
在之前的多篇文章中,我们曾多次深入探讨过数据本体(Ontology)这一概念,以及它如何作为底层架构支撑起现代企业的数据与业务中枢。如果说传统的数仓架构关注的是“如何存储和计算数据”,那么本体架构关注的则是“如何让数据表达真实的物理与业务世界”。
近日,在 Palantir 举办的 DevCon 5 开发者大会上,Palantir Ontology 团队负责人 Landon Carter 带来了一场名为《深度剖析:高级本体架构》的硬核技术分享。在这场演讲中,他不仅揭示了本体语言的最新特性:包括派生属性、接口以及扩展的安全原语,更重要的是,他深刻指出:本体设计绝不仅仅是一项系统需求,它是一门极其严谨的专业工艺,是软件工程在数据架构领域的延伸。

本文将以专业视角,为您全面梳理本次演讲的核心内容与技术观点。我们将保持原演讲的逻辑脉络,并在此基础上增加深度的技术点评,带您一窥全球顶尖数据公司是如何将复杂的业务挑战转化为产品特性的,以及企业应当如何在其组织内部真正利用好这些高级特性。
一、 本体的演进历程与底座优势:从黄金数据表到 AI 优先
在深入技术细节之前,我们需要理解本体架构并非一蹴而就,它经历了一个清晰且漫长的演进周期。在业务落地的实践中,本体架构的发展通常可以划分为三个阶段:
第一阶段:黄金数据表
这是构建本体的基石阶段,其核心痛点在于数据集成。企业内部通常存在大量孤立、异构的数据源(如 ERP、CRM、各类流水线系统)。此阶段的目标是将这些分散的数据进行清洗、对齐与整合,形成统一可信的“单点真相”,为后续将数据映射到本体对象中做好基础准备。

第二阶段:运营决策与动态反馈
一旦数据就绪,系统便进入了动态运作阶段。此时的本体不再是静态的视图,而是开始捕捉企业运行的“动力学特征”。通过引入动作、逻辑)、函数以及各类机器学习模型的集成,本体具备了“读写”能力。它吸收数据流,在系统内执行大规模计算与逻辑判断,进而输出决策,并将这些操作反写回现实世界的业务系统中,产生实质性的业务影响。

第三阶段:AI 优先战略
随着大型语言模型(LLM)的爆发,本体系统演进到了智能化自动化的新纪元。如今,大模型被深度集成到本体中,开始将前一阶段积累的业务动力学逻辑进行“机械化”与“自动化”。AI 智能体可以直接调用本体中的动作与函数,实现复杂业务流的自主驱动。

【专家点评】值得注意的是,Palantir 在处理复杂数据(尤其是非结构化数据)方面的能力,并非最近才随着 AI 浪潮兴起。追溯其最早服务于情报和国防领域的 Gotham 产品,就可以看到其长期致力于解决信息提取的难题。过去,情报分析师需要耗费数小时从 PDF 和各类文档中手动提取数据;而 Gotham 的核心使命就是帮助他们将这些非结构化数据“本体化”。 如今,有了 LLM 的加持,处理非结构化数据的效率有了质的飞跃。但 Palantir 高管明确指出了一条行业护城河:没有任何一家纯粹的 AI 实验室能够凭空“变出”一个具有如此深度、历经实战检验的底层本体系统。 大模型需要极其严谨的上下文和语义锚点才能在企业级应用中发挥作用,而这正是经过十余年演进的本体架构所独有的价值。

二、 驱动本体设计的四大核心原则
本次演讲最核心的观点之一,是明确了“本体本质上就是驱动企业运转的底层软件”。既然本体是软件,那么它的设计就理应遵循计算机科学与软件工程领域沉淀多年的经典设计原则。

