

机器学习本质
机器学习的本质是通过模型训练来挖掘变量与变量之间的关系,再利用关系函数,从已知变量的数值来推测未知变量。
我们通常将已知变量称为“特征变量”,要推测的未知变量称为“目标变量”。一般特征变量是可观测变量,可对样本进行直接观察测量得到数据,目标变量是不可观测的潜在变量,需要通过观测变量推导出数值。
比如:想要知道某个西瓜是否好瓜,需要从瓜的纹理、根蒂、敲声、色泽等特征进行推测。这里是否好瓜是目标变量,纹理、根蒂、敲声、色泽等是特征变量。
特征变量与目标变量之间如果有比较强的相关性,预测效果会比较好。
根据目标变量的数据类型是连续还是离散,可将机器学习算法模型分为“回归算法”与“分类算法”。如果要预测的目标变量数据类型是连续的数值型,需采用回归算法,比如预测下个季度房价的成交价格是多少;如果要预测的目标变量数据类型是离散的类别型,需采用分类算法,比如预测下个季度房价是涨还是跌。
监督与无监督学习
上面提到机器学习需要通过模型训练来挖掘变量之间的关系。根据模型训练的不同方式可将机器学习监督学习与无监督学习。
监督学习需要对样本数据中的特征值与标记的目标值进行学习,得到特征变量与目标变量之间的函数关系。
比如,要想从纹理、根蒂、敲声、色泽等特征预测西瓜是否好瓜。需要找一批样本瓜,将每个瓜切开来,人为标记下是好瓜还是坏瓜。再选择一种分类器,输入样本瓜的纹理、根蒂等特征值及对应的标记好的是否好瓜数值进行训练,得到分类器的参数值。训练完成后,利用该分类器就可以预测其它西瓜是好瓜还是坏瓜。分类器实际上是一种从自变量(x1、x2…,特征变量)到应变量(y,目标变量)之间的映射函数f(x1,x2…)。训练之前该函数通过选型确定基本的结构,但关键的参数值是未知的,模型训练,实际上是确定该函数的各个参数值,所以训练后得到的完整的分类器,实际上描述了特征变量与目标变量之间的内在关系。

无监督学习无需对样本的目标变量进行标记,可以直接对样本的特征量进行计算分析,得到分类判断标准。聚类算法是最常见的无监督分析模型。
常见分类算法
分类算法都是监督学习,常见的有感知器、逻辑回归、支持向量机、随机森林、贝叶斯、神经网络。其中神经网络,同一个网网络的输出可同时包含回归、分类。
感知器模型
a) 感知器模型结构
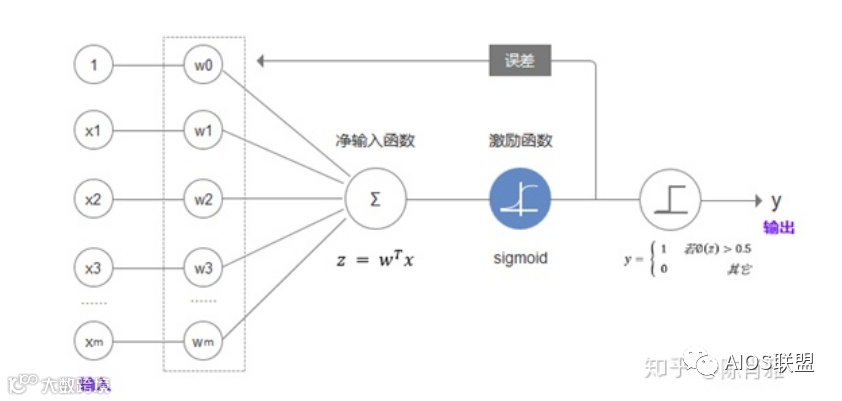
感知器实际上是人造神经元(是神经网络的基本单元),根据输入值:x1 、x2 、x2 、x3 …xm,来预测输出值:y。输入与输出的关系如下图所示:

