

去年(也就是2021年的某一天)一个朋友说:如果从业十几年都还在做“增删改查”这种初级工作的PD,一定缺乏数据建模思维的PD;小编自己虽然也擅长各种中间件的抽象设计,但是确实在数据建模一块从未考虑过,因为一直认为那是技术工程师该做的事,所以当时的心情很不美好。
为了不被鄙视,小编决定基于已有的数据资产管理体系产品设计方案,迭代升级规划搞定它,并同时进行各种资料的收集整理,并分享给各位同行爱好者。
数据建模的过程就是搭建标准数据与业务流程处理之间的桥梁的过程。
数据建模是与业务建模同步进行的,是在数据标准的框架约束下进一步让数据与具体业务联系起来的重要步骤,和业务模型没有关联的数据可以大胆地舍弃掉。
模型一般需要分多个层次,不同层次的模型有不同的展现方式,并且每一层都由上一层转换计算而来。

(图:产品原型设计——元数据建模)
关系型数据建模
从百度上搜索资料可得知,这类数据的建模理论是最广为人知的,该理论来源于埃德加·弗兰克·科德(EdgarFrank Codd),其被誉为“关系数据库之父”。
Codd在创造了关系型数据库的概念之后,又进一步提出了几个设计关系型数据库的原则——范式,后人经过不断的发展,提出了更多的范式要求。在数据标准框架下,结合范式建模理论,可以确定关系型数据的模型关系。
关系型数据(也叫二维表),一般把横向的数据称为记录,把纵向的数据称为记录的字段,也叫属性值。关系型数据最重要的3个范式如下:
1)第一范式:要求属性是不可再分的描述,总是以一个整体出现,例如地址栏不应拆分成国内和国外的业务需求。
2)第二范式:属性中必定存在一个主属性,也叫主键,其他非主键与主键组合成一条记录,这条记录是唯一的,并且可以通过主键来标识这条记录。
3)第三范式:属性只依赖主键,属性之间不存在推导关系,即如果一个属性能通过其他属性推导出来,就应该单独设计一张表,两张表进行关联(join)。
数据仓库建模
数据仓库之父比尔·恩门(Bill Inmon)的范式建模
各种资料综合了解,范式建模的理论受到了传统关系型数据库建模理论的影响,在Inmon看来,数据源就是多样化的,必须经过ETL(抽取、转换、加载)清洗过后才能进入明细层(即DW层,此层符合上面描述的关系型数据建模的第三范式),再从DW层又经过ETL计算后选择进入各应用DM层,即数据集市层,最后在各集市层中生成最终业务需要的Cube(业务处理逻辑),并提供后续输出展示。
