

有太多的技术在挑战质谱的灵敏度、精度和准确性,而质谱界本身也需要不停地证明自己的能力。现如今我们日常都能给把蛋白质的定性深度做到8000~10000+,那么进一步如何证明相应的定量结果是可靠的呢?基于全新发布的Spectronaut19,我们来重现下去年Nature Biotech的数据作为一个范例。

如何证明我们的定量结果有多可靠,我们无法先验的知道目标蛋白应该是如何变化的,但相对简单的做法就是人为掺入已知比例的蛋白进行定量结果测试,结果越接近预期,则说明定量越可靠。就如本文:混合3种几乎不同源物种的蛋白:人、大肠杆菌、酵母,其中保持人源蛋白含量不变,大肠杆菌和酵母的相对含量控制为5:45;10:40;20:30;30:20;40:10;45:5 6种比例,采用Astral 40分钟梯度检测,数据分析采用Spectronaut17(原文),Spectronaut19(本文)。如下图,可以看到大肠杆菌的检出率在高丰度人+酵母的存在下相对还是较低的,大约1300(30%理论蛋白质组4400),酵母则检测到约4400(70%理论蛋白质组6100)。因此大肠杆菌的定量准确性更能够反映我们对微量蛋白质的定量准确性焦虑。
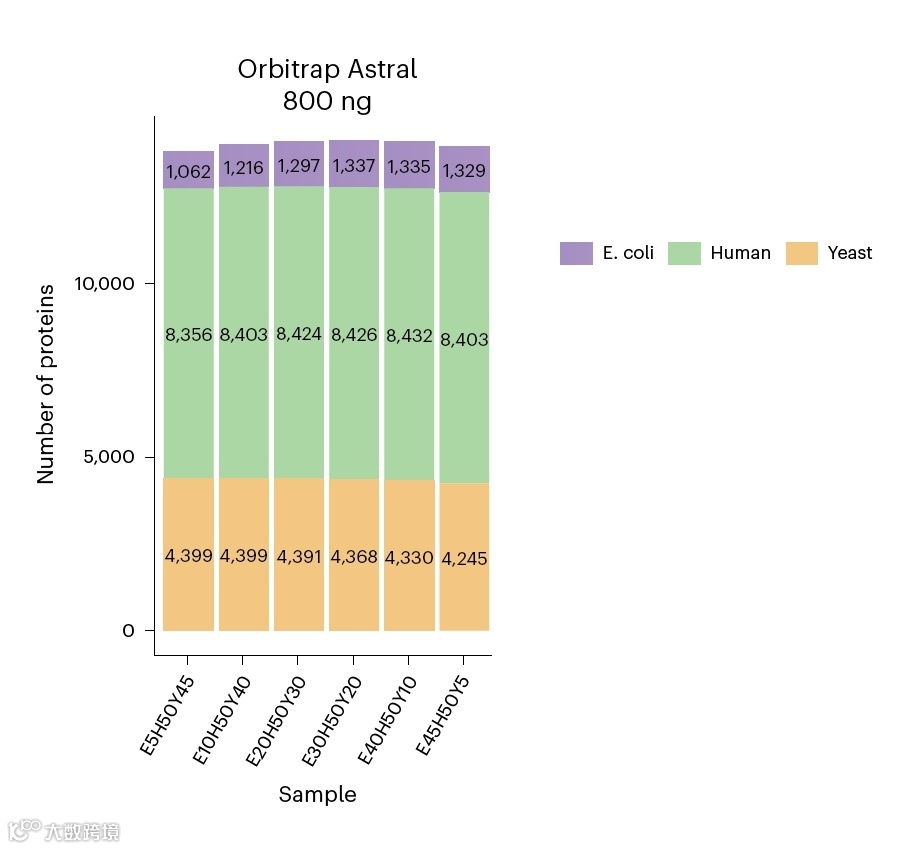
在尝试治疗焦虑前,我们先看下整体结果,在文章共检出约14000种总蛋白的同时,蛋白质定量CV小于20%的蛋白几乎占到近90%的总蛋白质,缺失值比例也低到了5%左右。

当然在使用了SN19之后,鉴定量进一步提升到超过平均15000种蛋白,CV<20%的蛋白占比也站上了90%比例,缺失值进一步降低。见下图(SN19结果)

在所有样品中全都检测成功的蛋白占比>90%,见下图。

进一步的定量准确性解读在原文中就草草带过了,有些定量图只是绘制了总体分布,看不出啥细节,也没法让我们深入把握定量的细节。我这里不会受到NBT的字数限制,帮大家展开展开。
首先,解答一个近期客户时常问我的问题,质谱的定量到底在什么情况下会不太准?
我以如下两个典型蛋白的结果作为一个快速总结:
丰度高、差异大的,会有一定的压缩情况出现,如下图ENO1_YEAST(蛋白定量值4e5)这个整个样品中最高丰度的酵母蛋白为例,虽然定量CV几乎为0,但差异倍数和掺入比例偏差30%以上。这其中原因既有质谱定量的线性范围问题(信号差别接近1个数量级的时候一定会有压缩),也有色谱峰过载拖尾的可能性。
FC9 |
FC4 |
FC1.5 |
6.6 |
3.2 |
1.4 |