这里我们假定该感知器(即分类器)是已经训练好的,其中w0 、w1、w2、w3…wm 为感知器的参数,这里表示各个输入的权重值,如果感知器训练好了,这些参数也就定了。感知器实际上表示的是输入x与输出y之间的函数关系,输入确定了,就能求出相应的输出。这里的感知器是用于分类的,所以y值是二分类的,有1,、-1两种,分别表示对应的类别。
b) 感知器模型训练
对应不同的分类目的,都需要训练相应的感知器(也叫分类器)。感知器的创建首先得假设输入(x)与输出(y)之间的数量关系是建立在特定结构的函数模型上的,比如上图所示的净输入函数、激励函数、量化器,但是这些函数的参数是不确定的,比如:w0 、w1、w2、w3…wm 是未知的。感知器的训练就是通过一批x、y已知的样本数据来求出参数w0 、w1、w2、w3…wm。
当然计算机求参数不像我们直接解数据代数方程,将x、y值代入组成多组方程组,将参数w0 、w1、w2、w3…wm当成未知数,只要方程个数跟未知数一样多就能解出未知数的唯一解。一个已做标记的样本数据就能列出一个方程。这是最理想的情况,实际上ai要解决的数量关系都是基于一定概率的模糊关系。也就是说对于某个已知样,我们观测到x=a,y= b1,但x=a,y=b1并不是必然的,它可能仅仅发生在这个样本身上,没准同类的样本再来一个就会出现x=a,y=b2。如果仔细研究的话我们会发现这些b1、b2……会形成某种正太分布(如果y是连续,该模型是回归预测的话)。所以实际上我们需要更多的样本数据才能训练出参数值。
计算机训练模型求参数一般采用的是迭代法。
先任意给各参数w赋一个初始值;
输入一批样本的输入值,利用当前初始值求出输出值;
将求出的输出值y’跟样本真实的y值进行比较,看误差有多大;
如果误差太大,利用某种规则来修改参数w的数值;
直到在该参数w的数值下预测出的y’跟y的误差在允许的范围内(称其为迭代收敛);

c) 随机梯度下降
上面模型训练迭代时提到,当预测的y’值跟真实的y误差很大时,需要按照一定的规则对w进行调整,直到误差最小。
通常是根据梯度下降原理进行调整。其原理是找到w的最佳变化方式,使得模型输出与实际类标之间的误差平方和最小。我们将误差平方和写成关于w的函数J(w),称为代价函数。
该函数是个凹函数,需要找到该函数的最低点,首先得明确当前所处的位置,再找到相对于该位置而言下降最快的方向,沿着该方向往下走直到最低点。

沿着函数曲面切线的方向是下降最快的,所以得对该函数的各个未知数w求偏导。具体操作如下:
误差平方和方程:

将样本数据代入后,是关于w0 、w1、w2、w3…wj 的多元方程;
分别对w0 、w1、w2、w3…wj 求偏导 △j(w);
以△j(w)为单位进行各个w的变化;
△w1 = -η△j(w1)
△j(w1)表示变化的方向,η表示变化的程度(称为学习速率)。η为算法训练时的超参,可以不断调整,尝试性输入不同的值;定太大:会跳过全局最优解,导致误差随着迭代次数增加而增加;定太小:迭代次数增加;
逻辑回归
逻辑回归模型计算是用于分类,并非用于回归。它是在感知器的基础上做了局部优化。主要是激励函数、代价函数跟感知器模型不一样。
1) 激励函数
逻辑回归的激励函数是个sigmoid函数,也称为logistics函数。
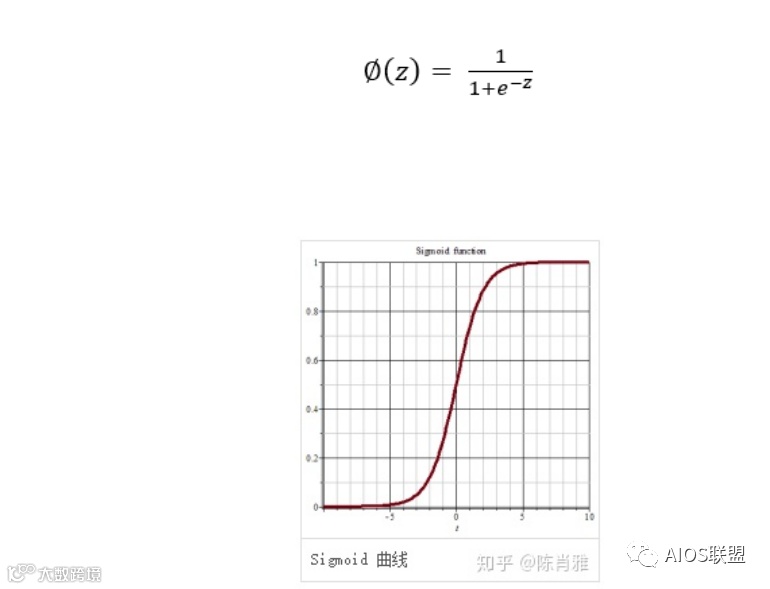
该函数相当于同时具有量化器的作用,取值在0到1之间。当z趋向∞时,结果趋近1;当z趋向-∞时,结果趋近0。0与1分别代表了两个不同的分类类别。
在0与1之间有一个中间地带,它的数值可以用于预测样本属于类别1的概率。
2) 代价函数
前面提到,感知器模型是用预测输出值跟真事值之间的误差平方和来作为代价函数的,它表示当前参数下,模型预测的误差程度。而逻辑回归模型的代价函数是对数似然函数。

yi表示各个样本的真实值,当样本为0类时,代价函数为后半部分:

,表示每个样本与真实值的误差和
当样本为1类时,代价函数为前半部分:

,表示每个样本与真实值的误差和
采用似然函数作为代价函数的有点是:能保证每次误差都大于0,不会相互抵消,又不用加绝对值或平方和,使计算更方便。