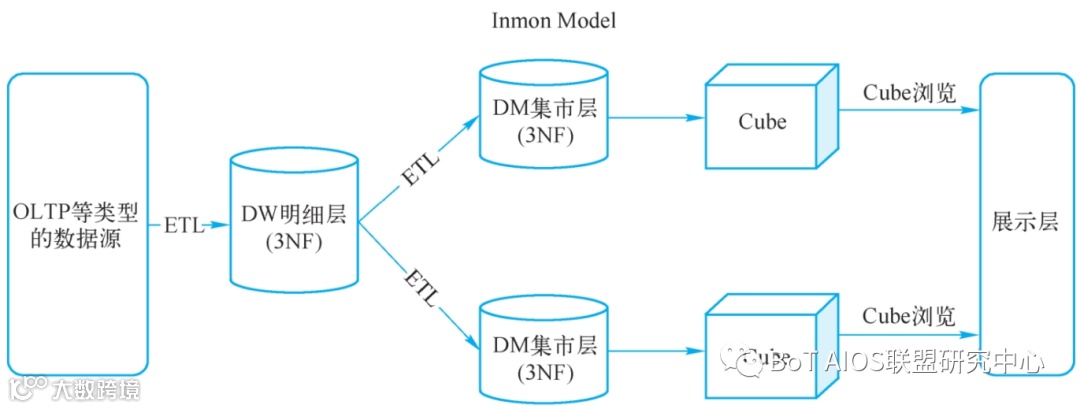
Inmon范式建模理论流程示意图
在上述过程中,ETL占据了比较大的比重,因为数据都根据范式设计分散在各数据表中,数据表记录了与其他表之间的“关系”,最后的结果需要进行必要的连接计算才能得到。

表之间的关系表示
Inmon的建模与架构设计理论适合大型而且复杂的业务,因为schema(字段名称等元数据)要求相对严格,后期变动造成的成本大,所以在设计阶段就应该投入较长时间。
2.数据仓库先驱Ralph Kimball的维度建模
Kimball认为数据仓库的数据肯定是来源于数据集市的,集市的数据经过ETL过程之后再进入DW层,而DW层中的数据不再细分,直接在DW中计算Cube(业务逻辑处理),再把Cube结果输出。
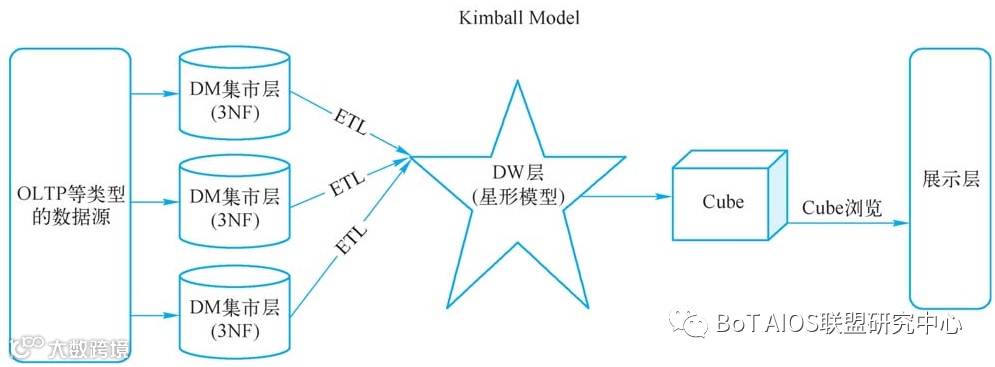
Kimball维度建模理论流程示意图
Kimball淡化了“关系”的存在,直接把关联字段设计在事实表中,其他的“关联”表则通过“维度”的形式分布在事实表的周围,形成了星形结构(星形模型)。
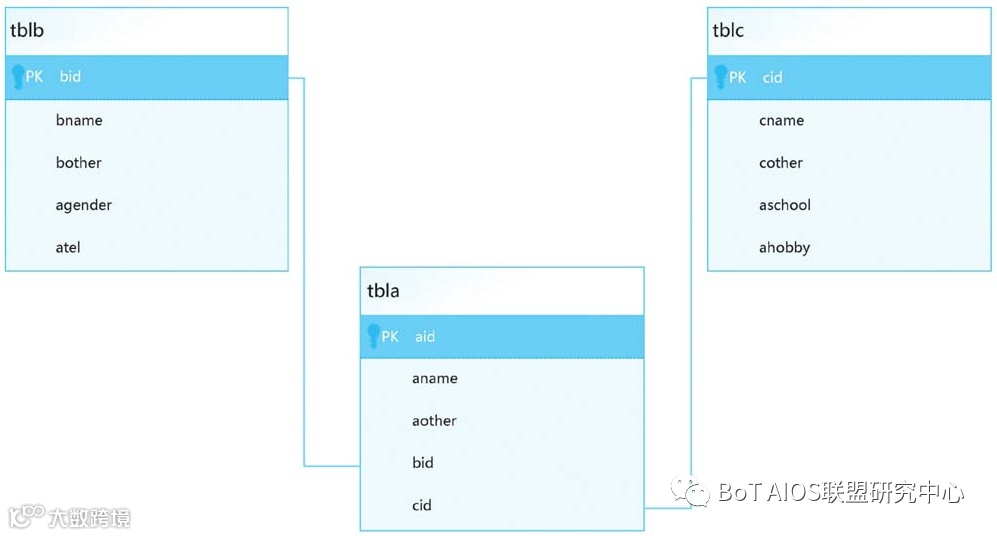
星形结构
Kimball的维度建模相对灵活,对事实表及维度表的schema要求都不高,而且一般经过性能的权衡后会有一定的数据冗余存在,适合快速开发的产品参考使用。
非关系型数据建模
非关系型数据一般对schema的要求较低。
(1)半结构化数据
对于半结构化数据,不要求每条字段都必须包含所有属性,但是系统中仍然必须包含全量属性信息,只是对数据进行读取计算时由业务需求自行取舍。

(2)非结构化数据
对于非结构化数据,可以提取转化成结构化数据的,按照结构化数据建模,不能提取的蜕化为业务组合建模、分区建模或索引建模等。数据建模的目的一个是为了表达业务,另一个就是为了使用方便。对于非结构化数据不再拘泥于传统结构化数据的schema建模,只要能达到上述目的即可。
通用建模步骤
虽然不同的数据建模方法适用的场景不一样,但是不论哪一种方式都可以划分为概念建模、逻辑建模和物理建模这几个阶段。
1.概念建模
