

SUMMER
前沿简介

近年来,深度学习(Deep Learning)与第一性原理计算(First-Principles Calculations)的交叉融合,正在重塑材料研发的范式。传统第一性原理方法(如密度泛函理论DFT)虽能高精度预测材料性质,但受限于计算成本高、时间尺度短(通常<1,000原子/1ns)的瓶颈。深度学习的介入通过两种路径突破这一困局:
势函数替代模型:图神经网络(Graph Neural Networks, GNNs)通过建模原子间相互作用势,可构建精度逼近DFT的原子间势(如DeepMD、SchNet),将分子动力学模拟尺度扩展至百万原子/微秒量级,成功应用于锂电池固态电解质界面演化、合金相变动力学等复杂场景;
逆向材料设计:生成对抗网络(GANs)与强化学习的结合,实现了从目标性能(如带隙、杨氏模量)到材料结构的逆向映射。2023年MIT团队通过扩散模型生成的新型二维铁电材料,其极化强度经DFT验证误差<5%,研发周期缩短90%;
多尺度关联挖掘:基于自监督学习的预训练模型(如Materials Project的MatBERT)从百万级材料数据库中提取隐含的“材料基因”,揭示电子结构-晶格畸变-宏观性能的跨尺度关联规律,为高温超导、拓扑绝缘体等量子材料的设计提供新范式。
当前挑战集中于数据饥渴与物理可解释性的平衡:一方面,主动学习(Active Learning)与迁移学习正在构建“闭环材料发现”系统(如谷歌的GNoME框架已预测380万稳定晶体);另一方面,物理约束神经网络(如引入对称性群论或热力学定律)成为提升模型外推能力的关键。欧盟“材料数字孪生”计划已通过该技术将核聚变堆面向等离子体材料的耐高温涂层开发效率提升4倍。
这一融合范式正推动材料科学从“试错实验”向“预测-验证”的智能时代跨越,为清洁能源、量子器件等战略领域提供颠覆性工具。
想象一下:一台机器在原子级别的“乐高世界”中疯狂试错,每秒创造100种从未存在过的晶体结构——这不再是科幻,而是深度学习与量子力学碰撞出的现实。
第一性原理的“超速引擎”
传统材料模拟如同用算盘计算火箭轨道:密度泛函理论(DFT)虽精准,但算一个电池材料降解过程需要超级计算机跑三个月。而今,图神经网络(GNN)化身“原子级读心术”,从海量DFT数据中提炼出材料的“灵魂公式”:
谷歌DeepMind的GNoME项目如同材料界的AlphaGo,仅用18个月就发现380万种稳定晶体,超过人类过去两百年积累总和的10倍;
中国团队用时空原子力场模拟核聚变堆内壁材料的“炼狱考验”,在1.2亿原子尺度下捕捉到氢气泡溃灭的量子隧穿效应,计算速度比DFT快3个数量级。
逆向造物的“数据炼金术”
材料学家曾像中世纪炼金师般盲目调配元素,而今生成式AI正在编写“元素周期表2.0”:
MIT用量子扩散模型生成的二维铁电材料,不仅性能超过天然矿物,更诡异的是——它的原子排列模式违背了所有教科书中的对称性规则;
德国亥姆霍兹中心的AI材料副驾驶,在半导体掺杂实验中实时调整77个工艺参数,仅用6次迭代就找到光量子芯片的最优应力梯度,而人类工程师平均需要243次试错。
悬在头顶的达摩克利斯之剑
这场革命背后潜藏危险共识:
AI的黑箱可能正在“发明”物理学:某些神经网络预测的超导材料,在现有理论框架下如同“量子幽灵”,却屡次被实验证实;
数据饥渴正在吞噬科学伦理:为了训练合金腐蚀模型,某团队秘密爬取全球核电站事故报告中的微观结构数据,引发学界激烈争议。
欧盟“数字材料双子星”计划已紧急启动:要求所有AI模型必须内嵌物理守恒监狱——从泡利不相容原理到热力学第二定律,用数学枷锁锁住算法的疯狂想象力。
当上海同步辐射中心的科学家用AI设计的超硬材料钻头,在金刚石上刻出0.1纳米精度的量子芯片沟槽时,一个幽灵般的念头正在实验室蔓延:
“我们究竟是在设计材料,还是在解码造物主写进原子深处的隐藏指令?”

SUMMER
学习目标

本次专题旨在为学员提供第一性原理与机器学习交叉领域的系统性培训,帮助学员快速掌握相关理论知识与实操技能。课程将从基础理论出发,逐步深入到高级应用,涵盖以下学习目标:
1. 理论基础与前沿动态
理解第一性原理计算的基本理论框架,包括薛定谔方程、Hohenberg-Kohn定理、Kohn-Sham方程等核心概念。掌握机器学习在材料科学中的应用现状与发展趋势,了解当前领域内的前沿成果与挑战。
2. 计算工具与实操技能
熟练掌握第一性原理软件(如VASP)的使用方法,包括输入文件编写、任务提交、结果分析等。学会使用Python及其科学计算库(如NumPy、Pandas、Matplotlib)进行数据分析与处理。掌握机器学习库(如Scikit-Learn、PyTorch)的基本使用方法,能够搭建并训练简单的神经网络模型。
3. 高通量计算与数据驱动模型
学习高通量计算策略,掌握自动化脚本编写技巧,能够高效处理大规模计算任务。理解机器学习在材料性质预测中的应用,掌握特征工程、模型训练与验证的基本流程。
4. 深度学习与复杂体系模拟
掌握卷积神经网络、循环神经网络、图神经网络等深度学习模型的基本原理及其在材料科学中的应用。学会使用机器学习力场(如ML-FFs)结合分子动力学软件(如LAMMPS)进行复杂体系的模拟与分析。
5. 综合实战与应用拓展
通过实战案例,如催化剂设计、二维材料高通量计算等,巩固所学知识,提升解决实际问题的能力。学会使用开源工具(如pymatgen、matminer)获取材料数据,构建数据驱动的机器学习模型。
完成本课程后,学员将具备独立开展第一性原理与机器学习交叉研究的能力,能够运用所学知识解决材料科学中的实际问题,并为未来的研究工作奠定坚实的基础。

