
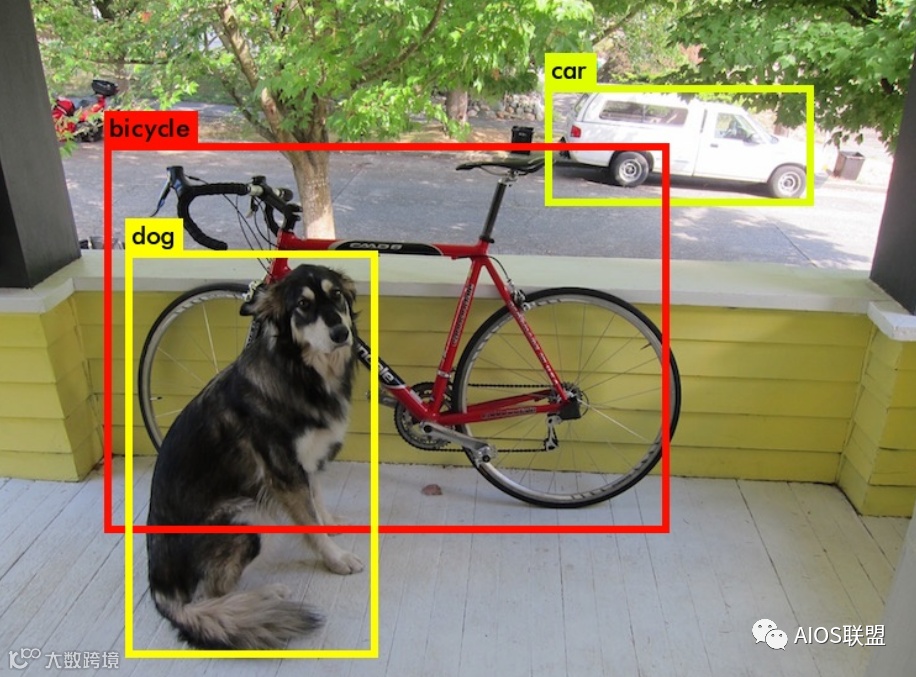
不仅能够对图片中包含的对象是什么进行识别,还能够识别出图像所在位置及大小,对其进行框选。
R-CNN
区域卷积网络R-CNN,采用了滑动窗口的策略来进行区域推荐, 确定多个可能的目标图位置,再对每个推荐位置上的图片进行特征提取与分类判断。包括:区域推荐、特征提取、区域分类、区域修正四个步骤。

1) 输入测试图像,利用选择性搜索(像素聚类)等算法在图像中从上到下提取2000个左右可能包含对象的候选区Region Proposal。
2) 将每个候选区域缩放成统一的大小227*227,输入到CNN,将CNN的fc7层的输出作为特征。
3) 将每个候选区提取到的特征输入到每一类的SVM分类器,判别是否属于该类,取分类得分在前面的候选区。利用重叠区域计算,来判断候选区是否同一目标,取不同目标得分最高的。
4) 将得分最高的候选区域放到回归器中进行区域修正,确定精确的位置(x,y,w,h)值。
较大的识别库:一千万图像,1000类(预训练),标定类别
较小的检测库:一万张图像,20类(调优参数,评测),标定类别、位置。