而如MG101_YEAST(定量丰度1.8e4)这个相对中等丰度的蛋白定量结果是正确的,不过像如此完美的结果总的来说比例不高,绝大部分9:1差异的蛋白定量都在7-8之间。

对于低丰度蛋白,定量结果还是不尽如人意。如THRC_ECOLI(丰度800),则相对更低含量的几组结果则非常不准确或存在大量缺失值,尽管其趋势还是大致正确的。

那THRC这种低丰度蛋白到底定量细节如何呢?见下图,18个样品的XIC

看惯美丽的XIC曲线的人可能有点难以接受,尽管如下图的TIC其实近乎完美,即使Astral扫描速度足够快,但这就是低丰度信号的表现。本文数据整体样品平均DPPP(平均每个谱峰定量数据点数)=4,而低丰度的可能还是只有1左右的定量点。

我们也可以基于Spectronaut中的CV分段可视化看到不同强度下的CV分布,从而间接考察定量的精确度,如下图,就可以验证刚才这几个例子是否代表整体结果。低丰度或高丰度(过载拖尾)的谱峰定量CV就是不那么理想。

不同软件的定量结果精度相近,但准确性有所差异,我分别统计了DIA-NN(NN)和Spectronaut(SN)的人、酵母、大肠杆菌在不同掺比(E代表e.coli,E5:5%;E10:10%;E20:20%;E30:30%;E40:40%;E45:45%)。但进一步统计整体CV、25%(最低丰度25%蛋白的平均CV)、10%(最低丰度10%蛋白的平均CV)侯,就可以初步解答很多人关心的低丰度蛋白定量的问题。如下表1,可以非常清晰地看出大肠杆菌则因为鉴定数量少,低丰度蛋白统计更难以准确,CV在30%上下波动(很多人肯定不满意这个CV了)。同时我们要关心的是虽然人蛋白总体CV几乎都小于7%,但是低丰度蛋白,即使是总体含量最高的human的CV也大于20%。总的来说DIA-NN的定量CV还是略小于Spectronaut,但差别忽略不计。
表1.各分组不同丰度下的定量CV平均值
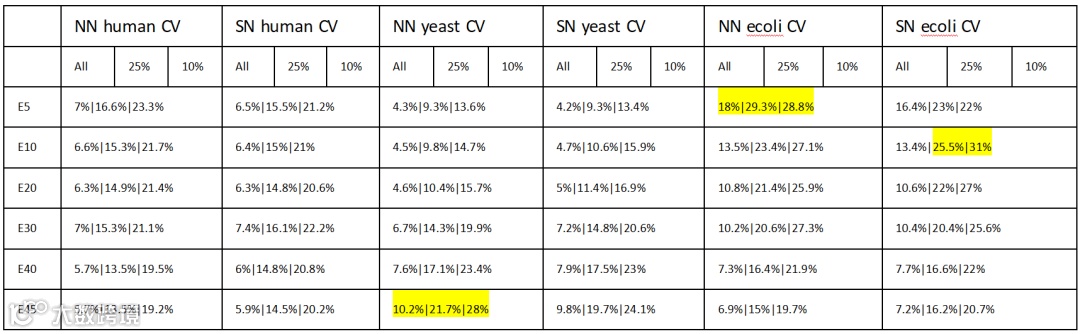
表1反映的是定量的精确性,那准确性呢,见表2:我分别统计了整体,最低25%,最低10%的平均定量差异ratio,人蛋白应该全部都为1,可以看到几乎都非常准确;而大肠杆菌和酵母则偏离正确结果相对都比较大,尤其是DIA-NN的定量精确度相对SN来说更是低了不少,在大肠杆菌中可以看到理论差异9倍的蛋白,即使信号最高的前10%蛋白(90%列)的平均定量比值也和理论值9差了约15%,最低丰度的那些蛋白更惨不忍睹,而SN在1.5倍理论倍数下定量较为准确,4倍差异的高丰度蛋白还算准确,9倍差异只能说最高丰度的那些蛋白还算可以了。
表2.各分组,不同丰度范围下差异倍数平均值

最后再举个例子,我们现在追求新质谱的原因之一就是其定量深度、准确性、精度都想比老质谱都提高不少。比如这套3物种混合数据,40分钟梯度下每个样品几乎都能定量到近30万个母离子,超过20万种肽段,平均每个蛋白有近14个肽段用于定性、定量。这在以往都是难以想象的。

