

投资研策,最首要的是对于城市空间价值的准确判断。除了在传统专业研究上不断进步和深入外,在方法工具方面,如何进一步拓展认知、提高效率,也是我们一直努力的方向。
接下来,我们把镜头拉回重庆,开始普通的一天。

三天前。。。
早上,最近新员工小A匆匆忙忙地来找我。原来,部门领导B总给了小A一张Excel表格,告诉她这是市场中新增的10个招拍挂土地信息,其中最便宜的起拍价也高达数亿,需对其价值进行客观、合理、准确的判断。

按理说,项目研判是一个需要资深从业经历才能完成的任务,绝不是小A这样的新手可以做的。更何况,一来就是10个项目!
看着她有些闪烁的眼神,我微微一笑:别怕,咱有秘密武器。我指导小A使用 “重庆万科城市空间数据平台”的“土地研策”功能模块,顺利地对土地空间价值做出了预测。
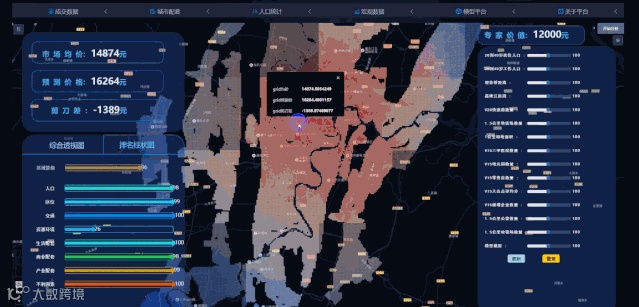
操作过程很简单:在地图上圈出项目的位置,输入容积率、主力户型等几个重要参数,点击“价值预测”,系统将自动算出预测价值,并同时给出周边项目价值作为参考。小A顺利地填上了这张表格。

带着这张表,我们一起去找B总。
B总不慌不忙地打开另一个表格:

小A恍然大悟:原来这10个项目是在最近3年内已经做过的真实项目!
没错,在使用重庆万科城市空间数据平台之前,对于土地价值判断方式,通常是通过广泛收集信息、结合业务经验进行判断的。
B总把小A的预测数据也添加到这个表上,并计算了误差:

平均而言,小A的预测结果与“标准答案”有1.92%的绝对比例误差。
小A问:“1%的准确度优势似乎微不足道。这个平台的优点,可能在于‘快’?”
我回答说:“对于周期1-3年的房地产开发项目来说,5分钟从平台拉一个数据,和人工收集整理资料、一个礼拜出结果,没有本质的差别。”
B总说:“利用这个工具,可以让曾经的价值判断走出黑箱,变得可以验证;同时计算机根据沉淀数据的‘投喂’,不仅可以快速形成认知,还可以快速缩短90%的数据收集整理时间;计算机不是要代替人,而是通过学习专业的思维模式,解决繁重、巨量的计算工作。”

从B总办公室出来,小A问我:这个预测模型背后的原理是什么?
问得好。模型可不仅仅是几行代码,它体现了重庆万科对数据的深刻认知。模型的搭建要“分六步走”。
第一步,找到靠谱的数据来源。

为了保证“靠谱”,重万对上线大数据平台的所有数据都有严格的要求:
数据资源方必须是行业内的知名企业乃至头部企业,保证数据采样覆盖面广、能够持续稳定更新,如市场数据来源自铭腾。
每套数据至少有两个来源,进行比对,修正单一数据源的原生缺陷,博采众长。例如,人口数据使用了运营商数据+政府数据进行比对修正。
定期对数据进行人工抽样验证,对数据源进行优中择优,对修正方法进行不断优化。
第二步,找到影响价值的要素。

在重万的价值预测模型中,使用了包括市场、区间位置、人口、配套、不利因素等在内的5大类10小类共177组要素。
这里并不是对数据指标进行简单的罗列。每一个指标都要经过反复的推敲。
例如,“项目到市中心的距离”是一个非常重要的房价影响要素,但重庆的“市中心”到底在哪呢?
重万的业务专家认为,重庆的市中心可能是一个区域(解放碑或观音桥)、也可能是一条轴线(长江或嘉陵江)。据此,我们建立了多个模型,分别计算以解放碑、观音桥、长江、嘉陵江作为市中心时,对重庆房价分布的解释度。结果表明,同时使用“到观音桥的距离”和“到嘉陵江的距离”两个变量来衡量项目相对于市中心的区位时,是最为准确的。

