

特征工程是机器学习中不可或缺的一部分,在机器学习领域中占有非常重要的地位。
特征工程,是指用一系列工程化的方式从原始数据中筛选出更好的数据特征,以提升模型的训练效果。
业内有一句广为流传的话是:数据和特征决定了机器学习的上限,而模型和算法是在逼近这个上限而已。
由此可见,好的数据和特征是模型和算法发挥更大的作用的前提。
特征工程通常包括数据预处理、特征选择、降维等环节。

一.数据预处理
数据预处理是特征工程中最为重要的一个环节,良好的数据预处理可以使模型的训练达到事半功倍的效果。
数据预处理旨在通过归一化、标准化、正则化等方式改进不完整、不一致、无法直接使用的数据。具体方法有:归一化、标准化、离散化、二值化、哑编码
针对错误及缺失的处理 在进行机器学习建模之前,需要进行特征加工。 特征加工的第一步就是对缺失和错误的数据进行处理。 具体来说,对于数据有误的,如果整列特征大部分有误,就应该删除该特征,以避免噪声对模型训练的影响; 如果个别样本在某一/某些重要特征上有误,就应该考虑删除该样本。 需要特别注意的是,在面板数据中,在删除样本时不应该只删除一个观测点,而应该删除该样本在所有时间截面上的观测点。 另外,有的错误数据是可以矫正的,比如格式不统一的数据。 对于缺失的数据来说也一样,如果重要的特征缺失,我们就应该考虑删除这些样本(即删除所在行); 对于不重要的且大规模缺失的特征,我们就应该考虑删除这样的特征(即删除所在列); 对于不重要的但不是大规模缺失的特征,我们就可以考虑填充缺失值,例如使用特征的中位数/众数/平均数/滞后一期数/提前一期数/插值等进行填充,具体的填充方案应该视该特征的含义和经验而定。 最后需要强调的一点是,我们应当明确缺失样本和缺失值为0的样本的区别,在实际处理中,我们常常会用0对缺失值进行填充,这导致了该特征本来就取0的样本和缺失样本被混为一谈,有时候通过独热来表明哪些是缺失样本,哪些是缺失值为0的样本是非常重要的。 |
二.特征选择
不同的特征对模型的影响程度不同,我们要自动地选择出对问题重要的一些特征,移除与问题相关性不是很大的特征,这个过程就叫做特征选择。
特征的选择在特征工程中十分重要,往往可以直接决定最后模型训练效果的好坏。
常用的特征选择方法有:过滤式(filter)、包裹式(wrapper)、嵌入式(embedding)。
三.降维
如果拿特征选择后的数据直接进行模型的训练,由于数据的特征矩阵维度大,可能会存在数据难以理解、计算量增大、训练时间过长等问题,因此我们要对数据进行降维。
降维是指把原始高维空间的特征投影到低维度的空间,进行特征的重组,以减少数据的维度。
降维与特征最大的不同在于,特征选择是进行特征的剔除、删减,而降维是做特征的重组构成新的特征,原始特征全部“消失”了,性质发生了根本的变化。
常见的降维方法有:主成分分析法(PCA)和线性判别分析法(LDA)。
主成分分析法
主成分分析法(PCA)是最常见的一种线性降维方法,其要尽可能在减少信息损失的前提下,将高维空间的数据映射到低维空间中表示,同时在低维空间中要最大程度上的保留原数据的特点。
主成分分析法本质上是一种无监督的方法,不用考虑数据的类标,它的基本步骤大致如下:
数据中心化(每个特征维度减去相应的均值)
计算协方差矩阵以及它的特征值和特征向量
将特征值从大到小排序并保留最上边的N个特征
将高维数据转换到上述N个特征向量构成的新的空间中
此外,在把特征映射到低维空间时要注意,每次要保证投影维度上的数据差异性最大(也就是说投影维度的方差最大)。
我们可以通过下图来理解这一过程:
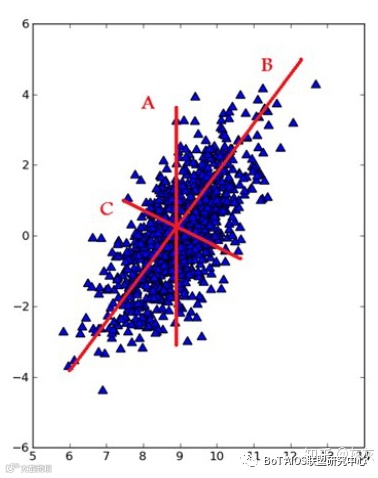
线性判别分析法
线性判别分析法(LDA)也是一种比较常见的线性降维方法,但不同于PCA的是,它是一种有监督的算法,也就是说它数据集的每个样本会有一个输出类标。
线性判别算法的核心思想是,在把数据投影到低维空间后,希望同一种类别数据的投影点尽可能的接近,而不同类别数据的类别中心之间的距离尽可能的远。
也就是说LDA是想让降维后的数据点尽可能地被区分开。