前方部署工程师在面对各行各业的复杂场景时,总结出了以下四大本体设计原则。这四大原则是理解后续高级功能的理论基础:
原则 1:领域驱动设计
这是所有原则中最核心的一条。本体设计的首要任务是精准捕捉数据的语义意图。本体中的数字孪生对象,应当与现实世界中的物理实体或业务概念实现一对一的映射。 开发者常犯的错误是,将本体直接建构为底层数据表的翻版(虚拟映射)。这种做法是极其脆弱的。正确的做法是,剥离底层数据的存储形态,专注于业务的真实面貌。当数据和本体的结构能够完美捕捉语义信息(合理的属性、符合常理的链接关系)时,不仅人类开发者在调用 API 时会感到极其直观,AI 智能体在理解和导航这些数据时也会如鱼得水。
原则 2:勿用重复 / 三次法则
在代码世界中,DRY 原则是常识。在本体世界亦然。如果你在系统中构建了三个结构相似、功能雷同的本体对象,那么就到了必须重构、提取公共业务流和公共数据特征的时候了。 这种高度抽象和复用的设计,对于大模型上下文管理至关重要。设想一下,如果不做重构,AI 智能体面对查询需求时,需要在 12 个极其相似、只是被不同团队在略微不同的场景下使用的本体对象中进行艰难的辨别。而通过接口或统一对象整合后,系统就有了唯一的、权威的数据表述,大幅降低了 AI 幻觉和检索错误率。
原则 3:对扩展开放,对修改封闭
借用 Java 和面向对象编程中著名的 SOLID 原则,本体的核心业务数据模型必须是“封闭”的:即核心的定义、关键的关联关系需要被锁定,防止内部其他团队在协同开发时意外破坏核心业务流。与此同时,这个架构必须是“开放”的——允许企业内的其他开发者基于核心数据模型进行继承与扩展,开发新的微服务和工作流,而不干扰底层基座。
原则 4:协变与逆变 / PECS 原则
这是一个源自 Java 泛型的深层次开发原则。在本体中,它的业务含义是“即插即用的本体灵活性”。通过接口设计,开发者可以构建出极具弹性的消费工作流和函数逻辑。不论传入的是基类接口还是具体的派生类对象,工作流都能安全地处理数据交互。这一原则赋予了企业级本体应对未来业务形态变幻的极高适应力。
【专家点评】将软件工程领域的经典范式(DDD、SOLID、DRY 等)系统性地引入数据建模领域,是近年来数据架构演进的一大趋势。传统的数据工程师往往更关注 SQL 的性能、管道的吞吐量和表结构的范式化;但在 AI 时代,数据不仅是供报表读取的静态记录,更是 AI Agent 进行逻辑推理和操作的“沙盒”。因此,必须用编写企业级 Java/C++ 后端架构的严谨度来设计本体模型,这也是未来高阶数据架构师的必修课。
三、 核心高级特性深度剖析:从问题到产品
在确立了四大原则之后,演讲通过具体的特性展示,阐述了 Palantir 如何将这些理念产品化,落地到具体的复杂业务场景中。
1. 接口机制的全面引入
接口功能允许开发者将属性和动作抽象出来,使得应用工作流不再与某个特定的底层数据对象强绑定,而是与实现了该接口的多个对象集群兼容。

场景示例:假设你需要开发一个管理“建筑物”的业务应用。在本体中,可能有“餐厅”、“办公楼”和“体育馆”三种独立的对象类型,它们都实现了 Building 接口。 此外,本体支持多重继承。例如,“体育馆”除了实现 Building 接口,还可以同时实现 Schedulable Resource(可调度资源)接口。
业务价值:开发者只需编写一次面向 Building 的分析流,就能同时或有选择地应用于这三类建筑;同时,在开发赛事排期系统时,也能无缝复用面向 Schedulable Resource 的逻辑。这完美契合了DRY(避免重复)和开闭原则。
泛型支持(PECS 的体现):在开发 OSDK(对象软件开发工具包)应用时,如果函数签名设定为接受 ? extends Event(任何继承自事件的对象集),系统就能在运行时安全地接受“NBA比赛”对象集或“开发者大会演讲”对象集,实现了极高层次的代码复用。
2. 结构体、归约器与主字段
真实世界的数据往往伴随着极其复杂的元数据。例如,一个简单的“地址”属性,不仅包含街道、城市、邮编等子字段,还包含“此数据由系统接入还是手动录入”、“创建人是谁”、“最后修改时间是什么”等溯源信息。