又例如,在对“商圈”进行界定时,我们并没有直接使用《商业中心规划》的图纸,而是根据全市的商业类POI(饭店、服装店、电影院、游乐设施等)的空间分布密度,使用infomap聚类算法进行组团划分,得到“重万版商圈图”。
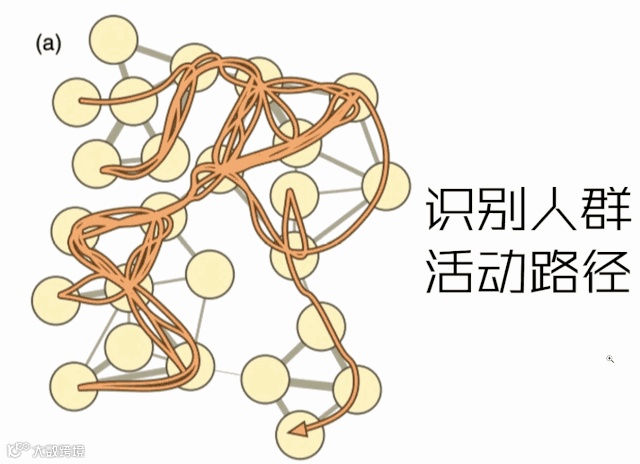
经过业务与数据科学两组工作人员之间反反复复的推敲和测算,才把这177个指标确定下来。简而言之,真正能够落地并且使用的数据模型设计必须和传统地产专业所要了解的一切知识和思维紧密结合在一起。业务人员数据化、数据工程业务化的双向融合是我们所有员工在日常工作中有意识去实践的。
第三步,对“周边”的准确定位。
土地空间价值与其周边环境关系密切,但“周边”到底是多大范围呢?
这就是视角不同会带来不一样的认知了。纯地理逻辑是以地点为中心去思考物理距离。而我们的地产专家都是从城市的视角去思考“周边”这个概念。所谓城市的视角本质上就是人的视角,对于我们居民来说所谓距离的计算单位其实是“时间”。
我们表示距离通常会说,“离你很近,步行15分钟”。所以当我们为周边划分范围的时候,地产专家认准了”等时圈“这个概念。
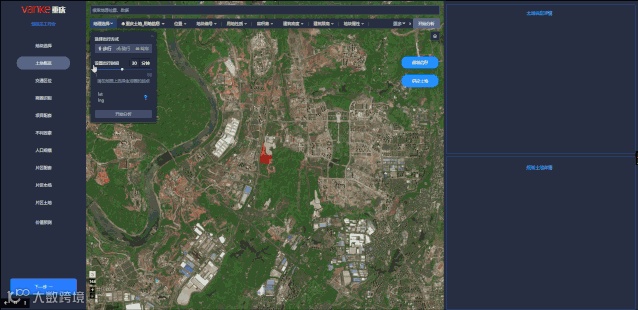
于是我们制作了步行15分钟(W15)和车行15分钟(V15)两套等时圈,分别计算两个等时圈内的各类设施数量,再用核密度的方法加权计算设施对项目的影响力大小(简单的说就是,离项目越近,影响力越大),再进行影响力的空间叠加,最终得到车行15分钟范围内每类设施的影响力指标数值。
经过测算,使用“车行15分钟等时圈”内的指标时,对房价的解释度最高。同时发现,一些指标之间存在较强的共线性。据此,我们选定“车行15分钟”作为项目“周边”的地理范围,并对指标体系进一步精简。
第四步,建立模型。

我们建立了多个模型进行项目价值的测算,其中既有经典统计学模型,也有机器学习模型。
统计学模型的优点是解释性较强,能够明确给出哪些指标对价值有影响、影响大小、影响方向,其缺点是准确度一般不如机器学习模型。
机器学习模型的优点是预测性较强。在理想状况下,价值预测的误差可以控制在5%以内,可以说是非常准确了。其缺点是,大多数机器学习模型不支持输出指标对价值的影响情况。
经过数据科学家与业务专家的反复沟通,我们最终选取了经典回归模型作为价值预测模型。
第五步,自定义调参。

模型上线不久,有业务专家指出,该模型是一个“通用评估模型”,并没有考虑每个项目的特点。例如,若项目定位的目标客群是上班族和核心家庭,则应该提高周边公共交通指标、就业机会指标和义务教育设施指标的权重;若项目的定位是休闲度假,则应该提高周边绿地公园、休闲娱乐设施等指标的权重。
考虑到这一需求,我们在基础模型上又增加了“自定义调参”环节。在这里,业务专家可以对十几个核心指标的权重进行手动调节,以期得到更加精准的价值预判结果。
第六步,模型的迭代优化

一个好的模型一定是动态的模型。为了让模型“动”起来,我们做了以下两方面的努力:
数据定期更新。平台中的市场和竞品数据每天更新、商圈和各类POI数据每半年更新、产业和人口类数据每年更新。
模型的反馈和优化。我们经常使用这个价值预测模型对历史项目和近期项目进行价值预测,然后将预测结果与实际情况进行对比。平台会把这些数据都记录下来,不定期由数据科学家进行模型的调优。今天小A做的事情,就是用模型的8.0版本对历史项目进行验证。
经过以上六个步骤,这个模型才得以建立并投入实战。

无论再微小的创新,都是一个结合内外部力量,从技术专家、到数据科学家、产品经理乃至无数业务人员经验打磨的成果。一方面,新的方法让原本的研究过程变得更有效率,也更精准。另一方面,因为有了新的思维的方法和工具,我们对城市认知也更深了一步、更细了一层。
“技术应该是为人的生活服务的,万科奉行始于人,终于人。”聚焦服务,研究市场,洞察城市,努力为客户提供更好的产品,这是万科在业务深入探索的道路上核心竞争力,也是在企业适应竞争下的未来。
说明:
1. 文中插图源自重庆万科大数据平台与研究报告;平台内主要数据由重庆万科、铭腾机构和脉策数据提供。
2. 文中人名为虚构;
3. 本文内容仅做参考,不作为任何的要约或承诺。


