

联邦学习可以分为三类:横向联邦学习、纵向联邦学习、联邦迁移学习。
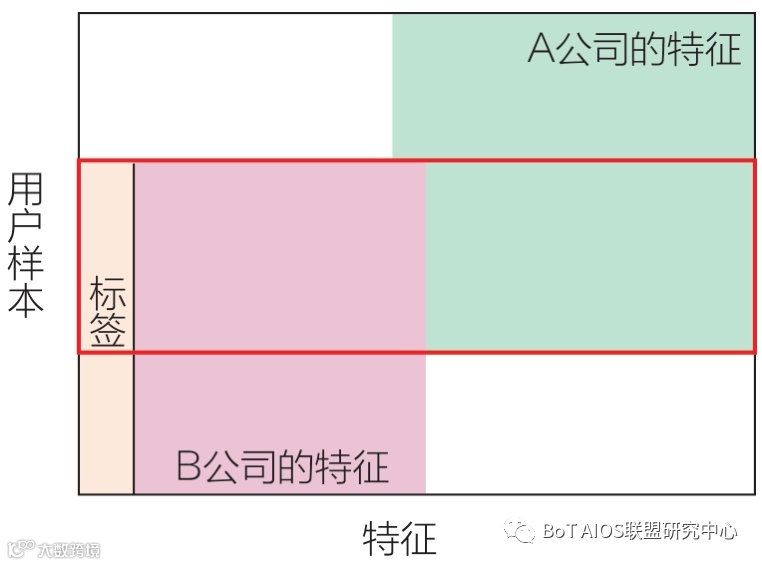
假设有处于同一个领域的两个小公司A和B,A公司和B公司都拥有各自的数据集DA和DB。 DA和DB都以矩阵形式表示,两个矩阵的行数据代表用户样本数据,矩阵的列数据代表用户特征,其中还分别拥有标签。 A公司和B公司在进行联合训练时,可能存在以下四种情况: (1)在数据集中,用户特征部分重叠较多,但是用户样本部分重叠较少。(2)在数据集中,用户特征部分重叠较少,但是用户样本部分重叠较多。(3)在数据集中,用户特征部分和用户样本部分都重叠较少。 (4)在数据集中,用户特征部分和用户样本部分都重叠较多。 |
1.纵向联邦学习
纵向联邦学习主要对应上面数据集特征的第二种情况,如果两个或者多个数据集中的相同的用户样本较多,那么我们就按照纵向切分的方式从数据集中取出用户样本完全相同但是用户特征不同的数据进行训练。
简单来说,纵向联邦学习根据特征维度进行切分,是一种基于特征维度的联邦学习方式。
目前,很多模型都已经在纵向联邦学习中得到了较好的应用,如人工神经网络模型、逻辑回归模型、随机森林模型等。
纵向联邦学习将多个参与方的数据集中的特征汇总在一起,并且通过同态加密等方式保护数据隐私安全,其中用户模型是一致的。
在纵向联邦学习中,各方都使用一致的方法模型(数据不同),因此可以通过联合模型管理所有的模型。
2.横向联邦学习
横向联邦学习的主要应用场景为用户特征部分重叠较多,但是用户样本部分重叠较少。
如果两个或者多个数据集中的用户特征部分重叠较多,那么我们就按照横向切分的方式从数据集中取出特征完全相同但是用户不同的数据进行训练。
简单来说,横向联邦学习根据用户维度进行切分,是一种基于用户样本的联邦学习方式。
比如,对于不同地区的数据运营商服务(如四川省的移动服务、云南省的移动服务等)来说,因为其分布在不同的区域,所以用户样本部分重叠较少,但是这些不同区域的业务特征是很相似的,因此特征空间的重叠区域较大。
这样的数据集就适合采用横向联邦学习的方式进行训练。

横向联邦学习的典型应用场景是“端-云”服务框架。
该场景主要针对拥有同构数据的大量终端用户,比如在互联网中使用同一个App的用户,服务商通过融合不同终端用户的数据进行联合建模。
在经过用户授权后,用户的个人隐私均不出个人终端设备(手机、平板电脑等)就可以参与模型的训练与更新。
横向联邦学习通过去中心化、分布式的建模方式在保证用户个人隐私的前提下,利用了不同用户的数据,建立了有价值的联邦学习模型。
3 联邦迁移学习
联邦迁移学习是联邦学习和迁移学习的结合体。
随着机器学习的广泛应用,在很多有监督学习场景中常常需要进行大量数据标注,这是一项十分耗时且乏味的工作,因此迁移学习就被引入了。
迁移学习的出发点是减少人工标注数据的时间,使得模型可以通过已有的标注数据将已学知识迁移到未标注的数据中。
目前,迁移学习主要应用在将训练好的模型参数迁移到新的模型中辅助新的模型进行训练。

联邦迁移学习主要对应上面数据集中的第三种情况,即如果两个或者多个数据集中的用户样本和用户特征都不太相同,那么我们就按照迁移学习的方式从数据集中来弥补数据不足或者标签不足进行训练。
简单来说,联邦迁移学习不对数据切分,是一种基于知识迁移的联邦学习方式。

假设现在有中国某银行的数据集和美国某外卖公司的数据集,因为在不同的国家,所以用户的交叉很少。
因为银行业务和外卖公司业务相差很大,所以用户特征的交叉也很少。
如果用户需要进行有效的联邦建模,就需要借助迁移学习技术,解决单边数据缺乏或者标签少的问题,从而更有效地进行联邦模型训练。
