
在人工智能领域,让机器“数数”一直是个挑战,尤其是当面对从未见过的物体类别时。传统的计数模型往往依赖大量的人工标注,换个场景可能就“罢工”。近日,来自西北工业大学、电信 AI 等机构的研究团队提出了一种名为 QICA 的新框架。它不仅能根据简单的文字描述(如“照片里有16个草莓”)数出任何东西,还通过聪明的“协同提示”和“空间感知”技术,打破了模型在数量认知上的瓶颈。本文将带您深入浅出地解读这项突破性研究。

-
• 论文标题:Boosting Quantitive and Spatial Awareness for Zero-Shot Object Counting(提升零样本目标计数的数量与空间感知能力) -
• 论文链接:https://arxiv.org/abs/2603.16129 -
• 代码链接:https://github.com/zhangda1018/QICA -


一、 痛点:为什么 AI 总是数不准?
目前的零样本目标计数(ZSOC)主要依靠像 CLIP 这样的多模态大模型。你告诉它“数一数图中的树”,它会把文字和图片匹配,然后生成一张“密度图”。
但这里有两个致命伤:
-
1. 数量盲区:AI 知道什么是“树”,但它不知道“1棵树”和“10棵树”在视觉特征上的细微差别。它把计数当成了简单的“找东西”任务,缺乏对数量的敏感度。 -
2. 空间失真:为了让 AI 学会计数,开发者往往会微调模型,但这容易破坏大模型原本博学多才的特征空间,导致它在面对新物体时表现拉跨,也就是我们常说的“过拟合”。
二、 核心方案:QICA 的“三大法宝”
为了解决上述问题,研究团队提出了 QICA 框架,其核心由三个精妙的设计组成:
1. 协同提示策略 (SPS):让视觉和文字“通气”
以往的模型,文字归文字,图片归图片。QICA 引入了协同提示策略 (SPS)。
它通过一个“耦合函数” ,将文字中的数量信息(比如“16个”)转化为视觉提示,直接插入到视觉编码器中。
公式表达:
2. 代价聚合解码器 (CAD):找回丢失的空间感
为了防止微调导致模型“变傻”,研究者设计了 CAD。它不直接修改图像特征,而是操作“视觉-文字相似度图”。
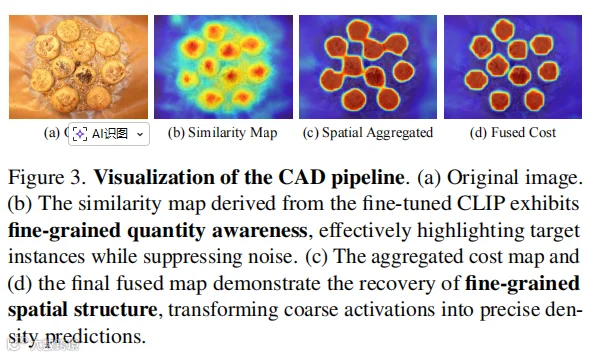
(注:上图选自论文图3。可以看到,经过 CAD 处理,原本模糊的匹配区域(b)变得非常精准且具有空间结构感(d)。)
它利用 Swin Transformer 块进行空间聚合,像是在草稿纸上把凌乱的点连成线、结成块,从而抑制噪声,精准定位每一个目标物体。
3. 多级数量对齐损失 ( ):严师出高徒
为了确保模型真的学会了数数,QICA 引入了一套严格的考核机制——多级数量对齐损失。
在训练阶段,模型不仅要看正确的数量(如16),还要看错误的干扰项(如13或19)。模型必须保证:
-
• 正确数量的相似度分值最高。 -
• 越接近正确数量的干扰项,分值也要相对更高。
总损失函数:
三、 整体架构:高效的协作流水线
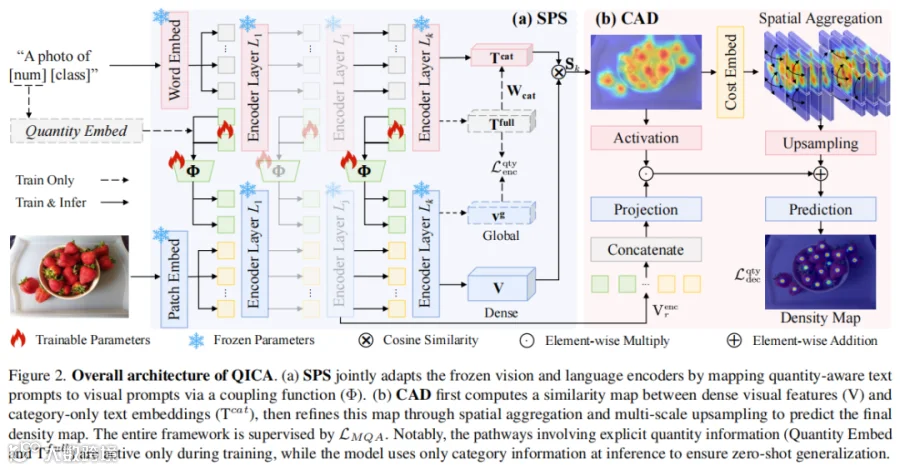
(注:上图选自论文图2。展示了从文字输入到最终生成密度图的全过程。)
如图所示,QICA 在训练时(虚线路径)利用数量信息进行强化学习,但在实际推理(实线路径)时,完全不需要预知数量,只需输入物体类别即可。这种“严进宽出”的设计保证了极强的通用性。
四、 战绩彪炳:实测效果如何?
研究团队在多个权威数据集上进行了测试,结果令人惊叹:
-
• FSC-147 数据集:在测试集上达到了 12.41 MAE(平均绝对误差),相比之前的同类模型改进了 25%~30%。 -
• 跨场景挑战:在完全没见过的车辆监控(CARPK)和极拥挤的人群场景(ShanghaiTech-A)中,QICA 无需任何微调,直接上场就拿下了多项 SOTA(业内最佳表现)。
在极高密度的人群计数中,QICA 表现出了极强的鲁棒性,甚至超过了某些专门为人群计数设计的模型。
五、 结语
QICA 的出现,标志着零样本目标计数从简单的“语义匹配”向深层的“数量认知”迈进。它通过优雅的架构设计,既保留了大模型的泛化能力,又补齐了计数的短板。
对于开发者来说,这意味着未来我们可以更轻松地部署通用的计数服务——无论是果园里的果实、仓库里的零件,还是街道上的行人,只需一句话,AI 就能数得清清楚楚。

