

在本文中,分享在Node。js中跟踪和修复高内存使用情况的方法。
上下文
最近,我得到了一张标题为“修复库x中的内存泄漏问题”的票。该描述包括一个Datadog仪表板,该仪表板显示了十几种服务,这些服务具有较高的内存使用率,最终因OOM(内存不足)错误而崩溃,并且它们都具有x库。
最近,我被介绍给代码库(< 2周),这使任务具有挑战性,也值得分享。
我开始处理两条信息:
有一个库被所有引起高内存使用量的服务使用,并且涉及redis(redis包含在库的名称中)。
受影响的服务列表。
下面是链接到票证的仪表板:

服务正在Kubernetes上运行,很明显,服务随着时间的推移积累了内存,直到它们达到内存限制,崩溃(收回内存)并重新开始。
方法
在本节中,我将分享我如何处理手头的任务,确定高内存使用量的罪魁祸首,然后进行修复。
了解代码
由于我对代码库还很陌生,因此我首先想了解代码,所讨论的库做了什么以及如何使用它,希望通过此过程可以更轻松地识别问题。不幸的是,没有适当的文档,但是通过阅读代码和搜索服务如何利用该库,我能够理解它的要点。这是一个围绕redis流并公开方便事件生产和消费的接口的库。在花了一天半的时间阅读代码之后,由于代码结构和复杂性。
因此,我决定暂停阅读,并在观察操作代码并收集遥测数据时尝试发现问题。
孤立地复制问题
由于没有可用的配置文件数据(例如连续配置文件)可以帮助我进一步调查,因此我决定在本地复制该问题并尝试捕获内存配置文件。
我在Node。js中找到了几种捕获内存配置文件的方法:
使用堆快照
使用堆探头
性能分析JavaScript
Clinic。js
由于没有关于外观的线索,我决定运行我认为是图书馆中最“数据密集型”的部分,即redis流制作人和消费者。我构建了两个简单的服务,这些服务将从redis流中产生和消耗数据,然后继续捕获内存配置文件并随时间比较结果。不幸的是,在给服务产生负载并比较配置文件几个小时之后,我无法发现这两种服务中任何一种的内存消耗有任何差异,一切看起来都很正常。该库正在暴露一堆不同的接口以及与redis流交互的方式。对我来说,很明显,这比我希望复制的问题要复杂得多,尤其是我对实际服务的特定领域知识有限。
所以问题是,如何找到合适的时机和条件来捕获内存泄漏?
从分期服务捕获配置文件
如前所述,捕获内存配置文件的最简单,最方便的方法是对受影响的实际服务进行连续概要分析,这是我没有的选择。我开始研究如何至少利用我们的分期服务(它们面临着相同的高内存消耗),这将使我无需付出额外的努力即可捕获所需的数据。
我开始寻找一种将Chrome DevTools连接到正在运行的吊舱之一并随时间捕获堆快照的方法。我知道内存泄漏是在分阶段发生的,因此,如果我可以捕获该数据,我希望至少能够发现一些热点。令我惊讶的是,有一种方法可以做到这一点。
执行此操作的过程
通过发送Pod启用Node。js调试器
SIGUSR1向吊舱上的节点进程发出信号。
kubectl exec -it <nodejs-pod-name> -- kill -SIGUSR1 <node-process-id>有关Node。js信号的更多信息 信号事件
如果成功,您应该从服务中看到日志:
Debugger listening on ws://127.0.0.1:9229/....For help, see: https://nodejs.org/en/docs/inspector
通过运行在本地暴露调试器正在收听的端口
-
kubectl port-forward <nodejs-pod-name> 9229
将Chrome Devtools连接到您在先前步骤中启用的调试器。参观
chrome://inspect/您应该在Node。js进程的目标列表中看到:

如果没有,请确保正确设置了目标发现设置

现在,您可以开始加班捕获快照(时间取决于发生内存泄漏所需的时间)并进行比较。Chrome DevTools提供了一种非常方便的方法。
您可以在以下位置找到有关内存快照和Chrome Dev Tools的更多信息。记录堆快照
创建快照时,主线程中的所有其他工作都将停止。根据堆的内容,它甚至可能需要一分钟以上。快照内置在内存中,因此可以将堆大小增加一倍,从而填满整个内存,然后使应用程序崩溃。
如果您要在生产中拍摄堆快照,请确保从中获取的进程可能会崩溃而不会影响应用程序的可用性。
来自Node。js文档
回到我的情况,选择两个快照以按delta进行比较和排序,我得到了您在下面看到的内容。

我们可以看到最大的积极三角洲正在发生 string 构造函数,这意味着该服务在两个快照之间创建了很多字符串,但它们仍在使用。现在的问题是这些内容是在哪里创建的,谁在引用它们。捕获的快照包含此信息也很好 Retainers。

在挖掘快照和永不缩小的字符串列表时,我注意到类似于id的字符串模式。单击它们,我可以看到引用它们的链对象-又名 Retainers。这是一个叫做 sentEvents 我可以从库代码中识别出的类名。Tadaaa我们有罪魁祸首,到目前为止,我认为从未释放过的ID数量不断增加。我捕获了一堆加班的快照,这是一个不断重新出现为具有较大正三角洲的热点的地方。
验证修复
有了这些信息,我不需要尝试完全理解代码,而是需要专注于数组的目的,何时填充和清除。代码只有一个地方 pushing 数组的项目和代码所在的另一项 popping 他们缩小了修复的范围。
可以肯定地说,该数组在应该清空时没有清空。跳过代码的详细信息,基本上是这样的:
该库正在公开用于消耗,产生事件或产生和消耗事件的接口。
当它既消耗事件又产生事件时,它需要跟踪过程本身产生的事件,以便跳过它们而不重新消耗它们。The
sentEvents在生产时被填充并在尝试消费时被清除会跳过消息。
你能看到这是怎么回事吗??当服务仅使用库来生成事件时, sentEvents 仍然会填充所有事件,但是没有代码路径(消费者)来清除它。
我修补了代码以仅跟踪生产者,消费者模式上的事件,并将其部署到分期。即使具有分期负载,很明显,该补丁有助于减少高内存使用,并且没有引入任何回归。
结果
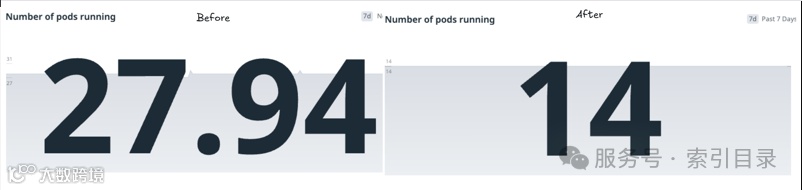
在生产中部署补丁程序时,内存使用量大大减少,服务的可靠性得到了提高(不再有OOM)。

一个很好的副作用是处理相同流量所需的吊舱数量减少了50%。
对于我来说,这是一个很好的学习机会,可以跟踪Node。js中的内存问题,并进一步使自己熟悉可用的工具。
我认为最好不要赘述每个工具的细节,因为这将值得单独发表,但是我希望这对于任何有兴趣了解更多有关该主题或面临类似问题的人来说都是一个很好的起点。