文章来源《Chat GPT:AI革命》
OpenAI公司的ChatGPT无疑是AIGC界的当红明星,但AIGC产业并不是“一家独大”的局面,而是“百花齐放”的生态。 还有许多技术公司在这个领域进行了多年耕耘,并交出了优秀的答卷。 本章就来介绍一些AIGC工具,它们有的还处于开发或试验阶段,但蕴藏着无穷的潜力,有的则已经投入商用,能够切切实实地提升生产力。 |
01 AI聊天机器人:Bard
Bard是一款基于LaMDA(Language Model for Dialogue Ap plications)模型开发的聊天机器人(见下图)。
它是谷歌为了应对ChatGPT的挑战而推出的对标产品。

下面根据目前已知的信息对比一下ChatGPT和Bard。
ChatGPT已于2022年11月开放公众测试。Bard目前还处于小范围测试阶段,未对公众开放,谷歌只在一场发布会上演示了Bard的功能。 ChatGPT的核心技术是GPT-3模型,Bard的核心技术是LaMDA模型。 这两个模型都是基于Transformer模型发展而来。Transformer模型是谷歌发明的神经网络架构,并于2017年开源。 ChatGPT的训练数据只有截至2021年9月的内容,并且不能通过连网来获取新的数据。 而Bard可以通过谷歌搜索引擎获取新的数据。 这一点也是ChatGPT和Bard之间最大的区别。 |
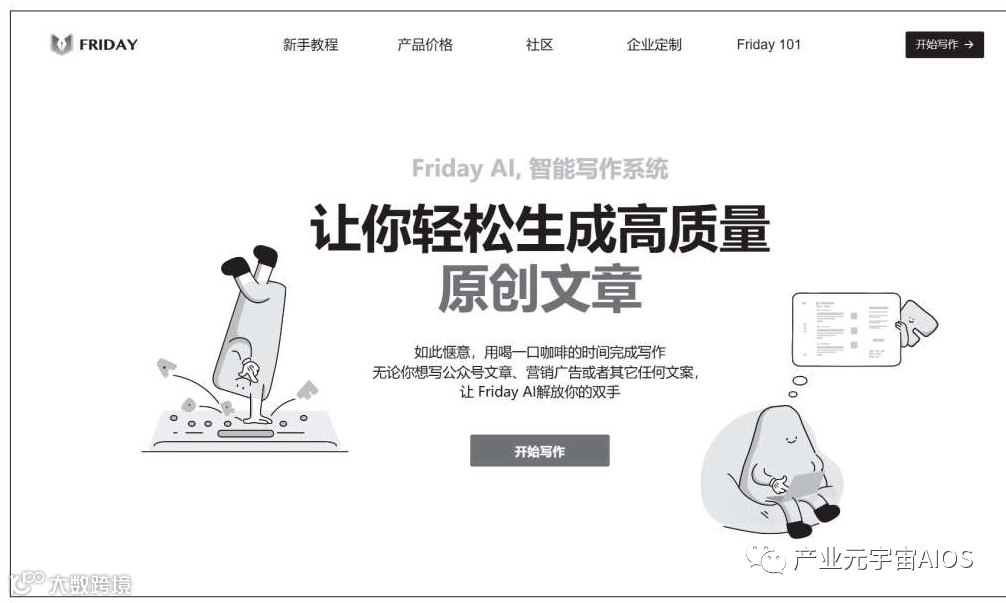
02 智能写作助手:Friday
Friday是一个在线的智能写作助手,其首页(https://www.heyfriday.cn/)如下图所示。
其开发团队的领头人曾是谷歌的NLP科学家(NLP深度学习模型ALBERT的第一作者),团队中还聚集了来自世界各地的NLP资深算法工程师,他们致力于将机器与写作融合,打造具备心智的AI写作助手。
Friday提供了40多个写作模板,包括微信公众号、小红书、电商、短视频、SEO优化等,如下图所示,基本实现了写作需求的全场景覆盖。