概念建模阶段也可以理解为业务——实体抽象映射阶段,主要完成下面几个方面的工作:
(1)深入需求沟通与业务部门或者客户沟通需求,形成零散需求记录。
(2)梳理核心业务流程根据零散需求梳理业务主流程,并与业务专家确认,输出主要业务节点。
(3)建立业务对应实体划定业务中的主要参与单元的粗粒度边界,以此为标准定义出参与业务的实体。
2.逻辑建模(可视化的“逻辑编排工具”在低代码、物联网、大数据等技术场景中都有较大的需求权重)
逻辑模型就是把概念建模阶段的实体具象化的过程,主要完成下面的工作:
(1)详细描述实体概念建模阶段确定的实体是抽象的业务单元,在逻辑建模阶段就要充分地描述这个实体,例如唯一标识符、属性、维度、度量等。
(2)建立实体存储模型实体通过具体的描述信息丰富起来后,需要结合数据标准,建立存储的模型,因为任何数据进入平台都会以一定的形式存在于平台内部。
1)结构化数据可以定义表结构、表约束,表视图、表关系等。
2)半结构化数据也可以定义一定的schema,便于存储系统存储。
3)非结构化数据则可以从命名、数据编码形式等方面以元数据+数据的形式来表示。
3.物理建模
物理建模阶段其实就是落库的阶段,把前面定义好的、已经丰富过的、满足数据标准的实体存起来,具体包含以下几个方面的工作:
(1)存储系统选择结构化数据存储一般选择关系型数据库管理系统(RDBMS),这时可以定义各表的DDL(Data Define Language,数据定义语言)语句。
半结构化数据选择NoSQL(非关系型的)数据库,根据数据类型的不同可以选择对应的存储方式,例如文档型数据存MongoDB,列式数据存HBase,Key-Value键值对形式的数据存Ignite等。对于非结构化数据,根据数据大小可以选择HDFS(分布式文件系统)进行文件存储、Ceph对象存储等。
(2)数据分区与合并如果数据量很大,一般需要采取存储系统的分布式存储功能——分区存储;如果数据量很小,则需要合并数据到一个block(块),以节约空间。
(3)数据使用解决了数据如何存储的问题其实也就决定了数据如何使用的问题,例如列式存储就决定了读取数据时不应该按行读取,这样会有严重的性能问题。同样,数据分区存储就不应该过多强调强一致性的事务,而大文件采取块存储之后就不应该有单条、单页(page)的数据操作。
