
AI驱动矢量动画生成技术实现新突破
日常浏览中,矢量动画应用广泛。如今,通过输入简单文字或图片,AI可直接生成轻量级矢量动画。
复旦大学联合阶跃星辰、香港大学多模态实验室及昆士兰大学推出OmniLottie框架,利用创新分词技术将文字、图片及视频指令高效转化为高质量矢量动画文件。
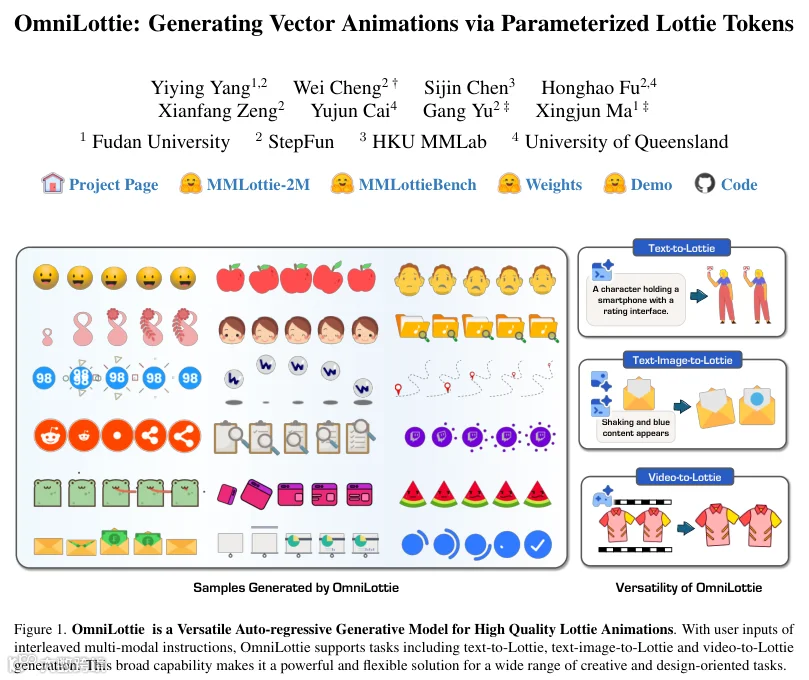
团队开发专用代码压缩方法并构建200万规模数据集,实现跨设备动画的自动生成功能。
传统痛点
数字内容动画主要分位图和矢量两类。位图文件大且缩放后易模糊;矢量动画基于数学公式记录图形运动,画面清晰且文件精简,其中Lottie格式因通用性强广受开发者青睐。
Lottie采用图层叠加方法,将形状、特效及运动参数封装于单一JSON文件,相比传统SVG更具优势。当前主流AI模型在处理文字生成视频时表现良好,但生成Lottie动画时受阻。
核心障碍在于原生Lottie文件包含大量非功能性元数据,导致模型算力浪费在代码结构闭合上,难以专注视觉元素与动态规律处理。现有商业工具生成的作品编辑性差,无法满足专业设计需求。
破局方法
团队重构底层数据表达,开发专用Lottie分词器,剥离冗余结构元数据,仅保留关键动画属性。该技术针对图层属性分类处理:基础属性(图层标识、层级等)、视觉属性(几何变换、特效等)及特定图层属性(预合成、纯色等五类基础图层)。
连续数字参数经离散化转换,形成线性指令代码。系统基于Qwen2.5-VL多模态大模型,集成专属词汇表预测生成精简符号,并由分词器还原为标准动画文件。