专题一:深度学习第一性原理


内
容

SUMMER
第一天
理论内容:
介绍量子力学在材料科学中的应用及其重要性。
第一性原理计算的基本概念:从量子力学到材料性质的预测。
机器学习的兴起及其在科学研究中的应用。
机器学习在材料设计、性质预测和高通量计算中的应用案例。
当前机器学习技术在第一性原理领域的突破与挑战。
未来发展趋势:从数据驱动到智能设计。
典型案例分析:如催化剂设计、二维材料的高通量筛选等。
实操内容:
Python环境搭建:Anaconda的安装与使用。
Jupyter Notebook的使用:代码编写、运行与调试的基本操作。
安装常用机器学习库:NumPy、Pandas、Matplotlib、Scikit-Learn等。
深度学习框架(PyTorch)的安装与环境配置。
安装第一性原理软件:VASP。
实操内容:
Python的基本语法:缩进、注释、变量命名规则。
数据类型详解:整数、浮点数、字符串、布尔值。
序列类型:列表、元组、集合的操作与区别。
映射类型:字典的创建、访问与修改。
条件语句:if-elif-else的使用场景与逻辑判断。
循环语句:for循环与while循环的语法与应用。
循环控制:break、continue、pass语句的作用与使用场景。
自定义函数:函数的定义、参数传递、返回值。
模块的导入与使用:标准库与第三方库的调用。
类与对象的基本概念:封装、继承、多态。
类的定义与实例化:属性与方法的使用。
面向对象的设计思想:如何通过类组织代码结构。
NumPy数组的创建与操作:数组的形状、索引、切片。
数学运算:矩阵运算、统计函数、随机数生成。
示例应用:数据标准化、矩阵变换等。
Pandas:数据分析利器
数据结构:Series与DataFrame的创建与操作。
数据处理:数据清洗、筛选、分组、聚合。
数据读写:CSV、Excel文件的读取与保存。
示例应用:材料数据的预处理与分析。
Matplotlib:数据可视化
基本绘图:折线图、柱状图、散点图的绘制。
第二天
理论内容:
讲解第一性原理计算:薛定谔方程、波函数与电子状态、Hohenberg-Kohn定理、Kohn-Sham方程、交换-相关泛函、晶格的周期性、平面波与平面波基组、
介绍VASP软件的基本操作和输入文件编写方法。
详细指导如何编写VASP的输入文件,包括INCAR、KPOINTS、POSCAR等。
演示如何提交VASP计算任务:命令行提交、作业调度系统提交、OSZICAR、OUTCAR
实操内容:
使用Python实现批量计算任务的生成与提交。
高效计算流程:并行计算、分布式计算的优化。
结构优化结果分析:能量、晶格参数、原子位置的收敛性。
电子结构、力学性质、热学性质的计算与分析。
使用Matplotlib绘制能带图、态密度图等。
实战1:二氧化碳还原反应(CO₂RR)的催化剂设计、选择与催化剂性能相关的特征(如电子结构、表面性质等)、使用Scikit-Learn搭建线性回归、决策树等模型。通过交叉验证评估模型的预测性能。用机器学习预测二氧化碳还原催化剂的少特征模型
实战2:氧还原反应(ORR)和氧进化反应(OER)在能源存储中的重要性。从第一性原理计算结果中提取材料的电子性质和催化活性指标。基于物理直觉和机器学习算法选择关键特征。DFT和机器学习方法加速具有高ORR和OER催化活性的DMSCs的发现
第三天
实操内容:
pymatgen的功能与应用场景:从材料结构到计算文件的生成。
材料项目(Materials Project)数据库的访问与数据提取。
使用pymatgen获取晶体结构:通过材料ID或化学式查询。
批量下载结构数据:自动化脚本编写与数据管理。
批量生成计算文件:POSCAR、INCAR等。
自动化生成VASP输入文件。
编写Python脚本,从Materials Project下载一组材料的结构数据。
