BEV是鸟瞰图(Bird's-Eye-View)的简称,也被称为上帝视角,是一种用于描述感知世界的视角或坐标系(3D),BEV也用于代指在计算机视觉领域内的一种端到端的、由神经网络将视觉信息,从图像空间转换到BEV空间的技术。
合格的智能驾驶系统需要准确表达道路布局、车道结构、交通参与者等元素信息。然而,物体的距离、场景的深度信息在2D感知结果上并不能得到有效呈现。而这些信息构成了智能驾驶系统进行正确判断的依据。因此,BEV融合感知成为了智能驾驶量产时代的优选与关键课题。

此前,特斯拉的自动驾驶感知神经网络结构采用了HydraNet的共享主干多头结构,利用相机外参以及地面平面假设便可使用称作IPM(Inverse Perspective Mapping)的方法,将图像平面的感知结果反投影回自车BEV坐标系。
然而当地面不满足平面假设,且多相机视野关联受到各种复杂环境影响时,这样的方案难以维护。
直到2021年,特斯拉在其AI DAY中展示了FSD Autopilot系统,开始尝试直接在神经网络中完成图像平面到BEV空间的转换,这一改变也奠定了其后以时空序列Feature处理模块为代表的技术革新。
通过算法得出的“鸟瞰视图”
BEV网络的优势不仅在于可以使用感知输出直接进行决策规划,还可以通过多个视角的融合,解决遮挡问题和物体重叠问题,让感知结果的输出更加准确、稳定,同时具备更强的鲁棒性。
而时序队列的使用,赋予了神经网络获得帧间连续的感知能力,与BEV结合后,使特斯拉FSD获得了对局部地图进行读写的能力,通过实时构建局部地图,FSD系统可以不依赖传统预先采集的高精地图逐步实现城市中的自动驾驶能力。
觉非科技以“融合感知”为核心技术发展路径,通过长期的车端与路侧技术实践,结合LiDAR+Camera的融合感知方式,积累了大量覆盖不同场景的自动驾驶数据集。通过对这些数据的进一步融合,结合机器学习等方式,转化成为“数据服务平台”,用以训练无人驾驶AI。
而这也为觉非科技实现BEV融合感知奠定了坚实的技术基础。觉非BEV融合感知的发展囊括了几个阶段:
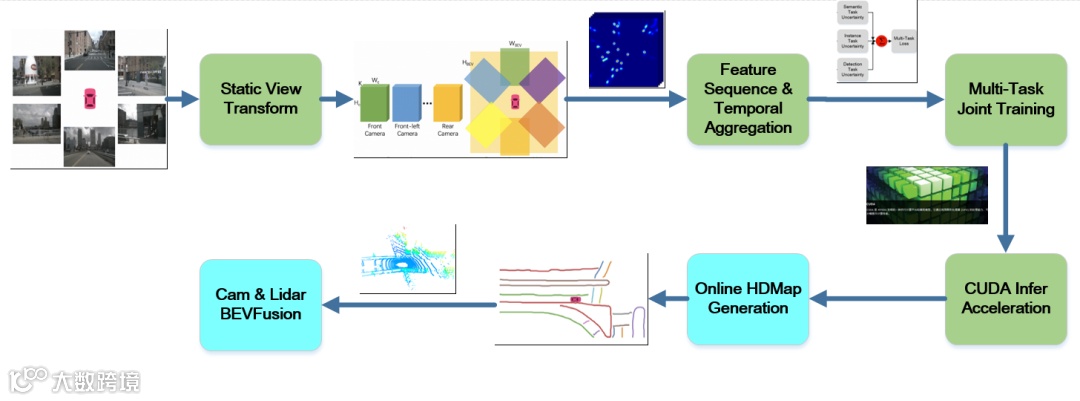
在第一个阶段中,采用基于单帧多相机图像的BEV感知方法。图像视角特征与深度分布通过张量外积,产生各个相机预定义的视锥体点云特征,而后由各个相机的外参数将其投影到BEV空间,完成图像到BEV视角的转换,同时CNN网络进一步提取BEV空间特征,并在BEV下进行语义分割和3D目标检测。
第二个阶段中,觉非通过多帧时序特征叠加的感知方案,将n-1组历史时刻的图像经BEV特征编码,得到时序的BEV特征并加入特征序列中,根据车辆位姿变换,将历史时序的BEV特征变换到当前时刻参考坐标系下,并与当前时刻的BEV特征聚合。
多帧时序特征叠加的感知方案,在性能上明显优于单帧感知,主要体现在提高遮挡目标的召回率、目标的位置等,同时车辆速度、航向角回归的准确度提升显著。
在第三个阶段的发展中,觉非设计出了兼顾BEV3D检测、语义分割、实例分割的多任务训练框架,该框架具备以下特点:
- 检测与分割的multi-head结构
- 共享复杂的camencoder特征
- 节约推理耗时