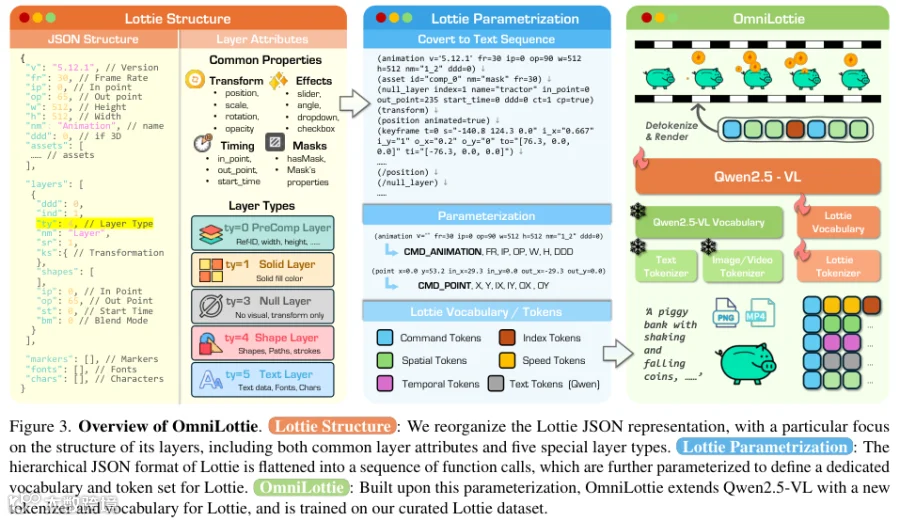
数据集构建
团队打造多模态矢量动画数据集MMLottie-2M,通过清洗主流平台原始文件,移除图片、音频等无关元素。针对优质动画不足问题,设计运动轨迹复用流水线:基于OmniSVG库的100万真实文件,提取旋转、缩放等变化轨迹,生成标准化动作模板并应用于静态图。
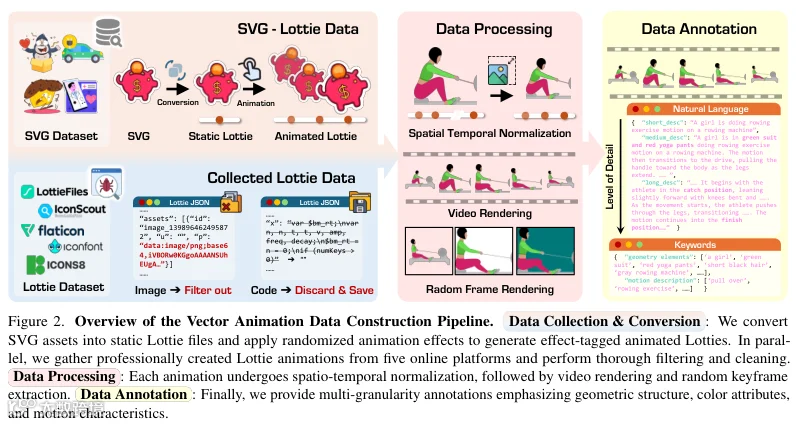
所有素材统一为512×512分辨率及0-16时间轴标准。采用由粗到细描述策略:先生成整体画面概述,再高亮形状与运动细节,提升大模型指令理解精度。测试基准MMLottie-Bench包含450个设计师提供的真实动画,并补充AI合成指令数据。
实验与结果
OmniLottie在文字生成动画任务中成功率88.3%,大幅领先DeepSeekV3(9.3%)和GPT-5(12.7%);看图配字任务成功率93.3%,动作流畅性显著优化;视频转动画任务成功率78.4%,远超GPT-5的7.4%。
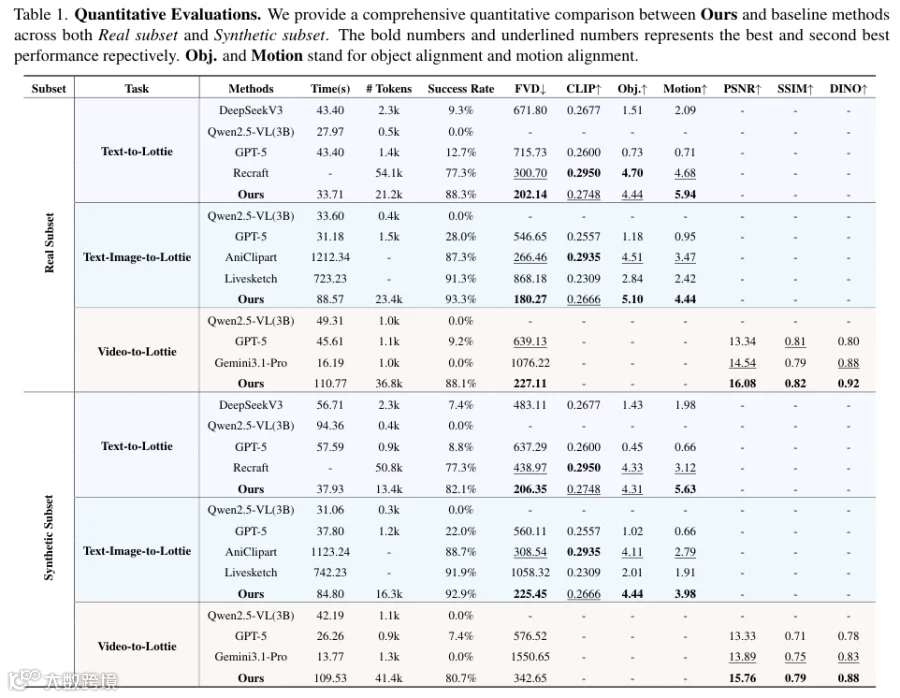
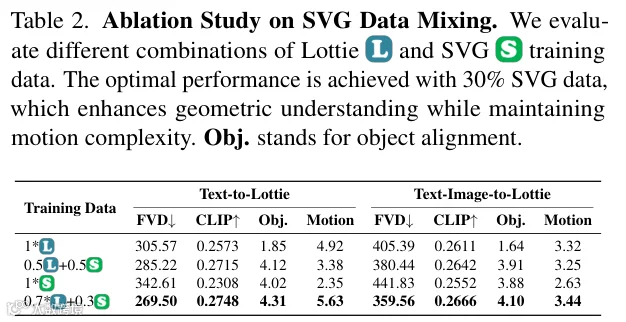
性能验证表明,混入30%静态图转换数据效果最佳,有效平衡画面丰富度与动作流畅度。关键实验显示,分词器将文字生成动画成功率从原生模型的0%提升至97.3%。
当前系统在处理多图层长动画时存在局限,未来计划引入打分奖励机制并与专业软件集成。