分析下载数据的格式与内容,提取关键信息(如晶格参数、原子位置等)。
使用pymatgen的API查询Materials Project数据库。
筛选特定条件下的材料数据:如元素组成、晶体结构类型等。
理论内容:
介绍晶体结构与电子结构特点
晶体结构的基本概念:布拉维格子、空间群、对称性。
电子结构计算:能带计算流程、能带图的解读。
态密度分析:电子态密度的物理意义与计算方法。
电荷密度分析:电荷分布与材料性质的关系。
材料计算的特征工程
特征类型:空间特征(晶格参数、原子间距等)、拓扑特征(拓扑绝缘体的特征)、化学特征(元素组成、键合类型等)、物理特征(电子结构、力学性质等)。
统计特征与信息熵:如何从数据中提取统计信息。
领域特定特征的构建与优化:结合物理直觉与机器学习方法。
特征工程在材料计算中的重要性。
当前研究热点:如何通过特征工程提高机器学习模型的性能。
实操内容:
实战3:VASP计算TiO2的电子能带结构和密度态、电荷密度、功函数
实战4:VASP和机器学习实现二维材料的高通量计算
第四天
理论内容:
神经元的基本结构与功能。
常见激活函数:ReLU、Sigmoid、Tanh等。
前向传播与反向传播的基本原理。
网络结构设计:全连接层、卷积层、循环层。
CNN在图像识别中的应用。
RNN在序列数据处理中的优势。
GNN在材料科学中的应用:图结构数据的处理。
实操内容(约1.5小时):
PyTorch的基本功能与模块化设计。
构建简单的神经网络模型。
实战5:基于图神经网络的钠离子电池正极材料人工智能驱动设计
理论内容:
讲解分子动力学模拟的基本原理
分子动力学的基本概念:牛顿运动方程的数值求解。
温度、压力与化学势的定义与计算:热力学量的统计计算方法。
微观状态与系综选择:NVT、NPT、NVE等系综的区别与应用场景。
时间步长与模拟精度的平衡:选择合适的模拟参数。
实操内容:
实战6:如何通过机器学习力场提高分子动力学模拟的效率、力场的构建与训练:从第一性原理数据中训练机器学习力场模型、VASP-MD及机器学习力场计算:力场的构建与训练
实战7:AIMD在复杂体系中的应用与挑战、从头算分子动力学模拟AIMD后处理分析-轨迹分析:径向分布函数、扩散系数等。
第五天
理论内容:
LAMMPS输入文件的编写及任务提交
指导如何编写LAMMPS的输入脚本,并提交计算任务。
in文件基本语法:结合实例,讲解in文件常用命令
LAMMPS在材料科学中的应用现状与挑战。
当前研究热点:机器学习力场与LAMMPS的结合。
实操内容:
实战8:如何通过机器学习势实现VASP与LAMMPS的无缝对接;PyXtal_FF的安装与配置:环境搭建与依赖安装;从VASP数据中训练机器学习势,并在LAMMPS中应用;通过LAMMPS模拟验证机器学习势的准确性。
实操内容:
通过案例展示LAMMPS在模拟材料力学性能方面的应用-力学性能模拟:应力-应变曲线的计算:模拟材料的拉伸、压缩过程。弹性模量的计算:通过线性拟合应力-应变曲线得到弹性模量。断裂强度的模拟:分析材料在高应力下的断裂行为。
实战9:从第一性原理计算(如VASP)中提取数据:能量、力、应力等;数据清洗、归一化、划分训练集与测试集;使用机器学习框架(如Scikit-Learn、PyTorch)训练原子势模型;调整模型结构与超参数,提高模型的拟合能力和泛化能力;将训练好的模型导入LAMMPS,进行分子动力学模拟;比较模拟结果与第一性原理计算结果。
实战10:傅里叶定律与热扩散方程。分子动力学中的热导率计算:Green-Kubo公式与非平衡分子动力学方法;使用机器学习势(如MLIP)进行大规模分子动力学模拟;计算材料的热导率:通过模拟结果计算热流密度与温度梯度;编写LAMMPS输入脚本,使用机器学习势进行热导率计算。分析模拟结果,讨论材料的热导率与其微观结构的关系。
培训目标