结构体的作用:早在 Gotham 时代的动态本体管理器(POM)中,Palantir 就确立了将这些关联信息打包为单个 Struct 属性的范式。现在 Foundry/AIP 也全面支持这一特性。特别是在大模型场景下,例如集成在 Slack 中的智能问答机器人,本体不仅需要记录 LLM 的最终回答,还需要将“引用的文档 URL”、“相关历史消息”以及“LLM内部的推理链路”打包为结构体存储,以供后续的合规审计和质量分析。
解决语义冲突的方案:归约器与主字段:然而,过多的元数据会违反“领域驱动设计”中追求纯粹语义的原则。为了解决这一矛盾,引入了另外两个特性:
1)归约器: 由于本体支持记录数据的历史变更(例如一个人随时间推移拥有多个地址),归约器允许系统在大多数 UI 视图和基础查询中,自动提取“最后修改时间最近”的那条记录,将复杂的时间序列数据“归约”为当前最相关的单条数据。
2)主字段: 对于包含大量元数据的地理位置结构体,可以将其中的核心 Geopoint 字段指定为“主字段”。这意味着在空间分析流和地图 UI 中,整个结构体表现得就像一个单纯的经纬度坐标,完全屏蔽了底层的溯源元数据噪音。只有在分析师进行深度下钻时,附加信息才会显现。
设计原则映射: 通过这种机制,既利用 Struct 保证了数据的完整与内聚(DRY 原则),又利用 Reducers 和主字段维持了高层次的语义纯粹度(DDD 原则)。
3. 派生属性:告别脆弱的数据去范式化
在构建组织架构图等具有复杂图谱关系的应用时,经常会遇到这样的需求:需要在主管的对象属性中,直接看到他下属员工的姓名列表以及下属的数量。
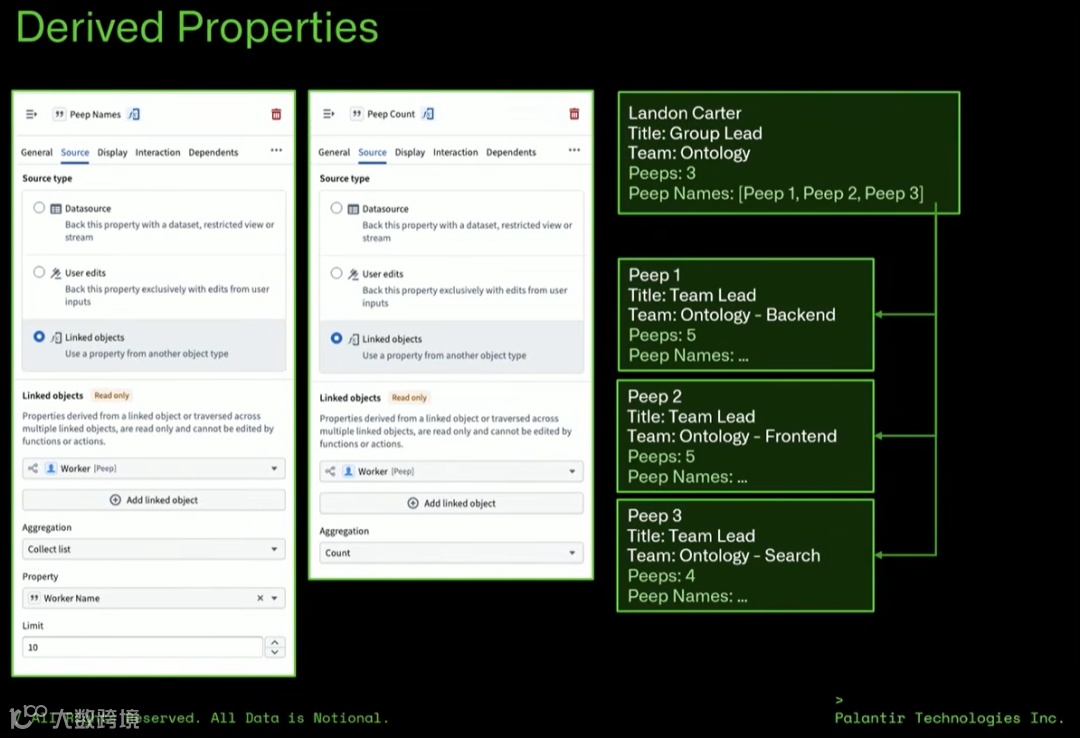
传统做法的弊端:传统数据工程往往倾向于去范式化,即通过预计算,将这些下属的名字强行作为字符串数组写入主管的底层数据表中。这种做法虽然查询极快,但会导致数据极其脆弱:一旦下属改名或人员发生调动,必须触发复杂的级联更新去修改主管记录,极易造成数据不一致。
派生属性的破局:派生属性允许底层数据保持高度的范式化。数据依旧乖乖待在原本的员工对象里。开发者在本体层面定义语义业务逻辑(例如:“沿着 lead_peep 关系链遍历,聚合所有关联员工的姓名并计数”)。这一机制不仅避免了数据的冗余存储,更将“业务逻辑层”彻底从“数据物理层”剥离,是领域驱动设计(DDD)在本体构建中的巅峰体现。
4. 安全原语的无限极拓展与实体解析
数据的安全与权限管控,是企业级平台(特别是国防和医疗领域)的绝对生命线。演讲中展示了本体安全架构如何突破传统的访问控制极限:

Level 0: 数据集级别(所有患者数据整体加密)。
行级: 某位 VIP 患者的整行记录被设为机密(如通过受限视图或 OSP 策略控制)。
单元格级: 结合行与列控制,某个患者的姓名是公开的,但其特定的一条“医疗诊断笔记”列在这个特定行上是加密的。
子单元格级: 通过派生属性拆解数组类型字段,即便在一个包含 5 条患者备注的数组里,系统也能精准地对其中 1 条极其敏感的备注(例如“怀疑家属投毒”)打上独立的加密标记,而不影响其余 4 条备注的可见性。
高阶场景:实体解析:当系统通过算法发现存在数据重影时(例如记录里同时存在“Diana Mercer”和“Diane Mercer”,且被判定为同一个人),系统能够通过派生属性和对象链接,虚拟合并这两个实体。最令人惊叹的是,合并后的对象依然能完美继承原有两个对象分别持有的底层安全级别。这种将复杂安全校验与语义视图完美融合的能力,堪称数据治理工艺的艺术品。
5. 对象支撑的链接类型
在许多业务流中,实体之间的关联并不是简单的“一线牵”,关联本身也包含丰富的业务信息。例如,员工和项目组之间的关系。

技术实现:系统在底层可能需要一个中间对象 Venture Staffing 来记录关联元数据(比如该员工是在哪个时间段参与的该项目)。然而,在某些宏观视角的应用流中,分析师并不关心中间的加入时间,只想单纯看到“员工 -> 项目”的直接链接。
灵活的语义表达:“对象支撑的链接”允许开发者在底层利用中间对象记录时间戳等复杂业务信息,但在前端和宏观本体视图中,能够暴露出一条“直连”的关系线。这再次印证了领域驱动设计(DDD)的灵魂——既不丢失底层的工程颗粒度,又能在顶层提供符合直觉的语义呈现,将中间辅助对象优雅地“隐藏”。
结语:在 AI 时代,以重塑软件工程的姿态重塑数据基座
回顾这场技术演讲,Landon Carter 反复强调了四个词:领域驱动设计、勿用重复、开闭原则、协变与逆变。
这是一次极具启发性的宣告:数据架构的开发,已经正式步入了高级软件工程的深水区。
过去,企业花费海量预算搭建各种数据湖、数据湖仓,却往往只得到了一座座堆满结构化或半结构化文件的“数据矿山”。业务人员无法直接理解表结构,大模型在复杂的关联关系前产生严重的幻觉,归根结底是因为缺乏一层“翻译”现实世界的语义网络。
Palantir 本体架构的高级特性(接口化、派生逻辑、细胞级安全控制、结构体打包),向我们展示了什么是真正的“专业工艺”。它不仅仅是在连接数据,更是在代码层面还原整个企业的运转逻辑与物理真实。
在这个大模型席卷一切的时代,各类 AI 智能体正如雨后春笋般涌现。但决定这些智能体是只能作为“玩具助手”还是能真正成为“数字员工”的根本,不在于模型的参数规模有多大,而在于其扎根的土壤:底层数据本体是否具备足够的语义精确度、逻辑封闭性和安全可靠性。
可以说,精通本体架构的高级设计原则,将其视作打磨核心商业软件般去进行迭代,将是下一代企业级数字化转型的胜负手。在 AI 优先的洪流中,真正有价值的不再是那些“生冷”的数据集,而是能够精准表述并驱动现实业务运行的“动态本体孪生”。