选择一种写作模板后,根据需求在页面左侧设置文章标题和关键词,再单击“生成内容”按钮,如下图所示。

即可在页面右侧自动生成文章内容,效果如下图所示。

如果想获得质量更高的文章,则需要支付一定的费用购买会员套餐,如下图所示。

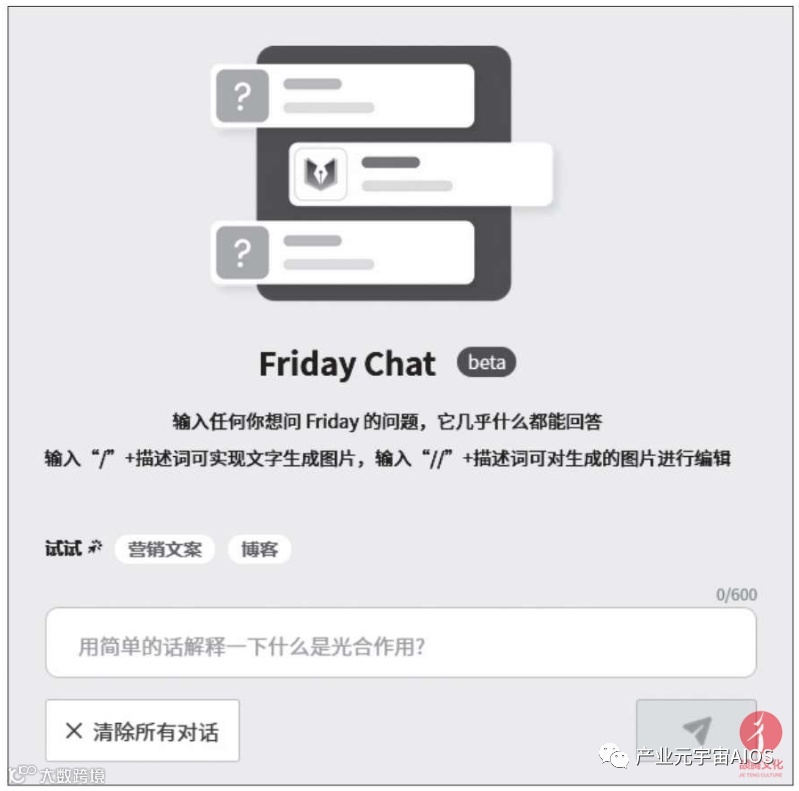
如果想以类似ChatGPT的“一问一答”的方式生成文字或图片,可以使用Friday Chat功能。其界面如下图所示。
03 从文本生成图像:Midjourney
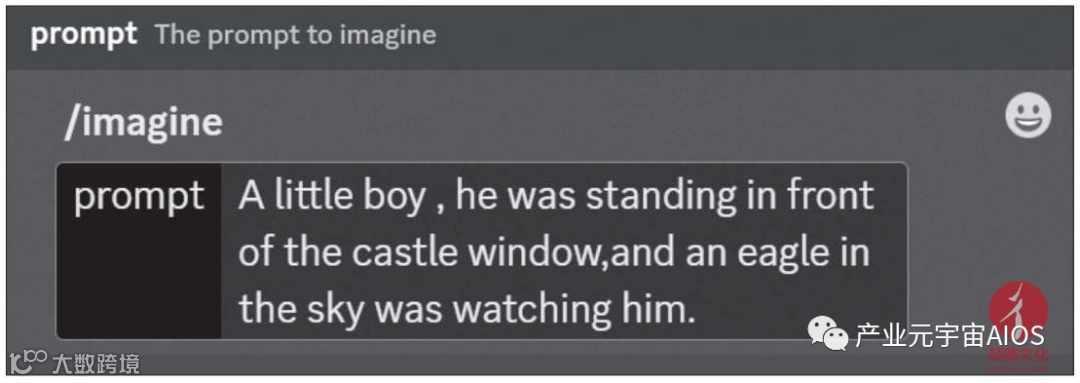
Midjourney归属于Discord(一个聊天室网站),它的基本使用方法就像跟人聊天一样,输入描述文字,然后单击发送按钮,即可生成图片。
在fast(快速)模式下,仅需一分钟的时间,即可根据文字描述生成四种样式的图片。
下面简单演示一下Midjourney的使用效果。
在聊天框中输入需要生成的图片的描述文字,如下图所示。
等待一会儿,在回复中即可看到生成的与文字相关的图片内容,如下图所示。

单击缩略图即可放大显示图片,如下图所示。
可以看出生成的图片不管是美观程度还是精致程度,都是非常惊人的。

以下是一些关于Midjourney的快速问答。
Q:Midjourney生成图片是免费的吗? A:新用户有25次的免费使用额度,用完后需要付费订阅,订阅计划分为3种。 基本计划(10美元/月):每月可以生成200张图片,适合轻度使用者。 标准计划(30美元/月):每月生成的图片数量无限制,每月15小时的fast模式使用时长。 专业计划(60美元/月):每月生成的图片数量无限制,每月30小时的fast模式使用时长。 这3种订阅计划如果按年付款,则可以享受8折优惠,如下图所示。 |

Q:fast模式和relax模式有何区别?
A:在输入框中输入/fast或/relax即可切换至对应的模式,默认为fast模式。
fast模式:不需要排队,发送描述文字到公屏上,即可生成图片。
relax模式:需要在服务器排队,有时快有时慢,排队完成时生成图片。
Q:我不懂英文,能使用Midjourney吗?
A:可以借助百度翻译或谷歌翻译等工具翻译描述文字。
还有一个帮助我们精准描述需求的工具叫Midjourney Prompt Tool,网址为https://prompt.noonshot.com/midjourney。
在这个工具的页面中,我们可以直观地选择需要调整的参数,以“风格”为例,我们可以直观地选择喜欢的某一种图片风格,如下图所示。