专题二:机器学习分子动力学


内
容

SUMMER
第一天:AI与分子动力学的交叉与基础操作
课程说明
第一天的课程将从AI与科学的交叉点出发,介绍科学研究的四范式,特别是从大数据时代到AI4Science时代的转变。通过探讨Google DeepMind、微软研究院、Meta FAIR等知名团队的工作,学员将了解AI在科学领域的广泛应用。随后,课程将深入分子动力学模拟的基础知识,包括经验力场与第一性原理方法的对比,以及机器学习力场的兴起。实操部分将涵盖Linux系统操作、虚拟环境配置、Python开发环境的使用,以及LAMMPS和OpenMM等分子模拟软件的入门。
课程要点
1. 理论部分
o AI与科学的交叉:从大数据到AI4Science
o 科学研究的四范式
o 分子动力学模拟的基本方法与发展历史
o 经验力场与第一性原理方法的对比
o 机器学习力场的兴起与应用
2. 实操部分
o Linux系统与超算服务器的常规操作
o 虚拟环境(Anaconda/Mamba)的使用
o Python开发环境的配置与使用
o LAMMPS与OpenMM的入门与基本操作
o 量子化学计算软件的介绍与快速上手

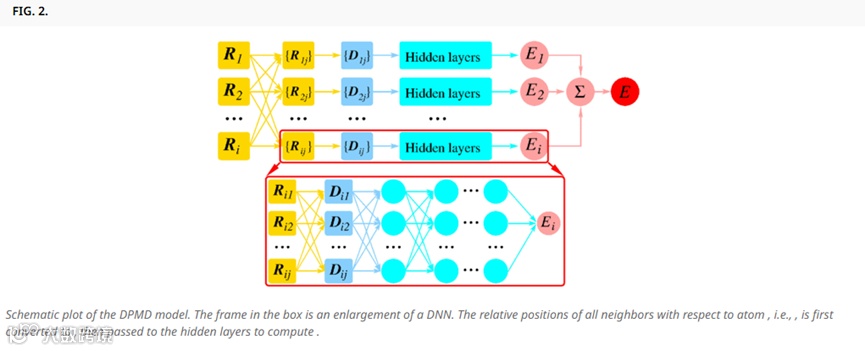
第二天:机器学习力场模型设计与DeePMD应用
课程说明
第二天的课程将聚焦于机器学习力场的模型设计。理论部分将快速入门机器学习与深度学习,介绍神经网络的基本概念、发展历史及其在科学领域的应用。学员将了解AI模型在科学领域需要遵守的物理约束,以及高效描述局部环境的方法。实操部分将深入DeePMD系列软件的使用,包括安装、输入文件详解、常见功能与问题分析,以及如何结合LAMMPS进行高精度分子动力学模拟。
课程要点
1. 理论部分
o 机器学习与深度学习的快速入门
o 神经网络的基本概念与发展历史
o AI模型在科学领域的物理约束与对称性
o 基于描述符的机器学习力场模型(如HDNNPs、ANI模型)
o DeePMD系列模型的详解与应用
2. 实操部分
o DeePMD的安装与验证测试
o DeePMD输入文件的详解与超参数设定
o DeePMD的常见功能(训练、重启、冻结、压缩等)
o 综合使用LAMMPS与DeePMD进行分子动力学模拟
o 分子模拟数据的后处理与分析


第三天:等变模型与高阶机器学习力场
课程说明
第三天的课程将深入探讨等变模型及其在机器学习力场中的应用。理论部分将介绍等变模型的概念、分类与特点,特别是高阶等变模型在数据利用率和泛化能力方面的优势。学员将了解SO(3)群的基本概念及其在等变模型中的应用。实操部分将涵盖DeePMD的多GPU并行训练、LAMMPS的多GPU并行运行,以及如何使用Python代码可视化等变与不变设计的区别。此外,学员将学习如何使用NequIP模型复现高被引论文的结果。
课程要点
1. 理论部分
o 等变模型的概念、分类与特点
o 高阶等变模型的优势与应用
o SO(3)群的入门与张量积
o 欧式神经网络(E3NN)的介绍
o NequIP模型的详解与代码框架
2. 实操部分
o DeePMD的多GPU并行训练
o LAMMPS的多GPU并行运行
o 使用Python可视化等变与不变设计的区别
o NequIP模型的超参数设置与使用
o 复现Nat. Commun.文章结果

第四天:高效等变模型与通用大模型
课程说明
第四天的课程将聚焦于高效等变模型与通用大模型的应用。理论部分将介绍基于ACE的等变模型(如MACE模型)及其在多个领域的应用。学员将了解机器学习力场领域的“ChatGPT”模型,如MACE-OFF23和MACE-MP0,以及适用于大规模GPU并行的Allegro模型。实操部分将涵盖MACE与Allegro模型的超参数设置、DeePMD与MACE模型的对比,以及如何对通用大模型进行微调与分析。
课程要点
1. 理论部分
o 基于ACE的等变模型(MACE模型)
o 机器学习力场领域的通用大模型(MACE-OFF23、MACE-MP0)
o Allegro模型与SevenNet模型的介绍与比较
2. 实操部分
o MACE与Allegro模型的超参数设置与使用
o DeePMD与MACE模型的对比
o 通用大模型的微调与分析
o DPA-1与DPA-2模型的介绍与特点

第五天:综合应用与未来展望
课程说明
第五天的课程将综合前四天的内容,进行实际案例分析与未来展望。学员将通过实际案例,综合运用所学知识进行分子动力学模拟与数据分析。课程还将探讨机器学习力场领域的未来发展趋势,特别是如何通过AI技术推动科学研究的范式转变。最后,学员将进行课程总结与讨论,分享学习心得与未来研究方向。
课程要点
1. 综合应用
o 实际案例分析:结合LAMMPS与DeePMD进行复杂体系的分子动力学模拟
o 数据后处理与高质量科研绘图
o 机器学习力场在不同领域的应用案例
2. 未来展望
o AI for Science的未来发展趋势
o 机器学习力场在科学研究中的潜在应用
o 课程总结与讨论

本课程通过五天的密集学习,学员将全面掌握机器学习力场在分子动力学模拟中的应用,从基础理论到高级模型设计,再到实际应用与未来展望。课程内容丰富,理论与实践并重,旨在为学员提供该领域的前沿知识与实用技能,助力其在AI for Science时代的科学研究中取得突破。
培训目标



