使小模型无需实时调用即可胜任复杂任务。
该方法不替代需实时更新的知识(如API变更),但对稳定行为模式,"外部工具"到"内在能力"的转变是智能体自主化的核心突破。
论文标题:
SKILL0: In-Context Agentic Reinforcement Learning for Skill Internalization
论文地址:
https://arxiv.org/abs/2604.02268
项目代码:
https://github.com/ZJU-REAL/SkillZero