BEV感知联合训练架构
同时,觉非也提出了多任务训练框架下的联合训练策略。在训练过程中,能够实时计算3D检测、语义分割、实例分割各任务损失的同方差不确定因子。
训练过程损失权重可以做到自适应调节,且不同scale的损失也可同步收敛,这使得multi-head网络中的参数权值能同步迭代更新。
图例:左侧6路图像和BEV3D检测框投影到图像
右侧:BEV3D检测结果,绿色框-ego car;彩色区域-实例分割;靛蓝色框-BEV3D检测框
感知距离:以自车为中心,前后左右各50m
为了节省算能并提升算力,觉非在第四阶段的发展中,采用CUDA多线程的方式并行计算BEV下各个网络视锥点云的特征聚合,用CUDA的kernel function来对每个网格内视锥点云的特征进行sumpooling,而这也让模型前向推理中的视角变换模型,在速度上提升了40倍,使BEV感知得以满足车端实时推理的需求。
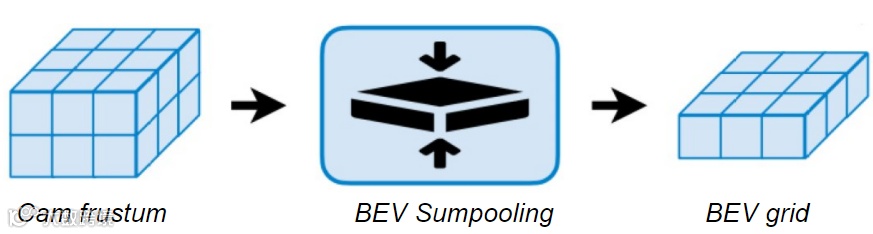
用CUDA核函数实现视锥点云特征的sumpooling
BEV是产业全新的感知范式,也为自动驾驶在高精定位与轨迹预测等技术的发展带来了更大的拓展空间。而在下一阶段的发展中,觉非科技也将依托自身在数据积累与融合感知上的技术优势,推动BEV感知在自动驾驶不同场景的迭代与实践。
1. Jonah Philion and Sanja Fidler. Lift, Splat, Shoot: Encoding Images From Arbitrary Camera Rigs by Implicitly Unprojecting to 3D. In ECCV, 2020.
2. Anthony Hu, Zak Murez, Nikhil Mohan, etc. FIERY: Future Instance Prediction in Bird’s-Eye View from Surround Monocular Cameras. In ICCV, 2021
3.Junjie Huang, Guan Huang, Zheng Zhu, Yun Ye, and Dalong Du. BEVDet: High-performance Multicamera 3D Object Detection in Bird-Eye-View. arXiv, 2021.
4.Alex Kendall, Yarin Gal, and Roberto Cipolla. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
5. Zhijian Liu, Haotian Tang, Alexander Amini, etc. BEVFusion: Multi-Task Multi-Sensor Fusion with Unified Bird’s-Eye View Representation. arXiv, 2022.
6. 知乎| 自动驾驶BEV感知有哪些让人眼前一亮的新方法
7. 知乎| 超长延迟的特斯拉AI Day解析:讲明白FSD车端感知视频:BEV感知联合训练推理