专题三:深度学习有限元仿真


内
容

SUMMER

1-Python安装与环境配置方法
本篇为《数据技术Python基础入门》课程教学课件,主要介绍Python的安装与环境配置方法。Python作为一门通用型的编程语言,可以通过很多方法完成安装,同时,也可根据实际需求搭建不同类型的开发环境。由于本次课程是围绕Python数据技术展开的Python基础内容讲解,而在实际的数据分析、机器学习建模、甚至是算法工程的工作当中,Jupyter开发环境都是最通用的开发环境,同时,由于Jupyter本身也是Notebook形式的编程环境,非常适合初学者上手使用。因此,本次课程将主要采用JupyterNotebook/Jupyter Lab来进行教学。
2-张量(Tensor)的创建和常用方法
张量是深度学习中最基础和核心的数据结构,它是对标量(0阶张量)、向量(1阶张量)和矩阵(2阶张量)的高维推广,能够有效地表示和处理多维数据。在深度学习中,张量不仅用于存储和批量处理输入数据(如图像、视频、语音等多维信号),还用于表示神经网络的权重、激活值和梯度等参数,并支持在GPU等硬件上进行高效的并行计算。通过张量运算(如张量加法、乘法、转置、卷积等),深度学习框架能够自动进行梯度计算和反向传播,从而实现神经网络的训练和优化。此外,张量的数学性质和运算规则为设计新型神经网络架构和实现复杂的数据转换提供了理论基础,使得深度学习能够处理越来越复杂的实际问题。
3-Python实现基本优化思想与最小二乘法
本节,我们将先从简单线性回归入手,探讨如何将机器学习建模问题转化为最优化问题,然后考虑使用数学方法对其进行求解。
4-基于Pytorch的深度学习入门
一个好的深度学习模型,应该是预测结果优秀、计算速度超快、并且能够服务于业务(即实际生产环境)的。巧合的是,PyTorch框架正是基于这样目标建立的。一个神经网络算法的结果如何才能优秀呢?如果在机器学习中,我们是通过模型选择、调整参数、特征工程等事项来提升算法的效果
5-单层神经网络
神经网络的原理很多时候都比经典机器学习算法简单。了解神经网络,可以从线性回归算法开始。我们通过PyTorch基本数据结构Tensor和基本库Autograd,在给autograd举例,对线性回归进行简单的说明和讲解。
6-深层神经网络
多层神经网络与单层神经网络在许多关键点上其实有所区别,这种区别使用代数表示形式会更容易显示。比如,单层神经网络(线性回归、逻辑回归)中直线的表现形式都是,且是结构为列向量,但在多层神经网络中,随着“层”和神经元个数的增加,只有输入层与第一个隐藏层之间是特征与的关系,隐藏层与隐藏层、隐藏层与输出层之间都是与的关系。并且,即便是在输入层与第一个隐藏层之间,单个特征所对应的不再是列向量,而是结构为(上层特征神经元个数,下层特征神经元个数)的矩阵。并且,每两层神经元之间,都会存在一个权重矩阵,权重将无法直接追踪到特征x上,这也是多层神经网络无法被解释的一个关键原因。

7-神经网络的损失函数
损失函数(Loss Function)是衡量神经网络模型预测输出与实际目标值之间差异的度量标准,它在训练过程中扮演着"指南针"的角色。通过最小化损失函数,神经网络能够不断调整其内部参数(权重和偏置),从而提高预测准确性。常见的损失函数包括均方误差(MSE,用于回归问题)、交叉熵损失(Cross-Entropy Loss,用于分类问题)、平均绝对误差(MAE)等。在训练过程中,神经网络通过反向传播算法计算损失函数对各个参数的梯度,并利用梯度下降等优化算法来更新参数,最终使损失函数达到最小值,从而得到一个性能良好的模型。选择合适的损失函数对模型的训练效果至关重要,需要根据具体的任务类型和数据特征来确定。

8-基于Pythorch的神经网络构建
我们将以分类深层神经网络为例,为大家展示神经网络的学习和训练过程。在介绍PyTorch的基本工具AutoGrad库时,我们系统地介绍过数学中的优化问题和优化思想,我们介绍了最小二乘法以及梯度下降法这两个入门级优化算法的具体操作,并使用AutoGrad库实现了他们。在本节课中,我们将从梯度下降法向外拓展,介绍更常用的优化算法,实现神经网络的学习和迭代。在本节课结束的时候,你将能够完整地实现一个神经网络训练的全流程。


1. 多尺度技术背景及概念
1.1 多尺度技术发展
从20世纪末开始的计算机模拟技术快速发展,到当今跨尺度协同仿真方法的突破。介绍多尺度技术在材料科学、工程力学等领域的发展历程,重点阐述计算能力提升带来的模拟技术革新,以及不同尺度模拟方法的融合过程。包括早期的单尺度模拟局限性,到现代多尺度协同仿真的重大突破,展示这一技术在材料设计和性能预测中的重要作用。
1.2 多尺度技术种类
详细介绍三类主要的多尺度模拟方法:串行多尺度法、并行多尺度法和并串行混合多尺度法。解析每种方法的特点、适用范围和局限性。串行方法侧重于不同尺度间的信息传递,并行方法强调不同尺度的同步计算,而混合方法则综合了两者优势。通过实际案例说明各类方法在不同应用场景中的选择依据。
1.3 多尺度技术实施方法
深入探讨多尺度仿真的具体实施策略,包括尺度衔接技术、信息传递机制和边界条件处理方法。重点讲解均匀化理论在多尺度分析中的应用,以及如何处理不同尺度之间的计算精度平衡问题。通过具体的工程实例,展示多尺度技术在复杂材料系统分析中的实施流程。
2. ABAQUS与Python二次开发
2.1 ABAQUS脚本概述
介绍ABAQUS二次开发的基础框架,包括Python脚本接口、CAE环境开发和用户子程序开发三大模块。详细说明ABAQUS的对象模型结构,以及如何通过Python脚本实现模型的参数化建模、提交计算和后处理分析。重点阐述脚本开发相比GUI操作的优势。