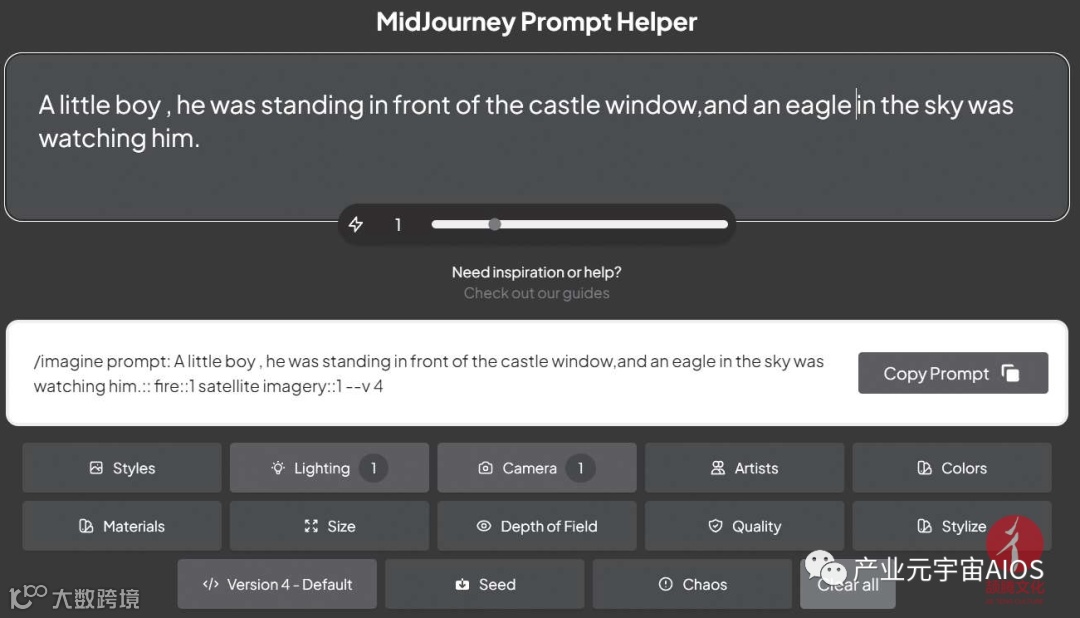
打开这个工具的页面,在顶部的文本框中输入描述文字,然后在下方选择和设置参数,设置好的参数会以代码的形式出现在描述文字之后,如下图所示。
设置完毕后,单击“Copy Prompt”按钮,将带有参数代码的描述文字复制到剪贴板,再粘贴到Midjourney的聊天对话框中,即可生成相应的图片。
生成的图片效果如下图所示。

Q:如何查看自己的历史作品?
A:所有的作品及相应的描述文字全部保存在自己的主页上。
进入Midjourney网站,单击“Sign In”按钮(见下图)进入自己的主页。

在这里可以找到之前创建的所有图片,如下图所示。

Q:用Midjourney生成的图片版权归属于谁?
A:Midjourney官方表示,只要是会员生成的图片,版权归属于创作者。
04 从文本生成图像:造梦日记
造梦日记(https://www.printidea.art/)是国内知名度较高的AI绘画网站,它能根据用户提供的描述文字(中文和英文皆可)和参考图片使用AI算法生成高质量的图片。
造梦日记目前支持网页端和微信小程序,采用“部分免费+付费”的形式提供服务。
在浏览器中打开造梦日记的首页后,单击“开始创作”按钮,如下图所示。

即可进入图像创作页面,在“写下你的创意”文本框中输入描述文字,如下图所示。

然后根据实际需求设定图像风格、输出尺寸、分辨率和生成数量,如下图所示。
最后单击“开始生成”按钮。

生成的图片效果如下图所示。

生成图片需要消耗“造梦星”。
生成图片的数量和质量不同,“造梦星”的消耗个数也不同。
造梦日记会给新注册的用户赠送一定数量的“造梦星”。
“造梦星”使用完毕后可付费购买摘星套餐,如下图所示。

这里补充介绍更多国内外AI绘图平台,如下图所示。


05 从文本生成视频:Imagen Video和Phenaki
在DALL·E 2、Midjourney等文本生成图像模型蓬勃发展的同时,用文本生成视频的AI工具也越来越多。
继Meta的Make-A-Video之后,谷歌也接连发布了两款视频生成模型Imagen Video和Phenaki。
Imagen Video主打视频的质量,而Phenaki则主要挑战视频的长度。
谷歌在其官网中表示,Imagen Video和Phenaki的结合是一项重要突破,它正在努力打造行业领先、能生成高质量影像的工具。
AI驱动的生成模型有着无限的创造力,可帮助人们以前所未有的方式充分表达自身的想法。
下面分别简单介绍一下Imagen Video和Phenaki。据了解,Imagen Video基于级联视频扩散模型来生成高清视频。
输入提示文本后,基本视频扩散模型与多个时间超分辨率模型(Temporal Super-Resolution,TSR)和空间超分辨率模型(Spatial Super-Resolution,SSR)分别以40像素×24像素和3帧/秒的速度生成16帧视频、以1 280像素×768像素和24帧/秒的速度采样,最终得到5.3秒的高质量视频,如下图所示。

而Phenaki则拥有交互生成长视频的能力,可以任意切换视频的整体风格和场景,还能根据200个词左右的提示文本生成2分钟以上的长视频,如下页图所示。
也就是说,在给定一系列提示文本的情况下,Phenaki就能合成逼真的视频,来讲述一个完整的故事。
Phenaki的缺点是视频质量较低。谷歌官网提到,这是首次以时间变量提示生成视频。
此外,研究所提出的视频编码器-解码器在多个方面都优于文献中目前使用的所有每帧基线。

出于安全和伦理的考虑,谷歌暂时不会发布两个视频生成模型的代码或演示程序。
若要体验使用AI生成视频的效果,可以试试清华大学和智源研究院开发的CogVideo,网址为https://huggingface.co/spaces/THUDM/CogVideo。
目前该网站暂时只接受中文文本的输入,且输出视频需要等待较长时间。
06 AI应用工具大集合
随着科技的不断进步,AI的应用范围越来越广。
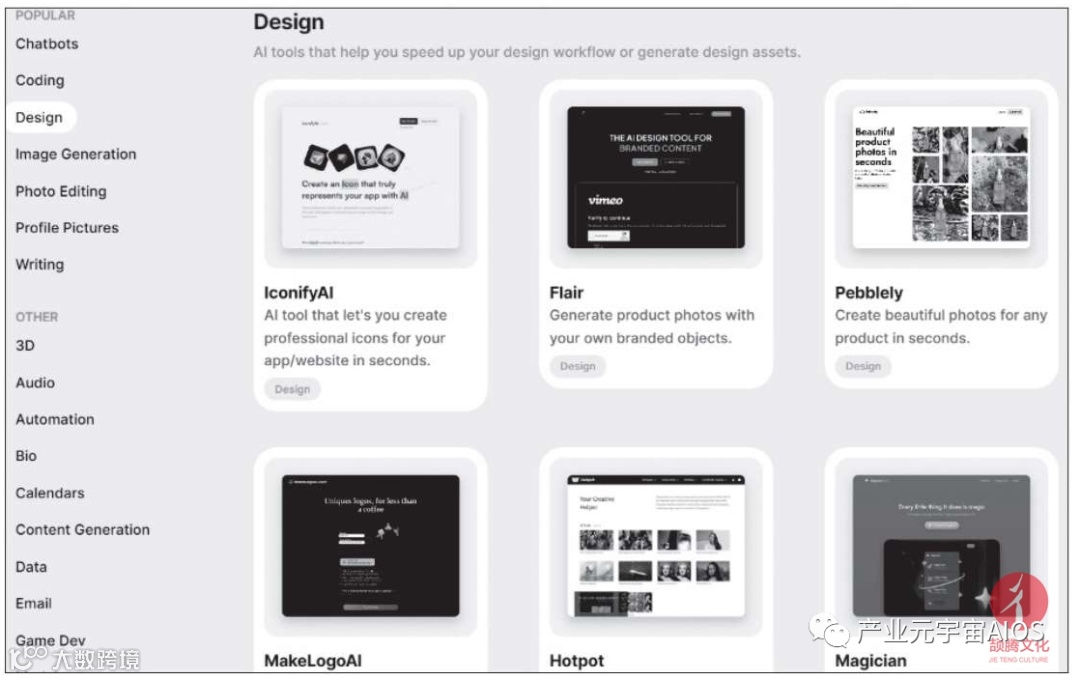
这里介绍一个网站https://allthingsai.com/,网页效果如下图所示。
它搜集整理了很多AI应用的工具和服务,我们可以在这个网站中探索AI技术在各个领域的应用。

例如,选择该网站中的Design标签,则网页中会展示所有与设计相关的AI工具或服务,如下页图所示。
这些工具和服务可以帮助设计师快速生成高质量的设计作品,如平面设计和三维多媒体等;
可以帮助设计师更好地分析用户的需求和行为,更好地根据用户需求定制设计;
可以帮助设计师在大规模设计中更有效率地解决问题,如灵活更新算法、提高搜索速度、提供更准确的结果等。