问题:
1. 选择型搜索找出所有候选框非常耗时;
2. 2000多个候选框都要做卷积计算,计算量大,识别慢,一张图需47秒。
Fast R-CNN
解决每个候选框都要独立经过CNN花费时间多问题。
解决办法:共享卷积层,不是每一个候选框都当作输入进入CNN,而是输入一张完整的图片,在第五个卷积层再得到每个候选框的特征(候选框映射到conv5上)。
Fast R-CNN 与 R-CNN比变化
1) 候选框特征的获取方式不同
R-CNN:几千个候选框——分别CNN——得到每个候选框的特征——分类+回归。
Fast R-CNN:一张完整的突破——CNN——得到每张候选框的特征——分类+回归。
2) 深度学习网络采用了SPP-NET模型
最后一个卷积层加了一个ROI pooling layer ,ROI是SPP-NET精简版,将特征下采样到一个7*7的特征图。对于VGG16网络Conv5_3有512个特征图,这样所有region proposal对应了一个7*7*512维度的特征向量作为全链接层的输入。
3) 多任务损失函数
直接使用softmax替代SVM分类,同时利用多任务损失函数,边框回归也加入到了网络中。回归与分类合并成一个multi-task模型,共用卷积特征,并相互促进。是Region Proposal+CNN框架。这样整个的训练过程几乎达到端到端的(除了Region Proposal阶段)。
| R-CNN | Fast R-CNN | |
| Taining Time | 84h | 9.5h |
| Test Time per image |
47s | 0.32s |
存在问题:选择型搜索找出所有候选框非常耗时。
Faster R-CNN
加入一个提取边缘的神经网络,也就是说找到候选框的工作也交给神经网络来做。引入区域推介网络Region Proposal Net work(RPN)替代Selective Search 。将RPN直接放到最后一个卷积层后面,直接训练得到候选区。
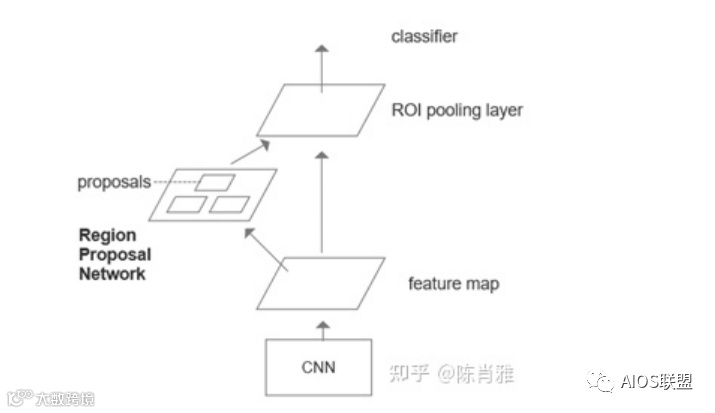
RPN详解
输入:图像卷积后的特征图。
输出:带有得分的矩形目标推荐者。

1) 滑动窗口,提供大致的物体位置信息
遍历特征图的每个位置,以此为中心提取不同尺寸、比例的窗口,每个窗口成为一个锚点。3个尺寸:1282、2562、5122,3大小比例:1:1、1:2、2:1,一个位置9个锚点。
2) 对每个选定的窗口进行卷积操作,最后提取到256维的特征(每个窗口)——intermediate
卷积核:n x m(窗口长宽)
原卷积特征图通道数:256
中间层维度:256
假如有k个特征窗口,便有k个256维的特征向量。
3) 每个窗口对应的256维向量输入到cls layer,判断是否前景图(二值分类:前景、背景)。
每个窗口的特征变量最终输出一个二位得分,k个特征窗口(锚点)的输出值有2k个。
正样本:第一类是与真实边框的交并比最高的锚点。第二类是与任意一个真实边框交并比高于0.7。
负样本:与所有真实边框的交并比都小于0.3.
4) 对判定为正样本的窗口进行回归修正——reglayer
问题:单独的训练RPN跟fast rcnn,分别只考虑它们各自的损失函数。
YOLO 你只看一次
这种方法将目标检查设计成一个回归问题,包括对多个边框和相关类别概率的回归。只用一个神经网络和一次评价,就直接从输入的整幅图像预测边框和类别概率。正因为整个检查流程是一个网络,所以它可以直接进行端对端的优化。作为一种传统结构,它的运行速度非常快,每秒可以实时处理45帧图像。
将图片分割成若干网格,每个网格记录目标物体相关的信息数据。每个网格负责“中心在该格子的目标”检测,采用一次性预测所有格子关联目标的置信度、box、定位以及跟所有类别匹配的概率向量。
每个边框都有5个预测值:x、y、w、h、confidence。
—confidence:置信度,表示边框内含有对象目标的可信度和精确度有多大。预测边框与真实边框的IoU值。
—x、y、w、h:目标物相对网格的位置、大小。0到1之间的比例系数来表示。
此外,每个网格还要预测C个条件别类概率Pr(Class|Object),表示网格包含对象目标的类别概率。
YOLO的预测结果(或网络输出)可以编码为一个S*S*(B*5+C)的张量。每个网格只预测一组类别概率,与预测的边框个数及大小无关。
S*S:网格数;B:边框数;C:类别概率数。

SSD单次检测器
SSD在不同层的feature map上进行预测,而不只是最后一层;
采用了faster-rcnn的锚点方法,在不同层的feature map上的每个点同时获取6个不同的BB(目标选框),后续通过softmax分类+bounding box regression获得真实目标位置。对于不同的feature map选择不同尺寸的默认box。
浅层卷积层对边缘更感兴趣,可以获得一些细节信息,而深层网络对抽象特征感兴趣,可以获得一些语义信息,浅层感受眼小,深层感受野大。不同层结合使用检测效果更全面。
