
集成物理信息神经网络、深度主动学习与深度强化学习的代理优化框架:多层薄膜案例研究

✅ 第一层:论文总结
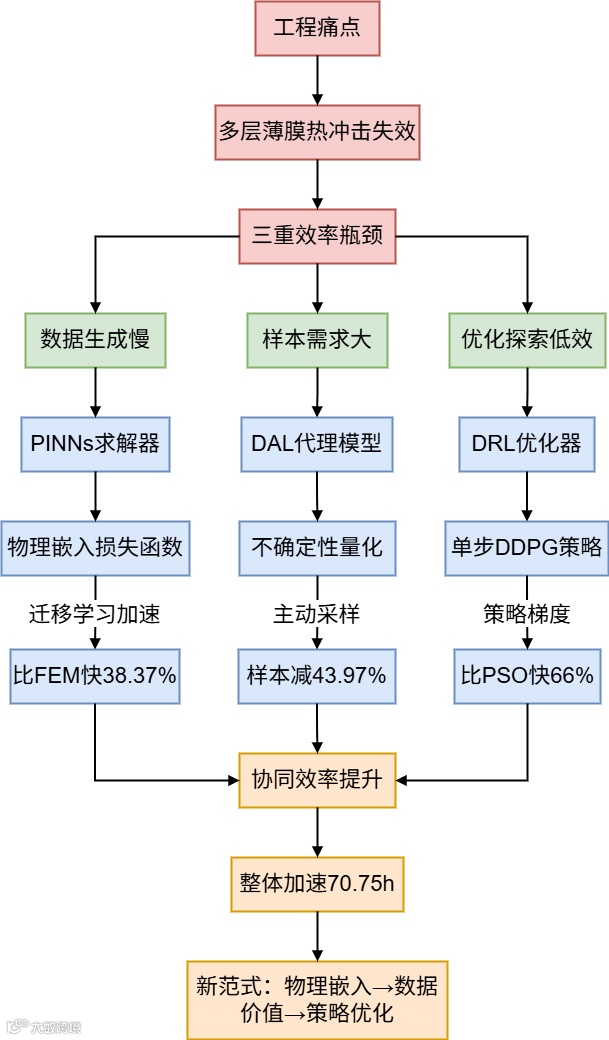
该论文发现了一个关于工程优化效率瓶颈的真问题:传统代理优化方法面临数据生成慢、样本需求大、设计空间探索低效三大挑战。其核心硬挑战在于如何实现全流程协同加速。作者提出了PINNs+DAL+DRL三阶段耦合框架的巧方法:物理约束加速求解(PINNs)、不确定性指导采样(DAL)、策略梯度驱动优化(DRL)。该方法取得端到端效率提升70.75小时的强效果,最终凝练出AI组件协同集成可突破单一模块优化极限的新见解。
✅ 第二层:战略完整拆解
-
• 领域:极端环境用多层薄膜器件(如航空航天热防护传感器) -
• 痛点:热冲击导致薄膜破裂,传统实验/仿真优化周期长(单案例FEM耗时0.75h)、资源消耗大。

