

一、隐私计算框架
隐私计算框架是在隐私信息全生命周期的各个环节中建立应用场景、保护需求与计算模型之间的映射关系。
基于场景描述和保护需求,适应性地选择相应环节的计算方法实现相应的计算功能。
从全生命周期的角度出发,具体包括以下5个步骤:

1.隐私信息抽取
根据明文信息M的格式、语义等,抽取隐私信息X,并得到隐私信息向量I。
2.场景抽象
根据I中各隐私信息分量ik的类型、语义等,对应用场景进行定义与抽象。
3.隐私操作选取
选取各隐私信息分量ik所支持的隐私操作,并生成传播控制操作集合。
4.隐私保护方案设计/选取
根据需求选择/设计合适的隐私保护方案。
如有可用且适合的方案及参数,则直接选择;
如无,则重新设计。
5.隐私保护效果评估
根据相关评价准则,使用基于熵或基于失真的隐私度量来评估所选择的隐私保护方案的隐私保护效果。
当隐私保护效果评价结果没有达到预期,则执行反馈机制,具体包括3种情况:
①当场景抽象不当时,则对场景重新进行抽象迭代;
②当场景抽象无误但隐私操作选取不当时,则对隐私操作重新进行规约;
③当场景、操作均无误时,则对隐私保护方案进行调整/完善,以达到满意的隐私保护效果。
二、隐私计算重要特性
将隐私信息抽象描述为六元组是隐私计算自动化的基础。
为实现隐私分量可量化、保护需求可量化、算法可组合,以及跨系统隐私信息交换时隐私保护算法效果一致评估,隐私计算的4个最重要的特性:
1.原子性
原子性指将隐私信息刻画到不可细分的粒度,即达到隐私信息最小化程度,隐私分量之间交集为空。
隐私分量满足原子性是隐私计算的第一个特性,隐私分量的原子性是隐私计算理论体系的基础。
隐私分量本身及其组合可量化度量。
将各类文档利用自然语言处理和图像理解等方法抽取出彼此互不相交的语义信息,然后基于隐私知识图谱将其构建为隐私信息中各分量具有原子性的隐私向量。
隐私计算与自然语言处理(Natural Language Processing,NLP)等技术的分界就在于隐私计算处理的是隐私信息,而NLP等智能方法处理的是从多模态文档中抽取的信息。
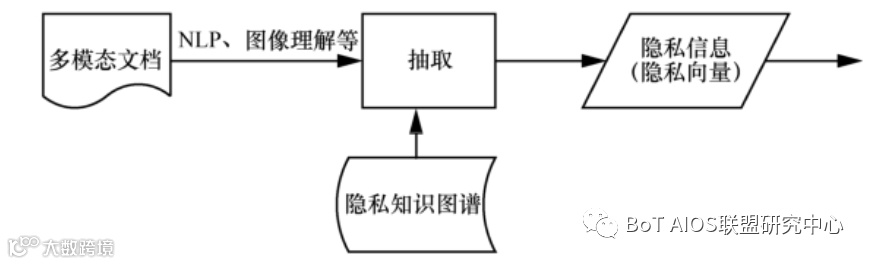
隐私向量生成框架
2.一致性
映射的一致性指对相同的隐私分量信息,不同算法的隐私保护效果使隐私度量都趋向于零。
同时在不同隐私保护系统映射时,算法保护能力强弱的量化关系在映射前后保持一致性。
例如算法A和算法B在系统1中的保护能力评估是AB>,在映射到系统2中的评估体系时,仍然保持AB>。
一致性原则将使算法保护能力量化体系在不同系统中具有一致的可比性,使隐私信息系统在实现过程中可有效比较不同保护算法的效果并方便对其进行组合。
3.顺序性
隐私保护算法由若干环节组成,不同环节的组合顺序不同可能导致隐私保护的效果不同。
总结不同组合顺序隐私保护效果的演化规律,可以支撑隐私保护算法的设计和隐私保护效果的评估。
如果隐私保护算法执行顺序不影响隐私保护效果,则这些算法可以并发执行;
如果隐私保护算法需要顺序执行,则整个隐私保护算法只能采用串行架构。
4.可逆性
可逆性用于对隐私防护算法和隐私脱敏算法进行分类。
如果算法是可逆的,如基于加密的算法可以通过解密来恢复,此类方法可归类为隐私防护方法。
在跨系统交换的应用场景中,如果各系统保护能力存在差异,则会有信息泄露的风险,隐私保护效果不一定能保持。
通过泛化、加扰的隐私脱敏方法往往是不可逆的,在跨系统交换应用时能保证不会恢复原始信息,脱敏后的信息能够保持隐私保护的效果。
因此,隐私计算重点研究的是不可逆的隐私脱敏算法。