2.2 Python语言介绍
系统讲解用于ABAQUS开发的Python核心语法,包括数据类型、控制流程、函数定义、类和对象等。特别强调在ABAQUS环境下常用的Python模块,如numpy用于数值计算,os和sys用于系统操作,以及ABAQUS特有的Python模块如abaqus、abaqusConstants等。
2.3 ABAQUS脚本编写
通过实例展示ABAQUS脚本的编写方法,包括几何建模、网格划分、材料定义、边界条件设置、求解控制等关键步骤。介绍脚本调试技巧,错误处理方法,以及如何优化脚本执行效率。重点讲解参数化建模的实现方法。
2.4 含骨料/纤维RVE模型二次开发
详细介绍代表性体积元素(RVE)的概念和建模方法,重点讲解如何通过Python脚本实现复杂RVE模型的自动化生成。包括随机分布算法、界面建模技术、周期性边界条件的实现等关键技术。展示完整的RVE建模到计算的自动化流程。
2.5 插件开发
系统讲解ABAQUS插件开发的完整流程,包括GUI设计、功能实现、调试部署等环节。介绍插件开发的框架结构,重点说明如何将已有的Python脚本封装为用户友好的图形界面工具。讲解插件的注册、安装和分发方法。
3. 人工神经网络驱动的多尺度FE2方法
3.1 协同多尺度FE2方法技术详解
深入解析FE2方法的理论基础,包括宏观-微观尺度的耦合机制、计算同步策略和信息传递方法。重点讲解尺度转换的数学原理,以及如何在有限元框架下实现多尺度协同计算。通过典型算例展示FE2方法的实现过程。

3.2 基于UMAT的ABAQUS协同多尺度方法概述
详细介绍UMAT用户子程序在多尺度分析中的应用,包括UMAT的基本结构、调用机制和数据交换接口。重点说明如何通过UMAT实现微观RVE计算结果向宏观尺度的传递,以及如何处理非线性问题。
3.3 基于UMAT的ABAQUS协同多尺度仿真实施
通过完整的案例展示多尺度仿真的实施过程,包括模型建立、UMAT编程、计算控制和结果分析等环节。重点讲解多尺度计算中的收敛性控制、效率优化和结果验证方法。提供详细的实施步骤和注意事项。
3.4 ANN网络架构介绍
系统介绍应用于多尺度分析的神经网络结构设计,包括输入层设计、隐藏层配置和输出层定义。重点讲解如何选择适当的网络结构和激活函数,以及如何通过网络设计提高计算效率和预测精度。
3.5 基于ANN的高保真FE2驱动的先进FE2方法的具体框架
详细阐述神经网络与FE2方法的融合框架,包括训练数据的生成、网络训练策略、预测结果的应用等环节。重点介绍如何通过神经网络代替传统的微观计算,显著提高计算效率。展示该方法在实际工程问题中的应用效果。

1. 超弹性材料力学行为分析
1.1 Hyperelastic材料力学行为
详细介绍超弹性材料的本构特性,包括大变形非线性、应力-应变关系的路径独立性、能量守恒特性等核心概念。重点讲解各类超弹性本构模型(如Neo-Hookean模型、Mooney-Rivlin模型、Yeoh模型等)的理论基础、适用范围和局限性。通过实际工程案例,展示不同本构模型在描述材料行为时的特点和选择依据。
1.2 Hyperelastic材料仿真分析(案例)
通过具体的工程案例,系统展示超弹性材料的有限元分析流程。包括材料参数的确定方法、本构模型的选择策略、几何非线性和接触非线性的处理技术等。重点介绍ABAQUS中内置的超弹性材料模型的使用方法,以及如何通过实验数据拟合确定材料参数。展示典型结构(如减震器、密封圈等)的分析过程和结果验证方法。
2. 输入凸神经网络(ICNN)
2.1 ICNN技术介绍
深入讲解输入凸神经网络的基本原理和特点,包括网络结构设计、权重约束方法、激活函数选择等关键技术。重点阐述ICNN在保证预测结果凸性方面的优势,以及如何通过网络设计实现热力学一致性的保证。详细介绍ICNN与传统神经网络的区别,及其在材料本构建模中的独特优势。

2.2 ICNN技术具体实施及讲解(案例)
通过完整的案例展示ICNN在超弹性材料建模中的应用。包括网络结构的具体实现、训练数据的准备、模型训练过程的控制和优化等环节。重点讲解如何通过PyTorch实现ICNN,如何设置合适的损失函数,以及如何评估模型性能。提供详细的代码实现和调试技巧。
3. 无监督深度学习超弹性本构定律
3.1 问题设定
系统阐述基于无监督学习的超弹性本构建模框架,包括问题的数学描述、物理约束条件的表达、目标函数的构建等。重点说明如何将材料本构建模问题转化为适合深度学习的形式,以及如何在模型中嵌入物理定律约束。
3.2 从逐点数据近似位移场
详细介绍如何利用深度学习方法从离散的实验数据中重建连续的位移场。包括数据预处理技术、网络结构设计、插值算法选择等关键环节。重点讲解如何保证重建位移场的物理合理性,以及如何处理边界条件和连续性约束。
3.3 基于神经网络的本构模型
深入探讨神经网络在材料本构建模中的应用方法,包括网络架构设计、变形梯度到应力的映射关系建立、能量函数的构造等。重点阐述如何通过网络设计保证预测结果满足材料本构关系的基本要求,如客观性、各向同性等。

