
词语的向量化
在采用深度学习解决自然语言处理问题时, 大家可以发现几乎所有模型的处理第一步都是将词语(或字符)映射成词向量. 究其原因, 自然语言是一堆离散符号的序列, 要通过神经网络对数据进行处理, 就需要对这些离散符号向量化, 而词向量, 正是将离散符号进行向量化的一个转换:

而对于词向量 的参数的学习, 则可以通过:
的参数的学习, 则可以通过:
大家耳熟能详的Word2vec类的最大化词语之间的条件概率目标函数来完成;
或者直接对目标任务(如分类)进行训练, 通过梯度下降找到合适特定任务的词向量.
前些年基于Word2vec基本思想衍生出了一系列比较有影响力的研究工作, 如 GloVe: Global Vectors for Word Representation, 以及提出fastText的 Enriching Word Vectors with Subword Information 等.
句子的向量化
通过上述算法已经能将词语较好的映射到一个向量空间, 使得语义相近的词语分布在相近的距离. 那么一个自然的延伸问题就是, 如何将句子或文章也类似表达成一个向量呢?
直观的, 我们可以通过类似于Word2vec的思想, 将每个句子作为一个特殊的词语, 通过梯度更新预测其句子包含的词语, 同时学习句子的向量表达. 这个思路的一个具体实现算法在 Distributed Representations of Sentences and Documents有比较完整的描述.
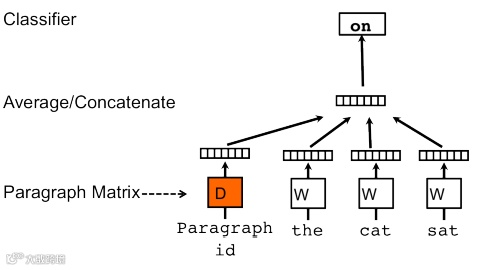
随着Recurrent neural network的流行, 大家发现给定变长的句子, 映射成定长的向量表达, 其实是RNN很擅长的一类序列到向量的映射问题. 如果我们希望将句子 进行情感分类, 可以采用:
进行情感分类, 可以采用:

上式首先通过RNN将变长的词向量"总结"为一个定长的表达 , 在通过一个简单的线性变换和Softmax函数将
, 在通过一个简单的线性变换和Softmax函数将 映射到对应类别计算概率.
映射到对应类别计算概率.

虽然概念上很简单, 但是上述的方法所训练的句子或文档的总结 依赖于特定的任务, 并不是一个通用的句子表达, 并且需要下游的任务有较多的训练样本.
依赖于特定的任务, 并不是一个通用的句子表达, 并且需要下游的任务有较多的训练样本.
是不是能够有一种更通用的从字符到句子的向量表达方式呢? 前一段时间谷歌发表的 Universal Sentence Encoder 是这类研究的一个代表, 通过对多个下游任务进行训练, 研究人员发现这样产生的句子向量具有很强的迁移学习能力.
上面所总结的方法基本都需要依赖于大量的标注数据和大量的模型参数, 如Universal Sentence Encoder的预训练用到了维基百科, 新闻, 问答, 论坛, Stanford Natural Language Inference (SNLI) 等大规模数据.

有没有不依赖于大量训练数据的句子或文章的向量化方法呢? 有! 最简单的, 莫过于直接求平均:
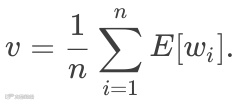
为什么平均词向量看上去挺糟糕的?
我们都知道, 在信号处理领域, 求平均直观上是一个低通滤波器, 会对原信号的细节有所损失. 直观来看, 自然语言的构成的语序至关重要, 而将词向量平均, 刚好将的语序信息完全丢失, 使得"人咬狗"和"狗咬人"的向量表达完全相同. 相当可疑!
假设对于一个d维的词向量, 每一维平均值为:

那么, 如果我们从词表中独立采样少量几个词语, 得到的平均向量的方差将会非常大. 而当我们独立随机的词语数增加, 则平均向量v会收敛到 , 缺乏不同文章之间的区分度.
, 缺乏不同文章之间的区分度.
为什么平均词向量不是一个太糟糕的想法?
我们都知道, 朴素贝叶斯(Naive Bayes)算法的特征独立性假设虽然过于理想, 但在文本分类任务上却有不少成功的应用. 对于给定文本, 我们希望估算其分类到第C类( )的概率:
)的概率:

那么,

这个与我们刚才讨论的词向量平均有什么联系呢?
我们可以考虑下面这组特殊的词向量:

没错, 当我们将向量赋予这组特殊的值时, 能够发现我们的平均词向量的分类方法, 等价于朴素贝叶斯分类器. 也就是说, 只要词向量的维度不小于类别总数K, 将平均词向量方法的分类器训练至收敛, 其效果至少应该不比朴素贝叶斯分类器的效果差!
其实, 平均词向量能取得良好分类, 在ICLR 2016的 Towards Universal Paraphrastic Sentence Embeddings 已经有很详细的比较实验. 作者总结道:
Our simplest averaging model is even competitive with systems tuned for the particular tasks while also being extremely efficient and easy to use.
上面的模型看上去很美, 结构简单, 效果良好. 唯有一个问题, 其词向量的训练是基于 PPDB: The Paraphrase Database 所整理提供的从平行语料提取的大规模相似短语, 预训练耗时较长, 并且依赖于平行语料的质量.
如果没有平行语料怎么办?
如果没有高质量与大规模的平行语料, 是不是就没有办法了呢? 普林斯顿大学Sanjay Arora教授组的研究给了一个很有意思的方案 A Simple but Tough-to-Beat Baseline for Sentence Embeddings.
这个简单又扛揍的方法是怎么样的呢? 核心是将自然语言的生成过程, 建立了一个叫做Random Walk on Discourses的生成模型.
假设 是我们对文章的向量表达, 概括了文章的语义. 这个生成模型基于下面几个直观的想法:
是我们对文章的向量表达, 概括了文章的语义. 这个生成模型基于下面几个直观的想法:
文章中某些高频词汇, 如"的", "了"等, 与文章的语义主旨无关, 可以单独刻画其生成概率
 ;
;存在一个主要跟文章主题不相关, 但与语法层面相关的向量
 ;
;
基于这样的直观, 我们可以建立如下的生成模型:

其中 ,
,  为正则化项.
为正则化项.
根据这个生成模型, 一个词语w被模型产生, 是以下三个条件之一:
与文章主题无关的随机生成, 概率为
 ;
;与文章主题向量公共的部分c0相关;
与主题高度相关的部分, 有高的内积值
 .
.
假设我们的词向量 在向量空间上的分布基本均匀, 可以得出, 正则项
在向量空间上的分布基本均匀, 可以得出, 正则项 对于不同的词语
对于不同的词语 几乎相同, 可以认为是一个常数. 基于这个假设, 可以采用最大似然估计 (MLE) 来估算最好的文章向量表达
几乎相同, 可以认为是一个常数. 基于这个假设, 可以采用最大似然估计 (MLE) 来估算最好的文章向量表达  .
.
通过对目标函数进行泰勒展开, 可以推导出最优文章主题向量的表达式:
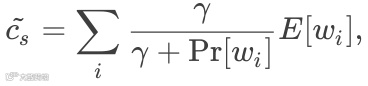
其中  为一个常数.
为一个常数.
整理一下上面推导的思路:
我们从模型需要满足条件的直观出发, 定义了Random Walk on Discourses的生成模型;
通过假设词向量
 在向量空间上的分布基本均匀, 使得正则项Z为一个常量;
在向量空间上的分布基本均匀, 使得正则项Z为一个常量;根据生成模型的形式, 通过MLE的估计, 我们得到了最优文章主题向量
 的闭合解.
的闭合解.
大家仔细观察可以发现, 我们所得到的主题向量, 恰恰就是词向量 的加权平均! 所以, 在该模型下, 对词向量的(加权)平均, 不仅仅是我们简单粗暴的偷懒, 而是理论上的最优解.
的加权平均! 所以, 在该模型下, 对词向量的(加权)平均, 不仅仅是我们简单粗暴的偷懒, 而是理论上的最优解.
最后还有一个后续, 上述算法取得的是包含c0部分的 . 为了去掉与文章主题无关的c0部分, 研究建议对文章向量所组成的矩阵进行主成分分析(PCA), 将第一个主成分进行移除. 最终形成如下算法:
. 为了去掉与文章主题无关的c0部分, 研究建议对文章向量所组成的矩阵进行主成分分析(PCA), 将第一个主成分进行移除. 最终形成如下算法:

SIF算法
可以看出, 该方法仅仅需要一个预训练好的词向量信息 以及其在背景语料的词频
以及其在背景语料的词频 . 需要的信息非常少, 即无下游的分类数据, 也没有利用平行语料等辅助数据源, 会不会效果也差强人意呢? 令人惊讶的是, 多个任务的测试显示, 这样的简单方法甚至能比一些依赖大规模辅助训练数据的算法结果还要更优秀.
. 需要的信息非常少, 即无下游的分类数据, 也没有利用平行语料等辅助数据源, 会不会效果也差强人意呢? 令人惊讶的是, 多个任务的测试显示, 这样的简单方法甚至能比一些依赖大规模辅助训练数据的算法结果还要更优秀.

这样的研究结果, 相较于大量不断堆高参数与模型复杂性的"主流"研究, 显得有那么一点"另类". 不过相比之下, 我还是更喜欢这样洗掉浓浓的烟熏妆, 还研究以直观、简洁、可证明的质朴结果. 希望这样的研究能多一些.
• end •
往期文章:关于机器学习的前尘往事
招人啦
前面都是前言,这里才是正文!
我们是一个来自牛津大学、哥伦比亚大学、UIUC、北京大学等的团队.我们刚诞生不久,每一个毛孔都是新的,等着和你一起来建设.
技术产品总监
希望你有在知名互联网/软件公司有带领技术团队完成产品开发的经验,能够有兴趣和我们一起设计AI落地的产品,切实提高行业效率.
高级前端工程师
希望你能在前端与UI交互方面有丰富的经验与产品思维,精通JS,能与团队一起落地实用的数据产品.
机器学习工程师
希望你对机器学习有热情有基础,对算法原理而不仅仅是调用库有所了解,希望真正作出有用的AI产品.
简历投递邮箱:hr@metasota.ai
