内存分配是传统编译器和神经网络(NN)编译器中必不可少的步骤。程序的每个变量(或NN模型的张量)被分配一个存储空间来存储其值以供稍后的操作使用。在本文中,我们向NN模型应用基于活性分析的经典分配方法,并查看该方法在NN区域是否仍然表现良好。实验结果非常令人鼓舞。例如,在模型yolo9000上,导出的内存占用量仅为模型总张量大小的16%。这太棒了!考虑到yolo9000的总张量大小为1.4GB。在活跃度分析的帮助下,只需要255MB的内存来存储所有这些张量。我们节省高达1.1GB的内存!

图1:归一化为总张量大小的内存占用。越小越好。
图1显示了更多的实验结果,其中内存占用的值被归一化为总张量大小。让我们来看看前三个模型yolo9000,yolov1和VGG_ILSVRC_19_layer,这是我们实验中最大的三个模型。与总张量大小相比,需要大约1/3或更小的内存占用,这意味着可以节省数百MB甚至GB的内存。基于活跃度的分配有助于为巨大的神经网络模型节省大量内存。平均而言,与总张量大小相比,我们实现了42%的内存占用。
如果我们想要将模型部署到嵌入式平台,那么内存占用是一个生死攸关的因素。一个流行的平台Raspberry Pi 3具有1GB RAM; BeagleBoneBlack甚至更小的512MB RAM。但是,如果没有适当的内存分配,完全不可能在它们上部署yolo9000(总张量大小为1.4GB)。
运行时性能也是一个严重的问题,占用大量内存。当前的CPU或DLA(深度学习加速器)通常具有内存的分层结构。内存占用越小,我们就越有可能将变量保留在相对较小但快速访问的缓存中。全局系统存储器和本地高速缓冲存储器之间的数据移动,即时间/功率浪费,因此被消除。
在传统编译器中进行内存分配是一种经典的想法。我们说变量(或张量)是“活着的”,如果后来的运算符仍然需要它的值; 否则,不再使用的值可能会释放其内存空间以供其他变量(张量)使用。如果两个变量具有单独的活跃持续时间,显然它们可以共享相同的内存空间。这就是为什么我们可以缩小模型的内存占用。
让我们将LeNet视为活体分析的一个例子。图2的代码是ONNC从ONNX转换的一种中间表示(IR)。它按照LeNet计算的顺序描述了一系列操作。让我们看看前几个操作,以了解此IR的作用。第一个操作是将变量%data_0加载到DLA的缓存中。然后第二个和第三个意味着加载更多的变量。第四个是对先前加载的数据%data_0以及权重%conv1_w_0和偏差%conv1_b_0进行卷积。之后,结果存储为变量%conv1_1。

图2:LeNet的IR,由ONNC从ONNX转换而来。
现在是时候计算张量的活跃持续时间了。为便于讨论,假设每个操作员仅消耗一个运行时单位。然后,使用“use-def chain”我们得出每个变量的最后使用时间。例如,%data_0最后一次使用时间= 3(从0开始)操作%conv1_1= Conv,因此其活跃持续时间为[0,3]。LeNet中其他张量的活跃持续时间在第四列中显示如下。
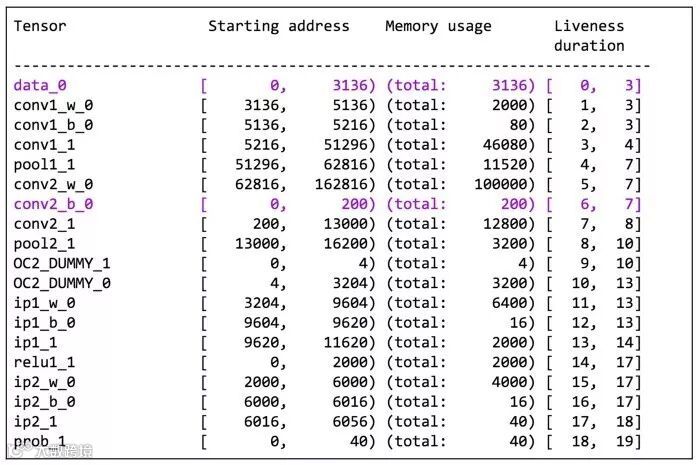
图3:LeNet的内存分配结果。
通过现场分析结果,我们可以开始分配内存。问题是这样制定的。我们的目标是在约束条件下最大化内存共享(等效于最小化内存占用),如果它们的活跃持续时间重叠,则没有两个变量共享内存。实际上,这个优化问题是NP完全的。在这里,为简单起见,我们只应用贪婪的分配。结果显示在图3中。您可以看到变量%data_0和%conv2_b_0共享相同的内存空间,而它们的活跃持续时间[0,3]和[6,7]分别是独立的。
贪婪的分配显然不够好。我们想开发更先进的方法。然而,我们的实验表明,即使采用这种琐碎的贪婪策略,我们仍然可以在某些模型上获得显着的内存占用缩减。在NN编译器中,活动分析也应该是一个重要的步骤。
诚邀您参加“”2019人工智能系统与集成电路研讨会”,点击“阅读原文”报名