3.4 无监督学习的本构模型
系统介绍无监督学习在本构建模中的实现方法,包括自编码器的应用、潜在空间的构建、物理约束的实现等。重点讲解如何在缺乏直接应力-应变数据的情况下,通过位移场信息实现材料本构关系的重建。
4. 数值基准
4.1 数据生成
详细介绍用于模型训练和验证的数据生成方法,包括有限元模拟数据的生成、实验数据的采集和处理、数据增强技术等。重点说明如何设计合理的加载路径,以保证数据的代表性和完备性。展示数据质量控制和预处理的具体方法。
4.2 数据模型精度、泛化和FEM部署
系统讲解模型评估和应用的完整流程,包括预测精度的量化评估、模型泛化能力的测试、有限元实现方法等。

1. 物理约束相关理论
1.1 变形映射
详细介绍连续介质变形的数学描述,包括参考构型和当前构型的概念,物质点的运动描述方法,以及欧拉描述和拉格朗日描述的区别和联系。重点阐述变形映射在描述材料大变形行为中的核心作用,以及如何通过变形映射建立参考构型和当前构型之间的关系。
1.2 变形梯度
系统讲解变形梯度张量的定义、物理意义和数学性质。包括变形梯度的极分解、旋转张量和伸长张量的物理含义,以及变形梯度在描述局部变形中的应用。重点分析变形梯度与位移场的关系,以及在非线性力学分析中的重要作用。
1.3 Cauchy-Green变形张量
深入探讨右Cauchy-Green变形张量和左Cauchy-Green变形张量的定义、性质和应用。重点介绍这些张量在描述材料变形状态中的优势,以及与应变测度的关系。讲解如何利用这些张量构建材料本构模型。
1.4 各向同性(Isotropy)特性及其不变量
详细讲解材料各向同性的物理含义,以及如何通过张量不变量来描述各向同性材料的力学行为。重点分析变形张量的主不变量和混合不变量的物理意义,以及在构建材料本构模型中的应用。
1.5 近似不可压缩性
系统介绍近似不可压缩材料的力学特性,包括体积约束的数学表达、应力分解方法和数值处理技术。重点讲解如何在有限元分析中处理近似不可压缩约束,以及混合元的基本原理。
1.6 完全不可压缩性和横向各向同性
深入探讨完全不可压缩材料的特殊处理方法,以及横向各向同性材料的本构描述。重点分析这类材料在数值模拟中的挑战和解决方案,包括拉格朗日乘子法和增广拉格朗日法的应用。
1.7 基本概念及热力学一致性
详细阐述材料本构模型需要满足的热力学基本原理,包括能量守恒、熵增原理等。重点讲解如何通过热力学框架保证本构模型的物理合理性,以及能量函数构造的基本原则。
1.8 材料客观性和坐标系无关性
系统介绍材料客观性原理及其数学表达,包括客观应力率的定义和应用。重点分析如何保证本构方程的坐标系无关性,以及在大变形分析中的具体实现方法。
1.9 材料对称性和各向同性
深入讲解材料对称性的数学描述,以及各向同性材料的本构表达。重点分析材料对称群的概念,以及如何通过表示定理构建符合对称性要求的本构方程。
2. 神经网络中物理信息概述
2.1 物理合理性限制
系统介绍如何在神经网络中嵌入物理约束,包括网络结构设计、损失函数构造和训练策略优化等方面。重点讲解如何保证神经网络预测结果满足基本的物理定律,如能量守恒、热力学一致性等。
2.2 物理意义深入解释与工程应用
详细分析神经网络模型中各个组件的物理含义,以及如何将物理知识转化为网络设计的指导原则。重点探讨物理信息指导下的神经网络在工程实践中的应用价值和实施方法。
3. 物理约束在神经网络模型中的应用与实现
3.1 纯数据驱动的神经网络模型构建(案例)
通过具体案例展示纯数据驱动方法的实现过程,包括数据准备、网络设计、训练过程和结果验证等环节。重点分析该方法的优势和局限性,以及如何通过数据增强提高模型性能。
3.2 能量驱动的神经网络模型构建(案例)
详细介绍基于能量方法的神经网络模型构建过程,包括能量函数的设计、网络结构的选择和训练策略的制定。重点讲解如何确保模型满足能量守恒原理,以及在非线性问题中的应用。
3.3 基于PDE的神经网络模型构建(案例)
系统展示如何将偏微分方程约束引入神经网络模型,包括方程离散化方法、损失函数构造和求解策略。重点分析Physics-Informed Neural Networks (PINNs)的实现原理和应用技巧。
4. 基于物理信息的神经网络架构与仿真技术融合
4.1 UANISOHYPER_INV人工神经网络本构子程序
详细讲解如何开发和实现UANISOHYPER_INV用户子程序,包括子程序框架设计、数据交换接口定义和计算流程控制等。重点介绍如何将训练好的神经网络模型嵌入到有限元分析中。
4.2 基于物理信息的人工神经网络与仿真技术融合
系统探讨神经网络模型与传统数值模拟方法的融合策略,包括模型部署、计算效率优化和结果验证等方面。重点分析如何在保证计算精度的同时提高仿真效率,以及在实际工程问题中的应用方法。

