
NVMe的威力
随着闪存技术的不断演进,当今的闪存性能相比传统的机械硬盘已经有了质的飞跃。而针对闪存而设计的NVMe协议,则构建了基于PCIe链路充分发挥闪存性能的高速公路。有了这条高速公路,特别是针对闪存类存储的高带宽低延迟特性的优化设计,简化了协议开销和协议栈流程,存储单元将不再成为数据中心当中的主要性能瓶颈。
下图比较了在Linux内核的存储协议栈当中,传统的SCSI和NVMe的区别,可以从流程上直观地看出,NVMe更加简洁高效。
因为NVMe 的设计目标就是为了发挥闪存的威力,它和PCIe 的结合再加上不断更新的闪存技术,NVMe已经成为了非常成功的技术标准。我们从下图可以看到,即将发布的下一代NVMe闪存可以把硬件时延控制在10us(微秒)之内。

为什么选择NVMe over Fabics
PCIe 虽好,也有一些不足:
扩展局限性
PCIe设备都是点对点的串行连接方式,当前的Intel平台CPU每颗最大支持40个通道(Lane),对于一般的高端服务器,普遍都是双路、四路配置,双路下提供x80通道,理论上可连接10个x8的PCIe设备。单台服务器连接NVMe闪存盘也许够了,但是对于存储厂商或者有大容量需求的客户则远远不够。如果采用PCIe switch 进行扩展,那么级联端口的fan-in和fan-out比例又是另一个问题。
存储系统的可靠性要求
PCIe设备的热插拔支持一直不是很完善。如果PCIe设备突然被拔出,而系统没有很好的应对方案,甚至可能导致系统宕机。
成熟数据中心的网络结构
因为PCIe 的拓扑是个树型拓扑,无法实现冗余,对网络化的支持非常差,是否可以作为一个成熟的数据中心网络结构还有待时间验证。
以上这几点使得业内相关厂商意识到,必须利用其他网络协议,才能去支撑更大规模更远距离的NVMe 存储系统。因此在2016年6月发布的协议标准当中,NVMe over Fabrics (NVMe-oF 1.0) 把以下2种网络协议栈(RDMA和FibreChannel),作为NVMe的网络承载协议。


NVMe采用FC协议栈,利用FCP (FibreChannel Protocol)作为基础传输协议时,被称作FC-NVMe;
NVMe采用RDMA协议栈,利用以太网或者InfiniBand 作为基础传输协议时,被称作NVMe over Fabrics (NVMe-oF)。
大家可能会问,为什么是这几种协议?因为它们都有一个核心优势:低时延! NVMe和闪存的低时延优势不能在网络传输中被消耗掉。从下表可以看出,InfiniBand和FC协议在适配器端的时延都是50us(微秒)之内,交换机端的时延也都小于0.7us (微秒)。而以太网适配器最小时延都是200us,所以如果想让以太网也可以成为NVMe的网络承载协议,则必须利用RDMA技术来降低时延。

标准以太网没有包含RDMA技术,因此在时延方面并没有什么优势,在它引入RDMA(Remote Direct Memory Access)技术之后,可以把网络数据绕开系统内核进行处理,数据直接由硬件层面交给应用程序,减少了CPU资源以及内存带宽的消耗,可以极大地提升以太网网络性能,降低网络时延。
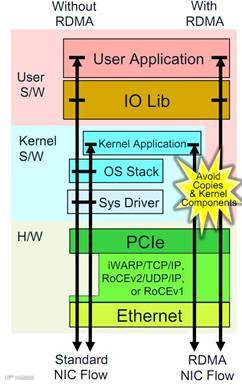
目前以太网当中有以下几种利用RDMA技术的协议:
Internet Wide Area RDMA Protocol – iWARP:2007年由IETF(Internet Engineering Task Force) 发布的基于OSI模型L3层TCP/IP的RDMA协议。
RDMA over Converged Ethernet – RoCE:2010年由IBTA(InfiniBand Trade Association) 发布的基于OSI模型L2层以太网的RDMA协议。
在2010年的第一版中,RoCEv1是以InfiniBand协议为基础,把底层更换为以太网。但是此版本必须要求是DCB无损以太网,且数据无法路由。
在2014年,IBTA更新了第二版的RoCEv2,通过使用UDP/IP封装,使得数据可以支持路由,但是底层以太网仍然必须要求是DCB无损以太网,以保证数据传输质量。

以上3种以太网RDMA协议,各有优劣,分别适合不同的应用场景。
iWARP:利用TCP/IP协议,协议开销较大。但是部署时无需DCB无损以太网,QoS控制依托于TCP协议,因此扩展性最强也最方便。
RoCEv1:利用IB协议,协议开销小,但是需要DCB无损以太网和PFC帧来进行QoS控制,缺乏3层路由支持。
RoCEv2:利用UDP/IP协议增加路由能力,通过IP增强了网络管理能力。仍然需要DCB无损以太网和PFC帧来进行QoS控制。
FC-NVMe 由ANSI/INCITS 下属的T11 技术委员会定义,正式标准已经在今年2017年Q3发布。FC的优势在于,它是专门针对数据中心的存储单元进行设计的网络协议,无论是久负盛名的SCSI还是IBM大型机采用的FICON协议,都是利用FC来进行网络传输。FC与生俱来的高可靠低时延的特点与NVMe自然就是天作之合,它的优势在于:
可以利用现有的Gen5 16G 和Gen6 32G HBA以及FC交换机,无需硬件更新。
网络可以同时传输FCP和FC-NVMe流量。
FC网络本身具备的高性能、高可靠性、管理简单、扩展方便等特点。
NVMe over Fabics的技术特点
通过以上的介绍,我们可以看出NVMe over Fabrics 架构有以下几个特点:
可靠的流控机制和传输体系
可靠的流控机制是高速传输的基础,否则各种丢包或者网络拥塞会让整个系统效率十分低下。目前拥有较好的流控机制的协议有Fibre Channel, InfiniBand 和PCIe。
端到端NVMe通路
端到端的NVMe 支持才可以保证充分发挥闪存的性能,一旦中间出现需要进行SCSI 和NVMe的协议转换,性能必然受到很大影响。
降低时延、更少占用CPU资源
无论是网卡还是HBA卡,更快更直接的访问底层硬件,占用更少的CPU资源,是NVMe系统的主要特点。
可扩展网络(Fabric scaling),特别是可以支持到上万个节点网络。
多主机可以同时通过多条路径访问NVMe存储的多个端口,充分发挥网络的优势。
总结
NVMe over Fabrics能够有效的降低网络的延迟,并且在不同网络类型之间保持NVMe协议的体系结构和软件接口的一致性,把NVMe协议在单系统时代提供的优势进一步扩展,使得NVMe闪存的性能优势能够充分发挥。
随着闪存技术的进一步发展,存储系统的性能也将不断提升,届时更高带宽更强性能的网络协议也将更加普及,整个数据中心的性能也将进入一个新的阶段。
3.Cavium FastLinQ for Microsoft Azure Stack 最佳实践