但即使如此,我们缩短梯度,降低上样量的结果也还是会损失信息的,我找了丰度最低的几个蛋白为例,如下图丰度rank,我就挑选了每个物种最低丰度的几个蛋白举例。

LPXC_ECOLI:缺失值一半,定量趋势还算对,XIC几乎没法看。




YIHL_ECOLI:和LPXC类似,只有含量最高的几个样品检出可靠结果。

YL146_YEAST:和大肠杆菌最低丰度的2个蛋白结果类似。

ZN211:人蛋白中的最低丰度蛋白,理论上每个样品中都含量一致,但如下的全XIC对齐图(MS2和MS1以及所有样品均整合)可以看到丰度在50以下,结果基本都很随机。

MACD2:倒数第二丰度的人蛋白也类似。

因此,虽然新质谱的灵敏度很好,但依然不要被如此之低的平均定量CV所迷惑,超高丰度、极低丰度、差异倍数极大的蛋白依然是质谱界定量的巨大挑战。
不过乐观的是,我们可以看到大部分蛋白质的定量结果都还符合预期的,所以中间丰度70%左右的蛋白定量,还是可以信赖的。而以后您的研究如果希望实现较好的定量准确性评估,建议平行做个和本文类似的掺入定量评估,如果您觉得麻烦,欢迎与我们合作,我们将为您提供一站式解决定量准确性评估的工作。敬请期待!

以酵母为例,横坐标为丰度从高到低排列,纵坐标为实际定量差异倍数,展示了所有蛋白理论差异9倍,4倍,1.5倍的分布,不知道这样的定量结果对2024年的你来说是不是满意呢?

相关阅读
【多组学】iHMP(人类微生物组整合计划)| Cell Host & Microbe:人体多个部位菌群的稳定性及与宿主的相互作用
【多组学】Blood最新封面文章解读 | 单细胞及多组学揭示补体C1Q促进急性骨髓性白血病(AML)的髓外浸润(EMI)和复发
【多组学】玩转多组学联合分析,拿捏CNS Paper!
【多组学】CNS:肥胖那些事 | 涉及组学:单细胞转录组、脂质代谢组、蛋白组、基因组学
【多组学】Nature Cancer(2023 IF:22.7) | 大型中国乳腺癌队列多组学研究
【蛋白组学】FAQ | 掌握蛋白组学常见问题,玩转前沿科研方法
【蛋白组学】质谱、Olink与SomaScan在蛋白质组学研究中的跨平台联合策略
【蛋白组学】Uniprot | 做蛋白组学研究,一定要了解的数据库
【Olink高通量蛋白组学】Nature(2023IF:64.8)| deCODE团队大规模血浆蛋白组学研究揭秘遗传学与疾病关联
【蛋白组学】好的样本带来好的检测 | 蛋白组学样本准备及送样手册(珍藏版)
【蛋白组学】Nature Metabolism(IF:20.8) | 人类脂肪生成的时空蛋白质组图谱
【蛋白组学】Matthias Mann团队:质谱体液蛋白组研究启示 | Nat Med、Cell Rep Med…
【蛋白组学】宏蛋白组学技术方案与实用策略盘点 | Microbiome(IF:15.5)、Research(IF:11.0)…
【蛋白组学】科研私话 | 2024年了,质谱现在行不行?
【蛋白组学】科研私话 | 基于质普技术的蛋白组学研究基石——蛋白质的鉴定原理
【蛋白组学】Nature Medicine | DIA+Spectronaut+PRM:发现并验证胰腺癌化疗敏感性的蛋白标志物
【蛋白组学】Microbiome | 基于宏基因组精准构建宏蛋白组序列库
【蛋白组学】科研私话 | 蛋白组学是不可替代的吗?
【蛋白组学】Nat Commun | PiSPA技术在单细胞蛋白质组领域实现3000+PG新高度
【多组学】Nature Microbiology(2022 IF 30.964) | 多组学研究慢阻肺病呼吸道菌群-宿主互作机制
【蛋白组学】抗体芯片 VS 质谱 | 世界上到底有没有完美的蛋白质组学研究工具?
【蛋白组学】抗体芯片 VS 质谱检测,不管黑猫白猫,能捉老鼠的就是好猫
【蛋白组学】Proteoform及其检测难题
【蛋白组学】Cell文章解析:蛋白质组学寻找早期肺腺癌的异质性和标志物
【蛋白组学】Cell文章解析 | CPTAC蛋白质组数据库 | 多组学研究带来胰腺导管腺癌治疗的新机会
【蛋白组学】关于宏蛋白质组学数据分析你应该知道的
【蛋白组学】蛋白质组学定量分析技术简介