-
• 三维效率瓶颈: -
• 数据生成:传统数值方法(如FEM)需全参数重复求解 -
• 代理训练:随机采样需115个样本 -
• 优化搜索:启发式算法(PSO/GA)易陷局部最优且迭代慢
-
• 三阶段耦合架构: 组件 创新点 "巧"之所在 PINNs 域分解+迁移学习 复用物理知识,提速38.37% DAL Monte Carlo Dropout不确定性量化 样本需求↓43.97% DRL 单步策略梯度 搜索效率↑66% vs PSO/GA -
• 协同机制:DAL训练后直接作为DRL环境,规避PINNs实时调用计算成本。
-
• 量化验证: -
• 精度:PINNs相对误差<0.68%,DAL的 -
• 效率:端到端节省70.75小时,较传统方法↑81.7% -
• 物理可解释性:SHAP分析揭示 厚度主导失效
-
• AI协同效应:组件级优化(PINNs/DAL/DRL)存在协同增益( ) -
• 通用范式:适用于需"仿真-代理-优化"链条的领域(航空航天/能源器件)
✅ 第三层:全局架构与核心精粹
-
• 摘要翻译: 代理优化广泛用于各领域,但现有框架存在数据生成慢、训练样本多、设计空间探索效率低等缺陷。为此,我们提出融合物理信息神经网络(PINNs)、深度主动学习(DAL)、深度强化学习(DRL)的新型框架:PINNs通过迁移学习加速数据生成;DAL量化样本不确定性,以少量样本训练高精度代理模型;DRL以该模型为环境探索优化策略。以多层薄膜热冲击优化为案例,结果显示:PINNs提速38.37%(误差<0.68%),DAL样本效率提高43.97%,DRL较PSO/GA提速66%。整体框架减少70.75小时计算,展现高效工程潜力。
-
• 结论翻译: 本文首创PINNs+DAL+DRL全流程优化框架。实验表明:1)PINNs(迁移学习)提速38.37%;2)DAL(主动采样)样本效率升43.97%;3)DRL(策略梯度)较粒子群/遗传算法提速66%;4)框架总耗时降70.75小时。通过可解释模块(SHAP/PCA)揭示设计规律(如最小化 厚度)。该范式为复杂工程优化提供通用解决方案。
✅ 第四层:理论基石——背景知识系统补全
核心理论体系
-
1. 热机械耦合理论: -
• 控制方程: -
• 热传导: -
• 力学平衡: -
• 失效准则:力-热等效能量密度原理:
-
2. 主动学习理论: -
• 核心思想:模型自主选择"信息量最大"样本 -
• 量化工具:Monte Carlo Dropout
关键术语深究
|
|
|
|
|---|---|---|
| PINNs物理嵌入 |
|
|
| DAL不确定性 |
|
|
| DRL单步策略 |
|
|
直观类比
优化框架如汽车制造:
• PINNs = 高速生产线(物理定律为流水线设计图) • DAL = 智能质检员(仅抽检关键零件) • DRL = 自动驾驶系统(实时调整装配策略)
✅ 第五层:数理模型与算法逻辑
数学模型全解
-
• 温度场网络 : -
• 输入: → 输出: • 损失函数
其中
-
• 输入同温度场 → 输出: • 损失函数 含应力平衡约束
-
WHILE R² < 0.999:
1. 用当前数据集训练代理模型
2. 对未标注样本计算预测方差 Var(T_f)
3. 选择 Var(T_f) 最大的样本 → PINNs求解 → 加入训练集
-
• 状态:当前膜厚设计 • 动作:膜厚调整量 (连续空间) • 策略更新:
✅ 第六层:工程实现与数据流
数据生命周期图

技术栈说明
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
✅ 第七层:结果验证与图表解析
全图表解析










|
|
|
|
|
|---|---|---|---|
| 图7i |
|
|
|
| 图8b |
|
|
|
| 图9c |
|
|
|
| 图10a |
|
|
|
| 图11a |
|
|
|
✅ 第八层:思维洞察
隐含假设
-
1. 单向热力耦合:忽略应力对传热影响 → 分步求解温度/应力场 -
2. 线性弹性材料:排除塑性/蠕变 → 仅适用脆性陶瓷薄膜
精妙处理
-
1. 环境代理解耦:用DAL代理替代PINNs作为DRL环境 → 避免实时仿真开销 -
2. 两阶段优化器:PINNs训练先用Adam后切L-BFGS → 加速收敛
思维转折点
-
• 从组件替换到协同设计:现有工作仅替换1-2个模块 → 本文首次三模块联合优化
✅ 第九层:知识迁移与拓展
可迁移方法论
-
1. 物理嵌入模板: -
• 对任何PDE控制问题,按式20格式构造加权损失函数 -
2. 分层采样协议: # DAL主动采样伪代码
while model.R² < target:
candidates = unlabeled_pool.sample(N)
uncertainties = mc_dropout_predict(candidates)
new_sample = candidates[argmax(uncertainties)]
label = solver(new_sample)
dataset.add(new_sample, label)
复现与改进路径
-
1. 复现步骤: -
• Step 1: 用DeepXDE实现多域PINNs -
• Step 2: 基于TensorFlow构建含MC Dropout的DAL -
• Step 3: 单步DDPG优化 -
2. 改进方向: -
• 深度算子网络:用DeepONet替代PINNs→参数化问题单次训练 -
• 多智能体DRL:并行探索 → 解决高维早熟问题
未来建议
-
• 工业融合:与CAD/CAE工具链集成 → 光电器件/燃料电池优化 -
• 动态约束:加入制造工艺约束(如沉积厚度极限)→ 提升实用价值
📌 本论文的通用知识迁移总结