1. 为什么需要图神经
1.1 欧式数据
详细介绍欧式空间数据的特点和局限性。包括传统深度学习方法(如CNN、RNN等)在处理规则网格数据时的优势,但在处理非结构化数据时的不足。重点分析在工程领域中,为什么规则网格数据无法完全满足复杂结构分析的需求,以及欧式数据在表达空间关系时的局限性。
1.2 非欧式数据
系统讲解非欧式数据的概念、特点和在工程中的典型应用。重点介绍网格数据、点云数据、分子结构等非规则数据的表示方法,以及这些数据在传统深度学习框架下难以直接处理的原因。分析非欧式数据处理在材料科学、结构力学等领域的重要性。
1.3 图结构嫁接到神经网络
深入探讨如何将图论与深度学习结合,包括图的数学表示、图中节点和边的特征提取、邻接关系的表达等。重点讲解图结构在表达空间关系和拓扑关系方面的优势,以及如何将物理问题转化为图学习问题。
2. 图神经网络
全面介绍图神经网络的基本概念、架构设计和工作原理。包括图的表示方法、特征传播机制、聚合函数设计等核心内容。重点分析图神经网络在处理非欧式数据时的优势,以及其在复杂工程问题中的应用潜力。讨论不同类型的图神经网络及其特点。
3. 图神经网络的变体
系统讲解各种图神经网络变体的设计思想和特点,包括图卷积网络(GCN)、图注意力网络(GAT)、图自编码器等。分析不同变体在特定任务中的优势和局限性,以及如何选择合适的网络架构来解决实际问题。
4. 图卷积神经网络
4.1 基于空间域的图卷积神经网络
详细介绍空间域图卷积的原理和实现方法,包括消息传递机制、特征聚合策略和非线性变换等核心操作。重点分析空间域方法在保持局部结构信息方面的优势,以及在工程应用中的实现技巧。
4.2 基于注意力实现的图神经网络
深入探讨注意力机制在图神经网络中的应用,包括自注意力机制的设计、多头注意力的实现以及注意力权重的学习方法。重点讲解如何通过注意力机制提高模型对重要特征的感知能力。
4.3 基于自编码器实现的图神经网络
系统介绍图自编码器的设计原理和架构,包括编码器和解码器的构建、潜在空间的表示学习以及重构损失的设计。重点分析如何通过自编码结构实现图数据的降维和特征提取。
5. 基于3D轮毂结构实现和评估GNN模型
5.1 预测受外力作用下轮毂的应力和位移分布
详细讲解如何将轮毂结构的力学分析问题转化为图学习任务,包括网格划分、边界条件设置、载荷施加等关键步骤。重点分析GNN在预测应力场和位移场时的优势。
5.2 涉及的物理量
系统介绍应力分析中的关键物理量,包括应力张量、应变张量、位移场等。重点讲解这些物理量在图网络中的表示方法,以及如何确保预测结果的物理合理性。
5.3 材料模型
详细说明轮毂材料的本构模型,包括弹性模型、塑性模型等。分析如何将材料特性整合到图神经网络的学习过程中,确保预测结果符合材料力学规律。
5.4 几何参数
深入探讨轮毂结构的几何特征参数化方法,包括关键尺寸的定义、参数化建模方法等。重点分析几何参数对应力分布的影响,以及如何在图网络中表达几何信息。
6. 基于图神经网络复杂结构应力预测
6.1 图神经网络MeshGrapNet架构
系统介绍MeshGrapNet的网络架构设计,包括节点特征提取、边特征更新、消息传递机制等核心组件。重点分析该架构在处理网格结构数据时的优势和创新点。

6.2 数据集特征
详细说明用于训练的数据集构建方法,包括数据收集、预处理、标注等环节。重点讲解如何确保数据集的质量和代表性,以及数据增强技术的应用。
6.3 基于MeshGraphNet网络架构的应力预测
深入探讨MeshGraphNet在结构应力预测中的具体应用,包括模型训练策略、预测精度评估、结果可视化等。重点分析该方法相比传统有限元分析的优势,以及在工程实践中的应用前景。
培训目标



授课老师



授课时间



课程费用

深度学习第一性原理专题、机器学习分子动力学专题 、深度学习有限元仿真等
公费价:每人每个课程¥4980元 (含报名费、培训费、资料费)
自费价:每人每个课程¥4680元 (含报名费、培训费、资料费)
优惠福利:
福利一:同时报名两个课程¥9680元 报二赠一(含报名费、培训费、资料费)
参加一年课程价格:16680元 (含报名费、培训费、资料费)
福利二:现在报名一门赠送一门往期课程回放
报名两门赠送四门往期回放
优惠三:提前报名缴费学员可得300元优惠(仅限前15名)
报名费用可开具正规报销发票及提供相关缴费证明、邀请函,可提前开具报销发票、文件用于报销


培训特色及福利

1、课程特色--全面的课程技术应用、原理流程、实例联系全贯穿
2、学习模式--理论知识与上机操作相结合,让零基础学员快速熟练掌握
3、课程服务答疑--主讲老师将为您实际工作中遇到的问题提供专业解答
授课方式:通过腾讯会议线上直播,理论+实操的授课模式,老师手把手带着操作,从零基础开始讲解,电子PPT和教程开课前一周提前发送给学员,所有培训使用软件都会发送给学员,有什么疑问采取开麦共享屏幕和微信群解疑,学员和老师交流、学员与学员交流,培训完毕后老师长期解疑,培训群不解散,往期培训学员对于培训质量和授课方式一致评价极高!

学员对于培训给予高度评价




联系人:江老师
微信:13017692038
QQ:2929430477
引用往期参会学员的一句话: