
文章来源《DAPP开发指南》
零知识证明技术是现代密码学三大基础之一,由格沃斯(S.Goldwasser)、米加里(S.Micali)及拉科夫(C.Rackoff)在20世纪80年代初提出(SHAFI GOLDWASSER, SILVIO MICALI,AND CHARLES RACKOFF, 1989.《The Knowledge Complexity of Interactive Proof System》,下载地址:http://crypto.cs.mcgill.ca/~crepeau/COMP647/2007/TOPIC01/GMR89.pdf)。
早期的零知识证明由于其效率和可用性等限制,未得到很好的利用,仅停留在理论层面。
从2010年开始,零知识证明的理论研究才开始不断突破,同时区块链也为零知识证明创造了大展拳脚的机会,使之走进了大众视野。
零知识证明的英文全称是zero-knowledge proofs,简写为ZKP,是一种有用的密码学方法。
证明过程涉及两个对象:
一个是宣称某一命题为真的示证者(prover),
另一个是确认该命题确实为真的验证者(verifier)。
所谓“零知识”,意味着当证明完成后,验证者除了获得对命题正确与否的答案之外,其他信息一无所知,获得的“知识”为零。
零知识证明是构建信任的重要技术,也是区块链这个有机体中不可缺少的一环。
什么是证明?
最早接触“证明”这个概念,应该是在中学课程中见到的各种相似三角形的证明。
当我们画出一条“神奇”的辅助线之后,证明过程突然变得简单。
其实,证明的发展经历了漫长时间长河的沉淀。
1.古希腊时期:证明=知其然,更知其所以然
数学证明最早源于古希腊。
古希腊人发明了公理与逻辑,他们用证明来说服对方,而不是靠权威。这是彻头彻尾的“去中心化”。
自古希腊以来,这种方法论影响了整个人类文明的进程。
2.20世纪初:证明=符号推理
到了19世纪末,康托、布尔、弗雷格、希尔伯特、罗素、布劳威、哥德尔等人定义了形式化逻辑的符号系统。
而“证明”则是利用形式化逻辑的符号语言编写的推理过程。
逻辑本身靠谱么?
逻辑本身“自洽”吗?
逻辑推理本身对不对,能够证明吗?
这让数学家/逻辑学家/计算机科学家发明了符号系统。
3.20世纪60年代:证明=程序
又过了半个世纪,到20世纪60年代,逻辑学家哈斯卡·咖里(Haskell Curry)和威廉·霍华德(William Howard)相继发现了在“逻辑系统”和“计算系统——Lambda演算”中出现了很多“神奇的对应”,这就是后来被命名的“柯里-霍华德对应”(Curry-Howard Correspondence)。
这个发现使得大家恍然大悟,“编写程序”和“编写证明”实际上在概念上是完全统一的。
在这之后的50年,相关理论与技术的发展使得证明不再停留在草稿纸上,而是可以用程序来表达。
这个同构映射非常有趣:程序的类型对应于证明的定理,循环对应于归纳,在直觉主义框架中,证明就意味着构造算法,构造算法实际上就是在写代码。(反过来也成立)
目前,在计算机科学领域,许多理论的证明已经从纸上的草图变成了代码的形式,比较流行的“证明编程语言”有Coq、Isabelle、Agda等。
采用编程的方式来构造证明,证明的正确性检查可以机械地由程序完成,并且许多重复性的劳动可以由程序来辅助完成。
数学理论证明的大厦正在像计算机软件一样逐步地构建。
1996年12月,麦昆(W.McCune)利用自动定理证明工具EQP证明了一个有63年历史的数学猜想“Ronbins猜想”,《纽约时报》随后发表了一篇题为Computer Math Proof Shows Reasoning Power的文章,再一次探讨机器能否代替人类产生创造性思维的可能性。
利用机器的辅助确实能够有效地帮助数学家的思维抵达更多未知的空间,但是“寻找证明”仍然是最有挑战性的工作。
“验证证明”则必须是一个简单、机械并且有限的工作。
这是一种天然的“不对称性”。
4.20世纪80年代:证明=交互
时间拨到1985年,乔布斯刚刚离开苹果,而格沃斯(S. Goldwasser)博士毕业后来到了MIT,与米加里(S.Micali)、拉科夫(Rackoff)合写了一篇能载入计算机科学史册的经典:《交互式证明系统中的知识复杂性》。
他们对“证明”一词进行了重新的诠释,并提出了交互式证明系统的概念:通过构造两个图灵机进行“交互”而不是“推理”,来证明一个命题在概率上是否成立。
“证明”这个概念再一次被拓展。
交互证明的表现形式是两个(或者多个)图灵机的“对话脚本”,或者称为Transcript。
而这个对话过程中有一个显式的“证明者”角色,还有一个显式的“验证者”角色。
其中,证明者向验证者证明一个命题成立,同时还“不泄露其他任何知识”。
这种证明方式就被称为“零知识证明”。
证明凝结了“知识”,但是证明过程却可以不泄露“知识“,同时这个证明的验证过程仍然保持简单、机械,以及有限。
3.1 抛砖引玉:初识零知识证明
3.1.1 为什么会有零知识证明?
前面已经学习过,在使用私钥/公钥体系时,永远不应该暴露私钥,因为任何获得私钥的第三方都能够解密其获得的每一条加密消息。
下面来考虑一种情况:常规密码在大部分数据库中都存储为哈希(Hash),而不是明文。
这里哈希指一个函数,会把一个输入转换成另一个唯一的字符串数据,从而掩饰或隐藏原始数据。
在哈希函数中,实际上几乎不可能从哈希函数创建的惟一字符串反推出原始数据。
例如,系统可以使用keccak256哈希算法,将密码“HappyLearningZKP”哈希为
0x8d73022c3e12c1c41d5bdbeb0bac5574b814301c5353fc72b135a09ccc764f0f。
看看这种字母和数字的组合,即使知道哈希算法并使用强大的算力,也无法倒推出原始密码“HappyLearningZKP”。
重要的是,哈希函数在定义上是决定性的,这意味着相同的输入总是会得到相同的输出。
因此,如果一个网站将我们的密码存储为:
0x8d73022c3e12c1c41d5bdbeb0bac5574b814301c5353fc72b135a09ccc764f0f,
那么当我们输入“HappyLearningZKP”时,该网站可以通过对其哈希,并与存储在数据库中的哈希值进行比较,来检查我们是否输入了正确的密码。
在上面的情景中,请注意:虽然网站不会存储我们的明文密码,但我们仍然需要通过一个安全通道与网站共享密码,这样才能证明你知道你的正确密码。
如果可以向网站证明我们知道正确的密码,而又不必向它共享或透露该密码,那不是更好吗?
或者再进一步:证明以前的那个你就是现在你说的这个你?
总体来说,这种方法代表了当今大多数行业验证信息的方式——需要提供信息来验证它,需要重新执行计算来验证它是否完整地正确执行。
比如,如果银行想批准一笔从我们的账户到另一账户的电子汇款,银行必须在转账前检查你的账户,来确认你的账户中有足够的钱,以此证明我们不是在花费你实际不拥有的钱。
同样,如果你想证明自己的身份,你必须提供你的社会安全号码或政府签发的其他身份证明。
而在另一些情况下,不需要知道知识的细节就可以检查结果。
例如,供应商甲的出价是否高于供应商乙?
供应商乙不应该看到供应商甲的出价,同样,很可能双方都不想向客户以外的第三方披露自己的出价。
这时,通过零知识证明的方式,监管或审计机构可以得知,供应商甲的出价低于供应商乙。
这就是零知识证明:一方(证明者)能够向另一方(验证者)证明,自己拥有某一条特定的信息,而又无须披露该信息是什么。
3.1.2 简述零知识证明在区块链中的应用
在区块链上,假设存在一个中转地址,记为AddrExchange,所有人都把Token转到这个地址(AddrExchange),然后,再从AddrExchange转出Token。
中转地址被使用之后,有心人就可以通过交易金额等信息,慢慢核对并反推对应关系来找到交易对象。
通过技术手段使得转入的交易记录和转出的交易记录无法一一对应,也就真正实现了交易的匿名。
零知识证明首先在隐藏对应关系的环节就可以起作用。
现在,让我们把整个区块链系统想象成一个大的中转地址,所有人都往这个地址里转Token,所有人都从这个地址里把Token转走。
所有参与交易的人之间不需要合作,转账随时可以进行,不需要等待其他交易。
如果在整个系统中,历史上所有的交易都被混合在一起,交易越频繁,交易数量越多,其匿名性也就越高(逆向复杂度高,时间长)。
那么,零知识证明是怎样实现Token转入和转出的分离,并且同时保持可以被验证呢?
假设:每个人在转入Token的时候,都会生成一个数字(不告诉别人),转账的时候在Token上附带一个用这个数字生成的哈希值Alpha,写入区块链账本系统。
在转出Token的时候,只需要向系统证明:
交易者知道一个数字,这个数字生成的哈希值是Alpha。
大家经过区块链上的共识,确认这个证明有效之后,就允许交易者把Token转走。
因为哈希值Alpha在区块链上,说明转入的Token是确实存在的,而一旦有人知道哈希值Alpha背后的数字,说明其真的是转入Token的交易者。
而零知识证明保证了在交易者整个操作过程中,没有人知道交易者的数字是什么,也就无法伪装成交易者把Token转走。
问题来了,上面的这个证明其实并没有实现转入交易和转出交易的隔离。
因为交易者在转出的时候暴露了哈希值Alpha,其他人通过哈希值Alpha就可以找到转入的那笔交易,从而存在把两笔交易关联起来的可能性。
所以,我们有必要把证明过程再升级一下。
因为系统中所有的转入交易都会附带一个哈希值,成了一个哈希值的列表。交易者的哈希值Alpha也在这个列表中。
如果可以证明:
交易者知道一个数字,这个数字生成的哈希值在系统的哈希值列表中。
那么交易者的哈希值Alpha没有暴露,也就没人能把交易者的转入交易和转出交易关联起来。
上面加粗的两句话,就是零知识证明可以做到的事情。
当然零知识证明不仅仅可以用作匿名交易,为了更好地帮助读者理解和掌握,我们用具体的实例,通过一些适用的场景来进一步探讨零知识证明。
如果对工程实现有兴趣,现有匿名交易的实现主要有三类,使用环签名的比如门罗(Monero),使用零知识证明的Zcash,还有使用Mimblewimble协议的Grin等。
读者也可以思考一下,相对于环签名,零知识证明带来了哪些收益。后续章节我们也会进一步探讨以太坊的运用。
3.2 零知识证明使用场景案例
3.2.1 场景一:万圣节糖果
故事是这样的:一年一度的万圣节到来,小丽和小明分别领取到了一定数量的糖果。
他们想知道他们是否收到了相同数量的糖果,却不想透露糖果的数量,因为他们不想彼此分享。
现在我们假设,他们袋子里可能装有10、20、30个或40个糖果,如图3-1所示。

图3-1 万圣节糖果
这时小明想了个办法,为了比较他们拥有的糖果数量,小明拿到4把钥匙和盒子,盒子上分别写上10、20、30、40,分别对应糖果的数量。
小明最后只保留了自己糖果数量跟盒子数字一样的钥匙,其他3把钥匙就丢弃了(假设小明只保留了写着20的盒子的钥匙)。
然后,小丽在4张纸条上,其中一张写上“+”,另外三张写上“-”。
然后,把写有“+”的纸条放到跟自己糖果数量是相同数字的盒子里,其余纸条放到其他盒子(假设小丽把“+”放到写着30的盒子)。
这时,小明回来后打开他有钥匙的那个盒子(写着20),然后看它是否包含“+”或“-”的纸条。
(1)如果纸条上写着“+”,说明两个人的糖果数量一致。
(2)如果纸条上写着“-”,说明两个人糖果数量不一致,但是并不知道对方糖果的具体数量。
(3)这里小明看到纸条上写着“-”,意味着两人的糖果数量不一样,但是小明无法知道小丽的糖果数量。
这时候,小丽看到小明手上拿着一张写“-”的纸条,那她也知道两人的糖果数量不一样,但是也无法知道对方拥有糖果的确切数量。
上面这个过程,就是一个零知识证明。
ZKP(“零知识证明”的英文缩写)允许我们证明自己在通信的另一“端”知道某个人的某个秘密(或许多秘密),而没有实际透露出秘密。
术语“零知识”源于以下事实:第一方没有透露有关机密的信息(“零”),但是第二方(被称为“验证者”)确信第一方(被称为“证明者”)知道有关机密。
3.2.2 场景二:洞穴
如图3-2所示,R和S之间存在一道密门,并且只有知道咒语的人才能打开它。
小明知道咒语并想向小丽证明,但证明过程中又不想泄露咒语。
他该怎么办呢?
(1)首先两人都走到P,然后小明走到R或者S。
(2)小丽走到Q,然后让小明从洞穴的一边或者另一边出来。
(3)如果小明知道咒语,就能正确地从小丽要求的那一边出来。
小丽重复上述过程很多次,直到她相信小明确实知道打开密门的咒语为止。
在这里,小明是证明方,小丽是验证方。
小明通过上述方法证明了自己确实知道咒语,但是没有跟小丽透露任何咒语的相关信息,这一过程也就是零知识证明。
这个例子似乎让我们想到了什么——《阿里巴巴和四十大盗》。
阿里巴巴不幸遭遇四十大盗,他如果说出藏有财宝的山洞的咒语,他自然也就没命了;
但是,如果他不能证明自己知道山洞的开启咒语,也会没命。
阿里巴巴灵机一动,想出了一个办法,他对强盗们说:“你们必须保持距离我一箭之地,并用弓箭指着我,你们举起右手我就念咒语打开石门,举起左手我就念咒语关上石门,如果我做不到或逃跑,你们就用弓箭射死我”。
这样,阿里巴巴就能在距离大盗足够远的位置,说出咒语打开石门,同时,大盗们也无法获知咒语。
但是大盗们也眼见为实,看到石门的确被打开,验证了阿里巴巴的确掌握咒语。
这个过程阿里巴巴没有直接把咒语透露给大盗们,咒语就是有用的信息。
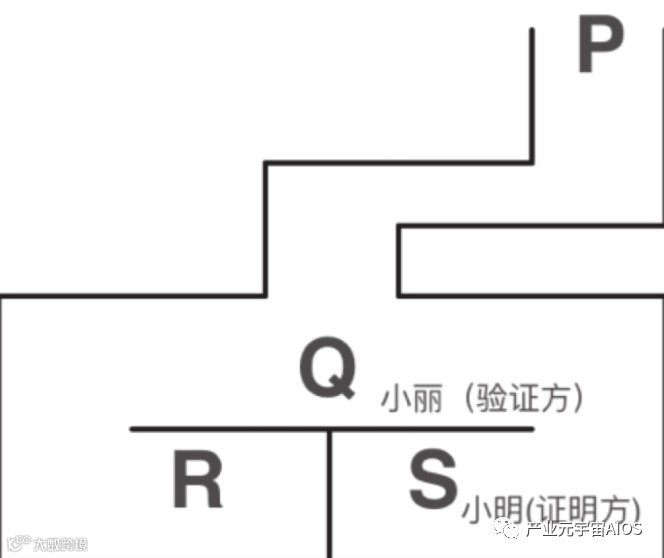
图3-2 洞穴游戏
3.2.3 场景三:数独挑战
我们知道数独是一种逻辑性的数字填充游戏,玩家必须以数字添进每一格,而每行、每列和每个宫(即3×3的大格)有1~9所有数字,且同一个数字在行、列、对角线中皆不重复。游戏设计者会提供一部分数字,使得谜题只有一个答案,如图3-3所示。
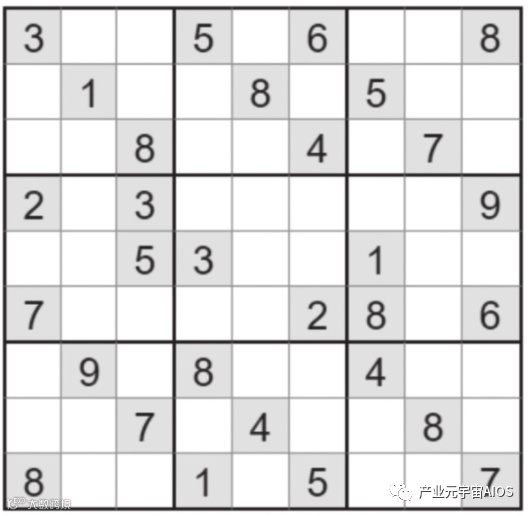
图3-3 数独
小明、小丽、小刚三个好朋友很喜欢玩数独游戏。
他们三个经常互相出题给对方做。
有时候,他们会找来一些非常难的题互相挑战对方。
1.你行你证明
一天,小明想出了一道非常难的数独题,小丽花了很长时间尝试去解开这个数独,但是怎么都解不出结果。
小丽觉得小明在耍她,“这题压根就无解!你做给我看看。”
她跑到小明那里抱怨。
“我能证明给你看这题是有解的,而且我知道这个解。”小明淡定地回答道。
小丽想:“等你证明给我看之后,我就把解记下来然后去找小刚,给他也做一下这题。”
不料,小明却说:“我会用零知识证明的方法给你证明我会这解这道题。也就是说,我不会把解题步骤给你看,却能让你信服我确实会解这道题。”
小丽半信半疑,也好奇这个零知识证明的方法。
2.证明就证明
小明准备了81(9×9)张空白的卡片放在桌上,每张纸上写上1~9中的一个数字,然后让小丽闭上眼睛转过身去,随后把这81张卡片小心翼翼地按照解的排列放在桌上,代表谜底的卡片,有数字的那一面朝下放在桌上;
那些代表谜面的卡片,有数字的那一面则朝上放在桌上。
3.随机抽查验证
如图3-4所示,放置好所有卡片后,小明让小丽转过身,睁开眼。
小明对小丽说:“你不能偷看这些面朝下的卡片。”
小丽很是失望,她原本以为可以看到一个完整的解。
小明说:“我能让你检验这些解,你可以随意选择按照行,或者按照列,或者按照3×3的九宫格来检验我的解。你挑一种吧。”
小丽很困惑,嘴上不住念叨着,然后告诉小明她决定选择按照行的方法来验证,小明接着把每一行的9张卡片收起来单独放到一个麻布袋里。
所有卡片都被收起来放在9个麻布袋里(见图3-4)。
小明接着摇了摇每个麻布袋,把里面的卡片顺序都打散。
最后把这9个麻布袋交给小丽。

图3-4 九宫格与麻布袋
4.不暴露题解的验证方法
“好了,你可以打开这些布袋了,”小明对小丽说,“每个布袋里应该都有正好9张,没有重复数字的,分别是数字1~9的卡片。”
小丽打开每个布袋一看,果真是这样,如图3-5所示。

图3-5 装有卡片的麻布袋
“可是,这证明不了什么吧?我也可以这样做给你看。只要保证每一行都是1~9这9张卡片,不去管纵列和九宫格里的数字是不是也都是没有重复的,不就行了?”
小丽费解地问道。
小明解释说:“可是我事先并不知道你会按照‘行’还是按照‘列’来收集卡片,或者是按照‘九宫格’。我又不是你肚子里的蛔虫……我是按照题解来放置卡片的。”
小丽仔细想了想小明说的话,确实,一个数独只有在有真正正确的解的情况下,才能保证每一行、每一列、每一个九宫格里的数字都是没有重复的1~9。
小明如果真的在骗她,随机抽查至少有1/3的概率可以抓到他在骗人。
5.不信!随机验证多试几次
小丽心里还是有些不服,觉得小明仍然有欺骗她的可能性,所以要求小明再把卡片复原,按照原来的方法,重新选。
这样反复验证了几次,每次都选一个不一样的试验方法。
试了好多次都是一样的结果。
小丽这下不得不承认,小明要么运气非常非常好,每次都能押中小丽会选择哪种试验方式,要么就是他确实知道题的解。
同时也很失望,这么多次试验下来,也还是不知道真正的解,她只知道小明放置卡片的排列里大概率每行、每列、每个九宫格都是没有重复的数字,这就说明这题是大概率有解的,同理得证,小明很可能确实知道数独的解。
小刚在看了这种零知识证明的方法后,三个好友养成了通过零知识证明去证明自己知道数独题的解的习惯。
毕竟每个人在解题的时候都花了很大工夫,不想轻易地把题解直接告诉别人。
虽然每次零知识证明的过程很花时间,但是他们的成就感得到了满足。
6.席卷全球的数独风暴
通过互联网,小明和小丽发现了全世界更多的数独爱好者,他俩决定开一个直播间,直播解数独。
为了展现自己的聪明才智,每周开播前,小明在粉丝团里随机抽取一个粉丝递交的数独,直播时,小明会把题解告诉小丽,然后由小丽用零知识证明的方法向观看直播的人们证明这题有解,并且自己知道题解。
7.作弊风波
这一天,小明和小丽准备直播一个非常难的数独,可是小明发现他把解出的答案落在自己家了。
时间紧迫,要重新算一遍指定赶不上开播的时间。
但是他和小丽还是决定开播。
开播前,小明和小丽说:“咱俩假装弄一弄零知识证明,我告诉你一会儿我会怎么选试验方式。
你只要确保每次我选的那种试验方式(每行、每列或每个九宫格)里的数字不要重复就行。”
小丽同意了。
事后,小明和小丽把他俩这次作假的方法告诉了小刚,小刚很失望地斥责他俩:“你们这样做和作弊有什么区别?对得起支持你们的人吗?我再也不相信你们俩的零知识证明了!”
8.非交互式证明(Non-interactive Proofs)
小刚很不爽。
他很享受之前和小明、小丽一起挑战数独的乐趣,但是,现在的他觉得无法信任小明和小丽。
小刚想找到另一种方法来保证直播中的小明和小丽不能再这样作假。
冥思苦想之后,小刚告诉小明、小丽,他终于想到了一个好方法。
小刚把自己关在屋里忙活了一整天,第二天他把小明、小丽叫来,给他们展示自己的新发明:
零知识数独非交互式证明机——“The Zero-Knowledge Sudoku Non-Interactive Proof Machine”(zk-SNIPM)。
这台机器基本上就是把小明和小丽之前做的那套证明自动化,不再需要人为交互。
小明只要把卡片放在传送带上,机器会自动选择按行、列或九宫格来收取卡片,放到袋子里打乱顺序,然后把袋子通过传送带再送出来。
然后小明就可以当着镜头的面拆开袋子展示里面的卡片。
这台机器有一个控制面板,打开里面是一串旋钮,这些旋钮用来指示每次试验的选择(行——Rows、列——Columns、九宫格——Blocks),如图3-6所示。
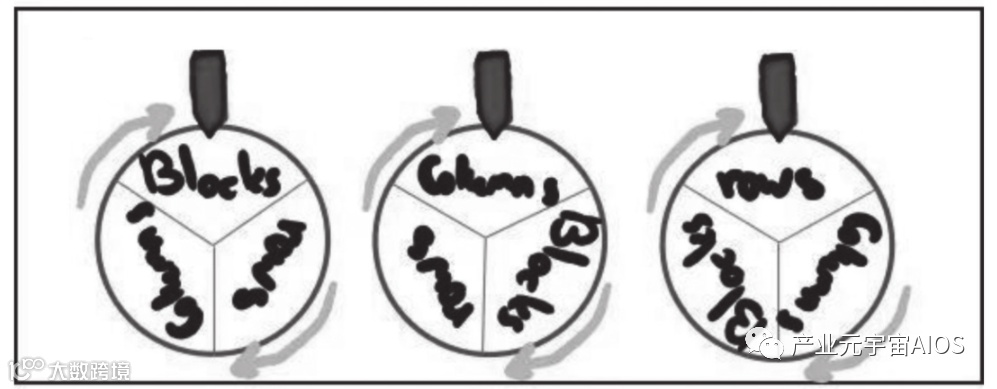
图3-6 非交互式机器
小刚已经设置好了试验的序列,然后把控制面板焊死,以保证小明和小丽不会知道他到底选择了哪一个试验序列。
小刚可以完全信任自己这台机器,他放心地把机器交给小明和小丽,让他俩下次直播就直接用这台机器来证明。
9.魔法盒子的开启仪式
小明和小丽很羡慕小刚有这台机器,并且想也能用这台机器来验证小刚自己出的数独题。
问题来了,小刚如果知道自己选了什么样的试验序列,那么,用这台机器去验证小刚自己的数独题解,小刚就可以作弊。
怎么解决这个问题呢?
其实也挺简单的,只要把大伙聚集起来,共同把控制面板重新打开,然后由大家一起来设置控制面板上的试验序列即可。
这个过程可以称之为“可信任的初始设置仪式”(Trusted Setup Ceremony)。
为了增加随机性和保密性,如果把这台机器放在一个漆黑的房间里,并且把旋钮上的指示贴纸也都撕去。
三人分别进入到这个屋子,大家进房间时蒙上眼睛来减少作弊的可能性。
这样,最后这些旋钮所代表的试验序列他们三个人基本上就都没有办法知道。
即便他们三个人中有两个人事先商量好自己会怎么选,他们也无法得知第三个人会怎么选,从而没有办法作假。
等仪式结束之后,他们一起把控制面板焊死,这样至少比原来的可信度增加了不少。
10.如何破解魔法盒子?
有那么一天,小明在家守着这台机器。他开始反思它是不是像大家认为的那样安全可靠。
过了一会儿,他开始尝试给机器故意传送一些假的题解(只保证每行、每列或每个九宫格的数字不重复),试图通过这种试错来找出机器里设置的试验序列。
慢慢反复尝试,终于把机器里的试验序列都推断出来了。
他既兴奋又沮丧,如何能设计一个更好的证明机呢?
11.故事的本质
看到这里,相信读者又巩固了对零知识证明的基本认知:
零知识证明的本质,就是在不暴露我所知道或拥有的某样东西的前提下,向别人证明我有很大概率(零知识证明说到底是一个概率上的证明)确实知道或拥有这个东西。
故事里要证明的,就是一个数独题的题解,小明让小丽每次随机抽取行、列、九宫格的卡片,并收集在一起随机打乱,小丽通过拆开袋子并不能知道题的解,但是却能相信小明很大概率知道题的解。
本场景中的zk-SNIPM也是暗指零知识证明现在最普遍的zk-SNARKs(Zero-Knowledge Succinct Non-Interactive Argument of Knowledge)算法。
zk-SNIPM还有改进的余地,比如用一台扫描仪把第一次卡片的组合就全扫描下来,然后一次性同时验证所有的试验序列。
这样就很难用试错的方式来破解机器。
小明和小丽最开始的那种互动式证明方法暗指的是交互式零知识证明(interactive zero-knowledge proof)。
交互式零知识证明需要验证方(小丽)在证明方(小明)放好答案(commitment)后,不断发送随机试验。
如果验证和证明双方事先串通好,那么他们就可以在不知道真实答案的情况下作弊(simulate/forge a proof)。
非交互式证明则不需要这种互动,但会额外需要一些机器或者程序,并且需要一串试验序列,这个试验序列不能被任何人知道。
有了这么一个程序和试验序列,证明机就能自动算出一个证明,并且能防止任何一方作假。
这里需要再升级一下,通过同态加密的方法,把采样点隐藏起来,把加密后的点写入区块链,一样可以完成验证,同时还不暴露采样点。
这样就形成了最终的zk-SNARKs。
zk-SNARKs目前也存在很多已知的问题,比如:第一步从函数到代数表达式再到多项式的转换过于复杂,实际操作起来难度太高。
采样点的生成仍然需要依赖一个可信的操作方。
这个操作方知道采样点,可以伪造任何证明(这也是Zcash引入Trusted Setup的原因)。
这个设置的过程需要在系统初始化的时候完成。
如果在以太坊上,我们部署了一个新的函数,就没法通过链上的方法完成这个安全的初始化,这也间接限制了其应用。
而技术的问题最终总会被技术升级所解决。
零知识证明为区块链带来保护隐私的特性,有可能带来区块链的下一个爆发点。
Zcash是在2016年10月28日推出的一种新的加密货币。
它是一个比特币的克隆,来自比特币代码库0.11的分叉,Zcash通过增加完全匿名交易的附加功能与比特币、以太坊区分开来。
因此,Zcash被誉为“不可跟踪的”加密学货币。
Zcash为了实现匿名交易,采用了零知识证明的密码学和计算机科学分支技术。
即使是这个世界上最聪明的数学家也将零知识证明描述为“月球数学”,全球只有少数专门的研究人员对零知识证明运作细节有完全的了解。
零知识证明通过在公共Zcash区块链上创建匿名交易来实现Zcash的“不可跟踪”。
Zcash上加密的交易隐藏了发件人和收件人的地址,以及一个地址发送给另一个地址的价值。
这是独一无二的,因为迄今为止,其他区块链会显示从一个地址到另一个地址的价值传输,并且区块链上的任何人都可以看到此交易的值。
与其他区块链不同,Zcash用户可以完全隐藏交易,唯一公开的是在某个时间点发生了某件事。
发送Zcash的地址都是匿名的,这意味着如果你不知道他们的实际身份或真实世界的地址,则无法看到货币从哪里流入或流出。
3.2.4 场景四:一个“真实世界中”的案例
某电信业巨头打算部署新一代的5G电信网络。
这个网络的结构如图3-7所示。图中的每个顶点代表一个无线电塔,每一条连线(边)代表无线电塔信号两两重叠的区域,这意味着连线上的信号会互相干扰。

图3-7 重叠无线电塔结构图
这种重叠的情况是有问题的,这表示来自相邻电塔的信号会互相混淆。
幸好在设计之初预见了这个问题,现在通信网络允许传递三种波段的信号,这样就避免了临近电塔信号干涉的问题。
不过现在我们有了新的挑战!这个挑战来自我该如何部署不同的波段,使得任意相邻的两个电塔不具有相同波段。
我们现在用不同颜色来表示不同波段,可以很快找到一种解决方案,如图3-8所示。

图3-8 相邻电塔用不同波段来规避重叠
到目前为止,这个难题就是著名的算法问题——三色问题(graph three-coloring)。
这个问题有趣的地方在于:某些非常庞大的网络中,我们很难找到解,甚至连证明问题有解都办不到。
如果只是上面给的这种示例图,我们用人工计算就能轻松找出题的解。
但是,如果无线通信网路规模特别复杂而庞大,动用企业常规所有能调配的计算资源都无法找到解答的情况下,该怎么处理呢?
假设某个乙方公司动用了大量的算力来寻找有效的着色方法。
必然,在电信公司在得到确实有效着色方法之前,并不打算付钱给乙方。
同样,对于乙方来说,在电信公司付款之前,也不愿意给出着色方法的真正副本。因此双方就会陷入僵局。
谷歌工程师向在麻省理工学院的米加里(Micali)等人进行了咨询,同时想出了一种非常聪明而优雅,甚至不需要任何计算机的方法来打破上述的僵局。
只需要一个大仓库、大量的蜡笔和纸张,以及一堆帽子。
首先,电信公司先进入仓库,在地板上铺满纸张,并在空白的纸上画出电塔图。接下来离开仓库,换谷歌工程师进入仓库。
谷歌工程师先从一大堆的蜡笔中,随机选定三个颜色(与上面的例子一样,假设随机选中红色/蓝色/紫色),并在纸上照着自己的解决方案上色。
请注意,用哪种颜色上色并不重要,只要上色的方案是有效的就行!
谷歌工程师们上色结束后,在离开仓库前,会先用帽子把每张纸上的电塔盖住。
所以当电信公司回到仓库的时候,会看到如图3-9所示的界面。

图3-9 谷歌对着色方法进行保密
显然的,这种方法保障了谷歌着色方法的秘密性。
但是如何证明进行了有效的着色呢?
谷歌工程师们决定给我机会“挑战”他们的着色方案。
电信公司被允许——随机选择图上的一条边(两个相邻帽子中间的一条线),然后要求谷歌工程师揭开两边覆盖着的帽子,让我看到他们着色方案中的一小部分,如图3-10所示。
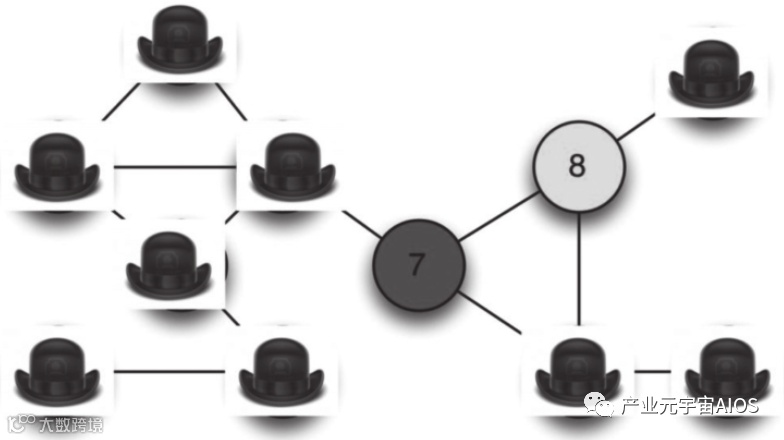
图3-10 局部检验去重性
这样做,会产生两种结果:
(1)如果两个点颜色相同(或是根本没有被着色!),则表明谷歌工程师们对我撒谎。
(2)如果两个点颜色不同,那么谷歌工程师可能没有撒谎。
即使我刚才进行了一轮观察,毕竟我只揭开两顶帽子,只看到两个点,仍然不能保证谷歌工程师所给的方法是有效的。
假如图上有E条不同边,在目前条件下谷歌仍有很大的可能是给了一个无效的着色方案。
实际上,在经过一次揭帽观察后,仍有高达(E-1)/E的概率会被骗(假如有1 000条边,有99.9%的概率这个方案无效)。
那就再一次、重新进行观察!再次走出仓库,让他们重新铺上新的纸张,并把空白的电塔图画上。
谷歌工程师再次从大量蜡笔中随机选出三种颜色进行着色。
再次完成有效着色方案,但使用新的三种随机颜色。接着又盖上帽子。
电信公司走进仓库再一次进行“挑战”,选择一条新的、随机的边。
上述逻辑再一次适用。
如此持续反复n次,那么如果谷歌工程师作弊,他必须连续n次都这么幸运。
这当然有可能发生——但发生的可能性相对较低。
现在谷歌工程师连续两次都骗到我的概率为[(E-1)/E] * [(E-1)/E](在1 000条边的情况下,大约有99.8%的可能性,还是很高)。
电信公司被骗的概率总会存在,即使概率很小。但经过大量的迭代后,最终可以将信心提升到一个程度,那时候谷歌工程师只剩下微不足道的概率可能骗到我——这概率低到我可以安全地把钱交给谷歌工程师。
在这个过程中,谷歌工程师同样受到保护。
即使电信公司试图在挑战的过程中推敲出正确的着色方案,那也不要紧。
因为谷歌工程师在每一次迭代前随机更换三种新的颜色,这让电信公司获得的讯息毫无帮助,每次挑战的结果也无法被串联起来。
1.是什么让它“零知识”的
最难说明的就是“零知识性”。为此,必须进行一项非常奇怪的思想试验。从一个假设开始。
假如谷歌工程师花了数周时间,仍然没有想出着色问题的解决办法。
现在只剩下12小时就得展示了,绝望使人疯狂,他们决定诱导电信公司相信他们已经完成有效的着色,而实际上并没有完成。
怎么办呢?
他们潜入Google X研究室,并“借用”谷歌时光机的原型机。
最初想将时间倒退几年,这样可以获得更多时间来解决问题。
不幸的是,这台原型机有限制——只能倒退四分半钟的时间。
虽然使用时光机获得更多工作时间的想法已经不可行,但这有限的功能已经足够完成欺骗。
因为谷歌工程师们实际上不知道正确的着色方案,只能直接从大量蜡笔中随机选出颜色来涂,然后盖上帽子。
如果足够幸运,电信公司在挑战时选中不同颜色点,他们就可以松口气然后继续进行挑战,以此类推。
万一某次挑战揭开两顶帽子时,发现两个相同颜色的点!
他们就用时光机挽回颓势——让时间倒退四分半钟,然后再以新的完全随机方式着色。接着时间正常前进,挑战将继续进行。
时光机让谷歌工程师可以挽回在欺骗过程中的任何失误,同时让电信公司误以为这个挑战过程完全符合规则。
从谷歌工程师的角度来看,造假被发现的情况只有1/3,所以整个挑战时间只会比诚实情况下(即知道有效解答)的挑战时间稍微长一点;
从电信公司的角度来看,会认为这是完全公平的挑战,因为电信公司并不知道时光机的存在,所以看到的每一次挑战结果,都会认定这就是真实的!而统计结果也完全一致。
(在时光机作弊的情境下,谷歌工程师们绝对不知道正确着色方案。)
2.这到底说明了什么
请注意,上例其实是一个计算机仿真的例子。
在现实世界中,时间当然不能倒退,也没有人能用时光机器骗我,所以基于帽子的挑战协议是合理且可靠的。
这表示在E^2轮挑战后,电信公司应该相信盖着的图是被正确着色的,同时谷歌工程师们也遵守协议规则。
如果时间不只能够前进——特别的是谷歌能“倒退”我的时间,那即使他们没有正确的着色方案,他们仍然能使挑战正常进行。
从电信公司的角度出发,这两种情况有什么区别?
考虑从这两种情况下的统计分布,会发现根本没有区别,两者都表达了相同量级的有效信息。
这恰好证明了下面这件非常重要的事情。假设电信公司(验证者)在正常挑战协议过程中,有办法“提取”关于谷歌正确着色方案的相关信息。
那么当电信公司被时光机愚弄的时候,验证者的“提取”策略应该仍然有效。
但从验证者的角度来看,协议运行结果在统计学上毫无二致,验证者根本无法区别。
因此,如果验证者在“公平的挑战”和“时光机实验”下,所能得到的信息量相同,且谷歌在“时光机实验”中投入的信息量为零,则证明即使在公平的挑战下,也不会透露任何相关信息给验证者知道。
3.抛开帽子和时光机
在现实世界中一般不会想使用帽子来验证协议,谷歌(可能)也没有真正意义上的时光机。
为了将整件事情串起来,我们先把这个协议放到数字世界。
这需要我们构建一个相当于“帽子”功能的等价物——它既能隐藏数字价值,又能同时“绑定”(或“承诺”)创建者,这使得事实被公布后他也不能不认账。
幸运的是,我们恰好有这种完美的工具。这就是所谓的数字承诺方案。
这个方案允许一方在保密的情况下“承诺”给出的信息,然后再“公开”承诺的信息。
这种承诺可以有很多结构组成,包含(强)加密哈希函数。
我们现在有了承诺方案,也就有一切电子化运行零知识证明的要素。
首先证明者可以将每个点以数字信息形式“着色”(例如以数字0,1,2…),然后为每个数字信息生成数字承诺。
这些数字承诺会发送给验证者,当验证者进行挑战的时候,证明者只需要展示对应两个点的承诺值就行。
所以,我们已经设法消除帽子了,但如何证明这个过程是零知识的?
我们现在身处数字世界,不再需要一台时光机证明与此相关的事。
其中的关键在于数字世界中,零知识证明协议不是在两个人之间运行,而是在两方不同的计算机程序上运行(或者更规范地说,是概率图灵机)。
现在可以证明下面的定理:如果你能做出一套程序,使得验证者(计算机)能够在挑战过程中”提取“额外的有用信息,则我们就有办法在程序中加入“时光机”的功能,使得它能够在证明者没有投入任何信息的情况下(注:即谷歌工程师没有正确解),从“假”的挑战过程获得等量的额外信息。
因为现在讨论的是计算机程序,回退、回滚等倒退时间的操作根本不是难事。
实际上,我们在日常使用上就不断在回滚程序,比如带有快照功能的虚拟机软件。
即使没有复杂的虚拟机软件,任何计算机程序也都可以回滚到先前状态。
我们只需要重新启动程序,并提供完全相同的输入即可。
只要输入的所有参数(包含随机数)都是相同的,程序将永远按照相同的执行路径操作。
这意味着我们可以从头开始运行程序,并在需要的时间点进行“分叉”(forking)。
最终我们得到以下定理:如果存在任何的验证者计算机程序,它可以通过与证明者的协议交互过程中提取信息,那么证明者计算机同样可以通过程序回滚来“欺骗”验证者——即证明者无法通过挑战,却以回滚的方式作弊。
我们已经在上面给出了相同的逻辑:如果验证者程序能从真实的协议中提取信息,那么它也应该能从模拟的、会回滚的协议中获取等量的信息。
又因为模拟的协议根本没有放入有效信息,因此没有可提取的信息。
所以验证者计算机能提取的信息一定始终为零。
4.我们到底知道了什么
根据上面的分析,我们可以知道这个协议是完整且可靠的。
该论点的可靠性在我们知道没有人玩弄时间的前提下都是站得住脚的。
也就是说,只要验证者计算机正常运行,并且保证没有人在进行回滚作弊的话,协议是完整且可靠的。
同时我们也证明这种协议是零知识的。
我们已经证明了任何能成功提取信息的验证者程序,也一定能从回滚的协议运行中提取信息,而后者是没有信息放入的。
这明显自相矛盾,间接论证该协议在任何情况下都不会泄露信息。这一切有个重要的好处。
比如,在谷歌工程师向我证明他们有正确的着色方案后,我也无法将这个证明过程转传给其他人(如法官)用以证明同样的事,这使得伪造协议证明变成了不可能的事。
因为法官也不能保证我们的视频是真是假,不能保证我们没有使用时光机不断回滚修改证明。所以零知识证明只有在我们自己参与的情况下才有意义,同时我们可以确定这是实时发生的。
5.证明所有的NP完全问题
我们讲了半天的三色电信网络,其实并不有趣——真正有意思的地方在于,三色问题属于NP完全问题。
简单来说,这件事的奇妙之处在于任何其他的NP问题都可以转化为这个问题的实例。
在一次不经意的尝试下,格雷奇(Goldreich)、米加里(Micali)和威德森(Wigderson)发现“有效的”零知识证明大量存在于这类问题的表述中。
其中的许多问题比分配网格问题有趣得多。
你只需要在NP问题中找到想要证明的论述,比如上面的哈希函数示例,然后转化为三色问题,然后再进行数字版的帽子协议就行啦!
单纯为了兴趣来运行这项协议,对任何人来说都是疯狂的——因为这样做的成本包含原始状态和证人的规模大小、转化为图形的花费,以及理论上我们必须运行E^2次才能说服某人这是有效的。
所以我们迄今展示的,是要表达这种证明是“可能的”。
我们仍然需要找到更多的实例来支撑零知识证明的可用性,还好,区块链的世界里不乏这样的例子。
3.3 零知识证明的应用发展
让我们先从以太坊的应用进展说起。
要想成功解决公链的可扩展性问题,不仅仅要做到提高交易吞吐量。
区块链世界里所谓的可扩展性,就是系统要能够在满足数百万用户的需求的同时,不以去中心化为代价。
而加密货币能大规模普及的前提条件是速度快、费用低、用户体验流畅,并且能保护隐私。在没有技术突破的情况下,现有的可扩展性解决方案不得不在一个或多个条件上做出重大妥协。
幸运的是,零知识证明技术的最新进展为我们带来了更多新的解决方案。
Matter Labs团队宣告了ZK Sync的愿景:基于ZK Rollup的免信任型可扩展性和隐私性解决方案,旨在带来绝佳的用户和开发者体验。ZK Sync的开发者测试网络也已经上线。
ZK Sync旨在将以太坊上的吞吐量提高到像VISA那样,每秒可达几千笔交易,同时又能确保资金像存储在底层账户那样安全,并维持较高水平的抗审查性。
该协议的另一个重要方面,是延迟性极低:
ZK Sync上的交易具有即时经济确定性。
项目遵行精益设计理念,并支持以循序渐进的方式推进协议,按顺序逐一引入各个功能,让每个步骤都能为用户带来最实际的价值。
从最基础的部分(安全性)开始,首先聚焦于基础可扩展性(代币转移),然后是可编程性(智能合约),最后是隐私性。
ZK Sync特性一览:
·严格持平于L1的安全性
·VISA级别的吞吐量
·亚秒级交易确认速度
·抗审查,抗DDoS攻击
·隐私保护型智能合约
3.3.1 区块链扩容的挑战
在没有得到真正的普及之前,互联网货币、DeFi、Web 3.0等区块链概念的价值主张在很大程度上都无法实现。
可扩展性指的不仅仅是交易吞吐量,还有区块链系统是否能够满足数百万用户的需求。
我们来看一看将区块链推向大众所面临的三大挑战。
3.3.1.1 挑战一:保持去中心化的信任基石
要想在现实生活中推广区块链,目前去中心化程度最高的区块链在交易处理量上比现有的交易技术还差了一个数量级。
比特币网络每秒能处理几笔交易,以太坊网络每秒能处理几十笔交易——而VISA平均每秒能处理两千多笔交易。
但是,对于比特币和以太坊而言,低效是一种特色,而非缺陷!
只要减少验证者的数量,就能轻而易举地加快交易处理速度。
作为两大顶尖区块链网络,比特币和以太坊上大量的全节点是它们最重要的资产。
因此,这就为区块链带来了强韧性,从根本上将其与现有金融机构区别开来。
另一个热门的扩容方案就是,要求每个验证者只验证一部分相关的区块链流量,而非全部流量。
但这难免会引入另外的信任假设,系统所依据的博弈论基础也会变得极为脆弱。
3.3.1.2 挑战二:实现真正的隐私性
现实世界中,绝大多数人都不会愿意自己转移财富的交易往来公之于众。
毕竟这是隐私数据。
在某些动荡地区,如果暴露自己拥有多少财产的话,就不可能愿意用加密货币来完成支付。
再比如,如果付款时有可能暴露自己的真实身份,生产或消费成人内容的人就不可能使用加密货币来代替其他支付方式,如支付宝、微信支付等。
此外,链上交易在不具备保密性的情况下,《通用数据保护条例》(GDPR)和《2018年加州消费者隐私法案》(CCPA)之类的隐私条例,会促使普通企业从公链转向更加中心化的支付和金融中心,这会让我们这个日益无现金化的社会变回成电影里演绎的《楚门的世界》或者《少数派报告》。
谁想要财务隐私?
财务隐私合法使用案例的范围很广。
事实上,财务隐私对于世界上发生的大多数交易来说可能是需要的。
例如:
·一家公司不想让竞争对手知道自己的供应链信息。
·明星不想被公众知道自己正在支付向破产律师或离婚律师咨询的费用。
·一个家庭因为害怕被歧视,希望对雇主和保险公司隐瞒他们的孩子有慢性病症或遗传问题的事实。
·一个富有的人不希望犯罪分子了解他的行踪以及试图勒索他的财富。
·交易柜台或不同商品的买卖双方之间的其他中间商公司希望避免交易被切断。
·银行、对冲基金和其他类型的交易金融工具(证券、债券、衍生工具)的金融实体;
如果其他人可以弄清楚它们的仓位或兴趣所在,那么此信息会使此交易者处于劣势,影响它们顺利交易的能力。
隐私性是普及区块链的必备条件。
但是在公链上很难实现隐私性,原因有如下三个方面。
(1)隐私性必须是协议的默认配置。
引用以太坊创始人Vitalik Buterin的话来说,“如果隐私模型的匿名集是中等大小,实际上就只有很小。
如果隐私模型的匿名集很小,实际上就约等于没有。
只有全球化的匿名集才是真正强健可靠的”。
(2)要让隐蔽交易成为大家的默认选择(普及),隐蔽交易的交易费用必然要保持非常低,但是在技术上,隐蔽交易必将带来高昂的计算成本。
(3)隐私模型必须具有可编程性,因为现实世界的用例不仅仅局限于转账,还需要账户恢复、多签和消费限额等。
3.3.1.3 挑战三:达到符合预期的用户体验
现实世界的产品竞争是激烈、残酷的。
产品经理都很愿意迁就用户来进行产品体验、交互的设计。
用户越来越喜欢轻松、轻量的用户体验,享受即刻带来的满足感,却会无意之间忽略了长尾风险。
要想驱动用户从熟悉的事物切换到新事物,这需要非常强大的驱动力,无论是利益驱动还是结果驱动。
对于一些人来说,加密货币的价值主张(彻底的自主产权、抗审查性和健全货币)就已经有足够的吸引力。
但是这些先行者或者极客很可能已经入场了。
加密货币若要实现当初的承诺,其用户群体的规模就算不用数十亿,也要有数百万才行。
如果要吸引数百万主流用户,需要为他们提供符合乃至超出期望的用户体验。
也就是说,必须持续不断地提供全新的功能,还要尊重保留人们已经习惯的、传统互联网产品的所有便利属性,即“快速、简单、直观且具有容错性”。
3.3.2 ZK Sync的承诺:免信任、保密、快速
下面从技术角度,让我们来看看ZK Sync的架构、设计原则以及协议的良好特性。
1安全性:扎根于ZK Rollup
ZK Sync是基于ZK Rollup的概念搭建的。简而言之,ZK Rollup是一种二层(Layer 2)扩展方案,所有的资金都存储在主链上的智能合约内,计算和存储则在链下执行。
每创建一个新的Rollup区块,就会生成一个状态转换的零知识证明(SNARK),并提交给主链上的合约进行验证。
这个SNARK包含了对Rollup区块中所有交易有效性的证明。
此外,每个区块的公开数据更新,都会作为便宜的calldata发布到主链上。该架构提供了以下保证:
(1)Rollup验证者永远不能破坏状态或窃取资金(注意,这里不同于侧链)。
(2)即使验证者不配合,用户也可以追回Rollup上的资金,因为Rollup具备数据可用性(注意,这里不同于Plasma)。
(3)得益于有效性证明,无论是最终用户,还是可信的第三方,都不需要通过在线监视Rollup区块来防止诈骗(注意,这里不同于使用错误性证明的系统,例如支付通道或optimistic rollup)。
综上所述,ZK Rollup严格继承了底层链的安全保障。
正是有了这种安全保障,再加上丰富的以太坊社区和现有的基础设施,以太坊才决定专注于二层解决方案,而不是试图搭建自己的底层链。
感兴趣的读者可以去继续了解ZK Rollup和Optimistic Rollup之间的区别,会更有收获。
Matter Labs在过去的一年以来都在研究ZK Rollup技术。
自首个原型发布以来,团队已经全部重写了架构和ZK的电路。
最新的版本融合了从社区获得的反馈,并实现了各种可用性和性能改进。
简单概括一下,ZK Rollup实现的安全性体现在如下几点:
·完全的免信任性
·具备与底层链(以太坊)同样的安全保障
·第一次确认之后,就具有由以太坊背书的确定性
2.可用性:实时交易
尽管大家乐观相信,但是仍然还需要证明的是:ZK证明技术的最新发展成果将缩短证明时间,将ZK Rollup区块的出块时间控制在一分钟之内。
一旦区块证明被提交到主链,并在Rollup智能合约中验证通过,这个区块内的所有交易都会得到最终确定,并且受到Layer-1抵御链重组的能力保护。
尽管如此,就零售和线上支付领域而言,以太坊上15秒的区块延迟也有些不可接受,如何才能够做得更好呢?
所以,大家打算在ZK Sync中引入即时交易收据(instant tx receipts)。
简单来说,那些选择参加ZK Sync区块生产的验证者,必须向主网上的ZK Sync智能合约提交一笔可观的安全保证金。
由验证者达成的共识会为用户提供亚秒级确认,确保其交易包含在下一个ZK Sync区块内,并由绝大多数(2/3以上)的共识参与方签署(按权益加权)。
如果一个新的ZK Sync区块被创建出来并提交到主链上,它是无法被撤回的。
但是,如果这个区块不包含已承诺的交易,则签署过原始收据和新区块的验证者,其安全保证金会被罚没。
这部分验证者所质押的保证金必定超过总金额的1/3以上。
也就是说,惩罚会覆盖1/3乃至以上的安全保证金,而且只有恶意验证者会遭受惩罚。
被罚没的金额中有一部分会用来补偿交易接收者,剩下的会被销毁。
罚没机制既可由用户自己触发,也可由任意签署过原始交易收据的诚实共识参与方触发。
后者天生就有触发罚没机制的动机:如果他们参加下一轮区块生产,可能也会遭到惩罚。
因此,共识参与者中只要有一个是诚实的就足以检测欺诈。
再细说一遍:ZK Sync设计了一种零确认的交易模式,也就是让一笔交易附带一个即时交易数据,该收据会指向一个尚未发布到链上的ZK Sync区块。
在区块证明发布到主链之前,只有短短几分钟的时间可以对ZK Sync上的零确认交易发起双花攻击。
此外,恶意验证者要想诱使用户相信自己的交易已成为零确认交易,得做好1/6的安全准备金被罚没的打算。
从买卖双方的角度来看,零确认交易是:
(1)即时的;
(2)存在逆转的可能性,不过只在短短的几分钟之内;
(3)只有在同时而非逐个对上千个卖方发起攻击的情况下才可逆。
相比信用卡支付,ZK Sync在用户体验和安全性上有很大提升!
现在让我们站在不同参与者的角度来看:
·出售实物商品的线上商店会立即向用户确认订单,但是不会遭受攻击,因为卖家会等到完全确认之后再发货。
·实体店在交易量较少之时是几乎不可能遭受攻击的。
即使你是以即时收据的形式来出售一台Macbook,也要有数千名协调一致的攻击者在不同的地点发起攻击,还要依靠大多数验证者串谋才能成功。
说得再深入一些。
为了量化风险,我们可以将保证金提供的经济保证与PoW区块链提供的结算保证进行比较。
举例来说,经过35个交易确认之后,Coinbase才会接收一笔以太坊资金存款。
如果是通过亚马逊云服务租用GPU来发起51%攻击的话,要持续攻击10分钟才能撤回这个交易,成本大约在6万美元。
假设安全保证金高达数百万美元,撤回一个即时ZK Sync收据所需的成本会高得多。
因此,这些即时收据的经济确定性相比以太坊有过之而无不及。
要注意的是,即时交易数据不会受到ETH区块重组的影响,因为这些收据的有效性与以太坊无关。
此外,以太坊的结算保证与ZK Sync的结算保证是结合在一起的。
3.总结:实时交易
·亚秒级交易确认的经济确定性堪比以太坊。
·几分钟之后就具有由以太坊背书的确定性。3.3.2.1 活性:抗审查性和抗DoS攻击
扩展方案必然具备的一个属性是,大多数用户都无法参与所有交易的验证。
因此,所有二层扩展方案都需要专门设置一个角色(Plasma和Rollup上的验证者、Lightning hub,等等)。
这类角色对于安全性和性能的要求较高,带来了中心化和审查的风险。
为了解决这一问题,ZK Sync在设计上引入了两种不同的角色:验证者和守护者。
1.验证者(Validitor)
验证者负责将交易打包到区块内,并为这些区块生成零知识证明。
他们要参与共识机制,必须缴纳一笔安全保证金,才能创建即时交易收据。
验证者节点必须在网络带宽良好的安全环境中运行。
或者,他们也有可能按自己心意在不安全的云平台上生成零知识证明。
验证者将获得交易费作为奖励,是用被交易代币来支付的(为终端用户提供最大程度的便利)。
为了快速达成ZK Sync共识,验证者的人数是有限制的(根据我们的分析,30~100人比较合适)。
但是别忘了,ZK Rollup验证者是完全免信任的。
在ZK Sync上,恶意验证者既不能破坏系统的安全性,也不能欺骗诚实的验证者触发罚没机制。
因此,不同于optimistic rollup,系统的守护者(Guardian)可以频繁更换一小部分验证者。
与此同时,只要有2/3的提名验证者是诚实且可进行操作的,就能确保满足活性要求(liveness)。
2.守护者(Guardian)
大部分通过质押代币份额来提名验证者的ZK Sync持币者会成为守护者。
守护者的目的是监控点对点交易流量,探测审查行为,并确保不会提名那些有审查行为的验证者。
为了保护自己的质押物不被罚没,守护者必须确保ZK Sync可以抵御DoS攻击,不会实施审查。
虽然投票密钥通常来说都是在线保存的,但是这不会给ZK Sync上的守护者带来罚没或盗窃的风险(所有权密钥是冷存储的)。
守护者就可以选择只监控一小部分流量。
因此,守护者节点可以运行在普通的手提电脑或云服务器上,也就是说,不需要提供专门的验证者服务。
守护者会获得验证者的费用作为奖励,是以ZK Sync原生代币的形式发放的。
其收益和押金会被锁定较长一段时间,以此促进ZK Sync代币的长期升值。
3.总结:活性
·两种角色:验证者和守护者都受到交易费的激励。
·由验证者运行共识机制并生成证明。
·由运行在普通硬件上的守护者防止审查。
3.3.3 RedShift:透明的通用SNARK
要实现基于零知识证明的智能合约(无论是透明的还是保护隐私的),最大的障碍就是缺乏一种通过递归组合实现的高效且通用的零知识证明系统(efficient generic ZK proof systems with recursive composition)。
Groth16曾是最高效的ZK SNARK,但它需要为每一个应用专门启动一套受信任的初始化设置,而且在采用递归方式时会很低效。
另一方面,基于FRI的SNARK需要高度专业化的构建技能,而且缺乏针对任意通用电路的高效递归组合。
这也是开发RedShift的主要动机之一:
从基于FRI协议的多项式承诺方案(polynomial commitment scheme)中衍生出一个透明、高效且简洁的新型SNARK。
RedShift目前正在进行同行评议和社区反馈,之后会将RedShift作为一个核心部分部署在ZK Sync上。
Redshift是一种通用的SNARK,能让我们将任意程序转换为可证明的ZK电路。
异构电路(如不同的智能合约)可以通过递归的方式在一个SNARK中构成。
RedShift仅依赖于抗碰撞的哈希函数,因此可被认为具有后量子安全性。
总结:Redshift
·透明的:不需要可信的设置。
·可被认为具有后量子安全性:基于久经考验的密码学。
·通用的:适用于通用程序(这点与STARK相反)。
3.4 libsnark开源实践简介
libsnark是目前实现zk-SNARKs电路最重要的框架,在众多私密交易或隐私计算相关项目间广泛应用,其中最著名当然要数Zcash。
Zcash在Sapling版本升级前一直使用libsnark来实现电路(之后才替换为bellman)。
毫不夸张地说,libsnark支撑并促进了zk-SNARKs技术的首次大规模应用,填补了零知识证明技术从最新理论到工程实现间的空缺。
libsnark是用于开发zk-SNARKs应用的C++代码库,由SCIPR Lab开发并维护。
libsnark工程实现背后的理论基础是近年来(尤其是2013年以来)零知识证明特别是zk-SNARKs方向的一系列重要论文。
从Github上可以看到这个项目的主要开发者,如:·马达斯·维嘉(Madars Virza)·霍华德·吴(Howard Wu)·伊兰·特鲁莫(Eran Tromer)他们大多都是这个领域内顶尖的学者或研究牛人。
扎实的理论基础和工程能力,让libsnark的作者们能够化繁为简,将论文中的高深理论和复杂公式逐一实现,高度工程化地抽象出简洁的接口供广大开发者方便地调用。
libsnark的模块总览如图3-11所示,摘自libsnark代码贡献量第一作者马达斯·维嘉在MIT的博士论文。

图3-11 libsnark的模块总览图
libsnark框架提供了多个通用证明系统的实现,其中使用较多的是BCTV14a和Groth16。
查看libsnark/libsnark/zk_proof_systems路径,就能发现libsnark对各种证明系统的具体实现,并且均按不同类别进行了分类,还附上了实现依照的具体论文。
其中,zk_proof_systems/ppzksnark/r1cs_ppzksnark对应的是BCTV14a,zk_proof_systems/ppzksnark/r1cs_gg_ppzksnark对应的是Groth16。
ppzksnark是指preprocessing zkSNARK。
这里的pp/preprocessing其实就是指我们常说的trusted setup,即在证明生成和验证之前,需要通过一个生成算法来创建相关的公共参数(proving key和verification key)。
我们也把这个提前生成的参数称为“公共参考串“(Common Reference String),或简称为CRS。
基本原理与步骤
使用libsnark库进行开发zk-SNARKs应用,从原理上可简要概括为主要4个步骤:
(1)将待证明的命题表达为R1CS(Rank One Constraint System);
(2)使用生成算法(G)为该命题生成公共参数;
(3)使用证明算法(P)生成R1CS可满足性的证明;
(4)使用验证算法(V)来验证证明。
R1CS是一种表示计算的方法,使其能够满足零知识证明。
基本上任何计算都可以简化(或平铺)为一个R1CS。
例如向量w上的一个秩为1的约束被定义为

第一步:我们需要将函数C(x, out)在libsnark中进行表达。
此处先省略,后面介绍详细过程。
第二步:对应下面的Generator函数G,lambda为随机产生,也就是常说的trusted setup过程中产生的“toxic waste”。
人们喜欢称它为“有毒废物”,是因为它必须被妥善处理(如必须销毁,不能让任何人知道),否则会影响证明协议安全。

最终生成proving key(pk)和verification key(vk)。
第三步:对应使用Prove函数(P)生成证明。
这里想证明的是prover知道一个秘密值x和计算结果out 可使等式满足。
因此将x、out还有pk 作为输入一起传给P,最终生成证明proof。

第四步:对应使用Verify函数(V)验证证明,将proof、out还有vk 传给G,即可在不暴露秘密的情况下证明存在一个秘密值可使等式满足。

而开发者主要工作量就集中在第一步,需要按照libsnark的接口规则手写C++电路代码来描述命题,由代码构造R1CS约束。
整个过程也就对应图3-12的计算(Computation)→算法电路(Arithmetic Circuit)→R1CS。

图3-12 电路代码过程图
具体的例子,可参见如下两个项目:
·https://github.com/howardwu/libsnark-tutorial
·https://github.com/christianlundkvist/libsnark-tutorial根据霍华德·吴(libsnark作者之一)的libsnark_tutorial,run_r1cs_gg_ppzksnark()是主要部分。
很容易发现,真正起作用的实质代码只有下面5行。

我们从“超长”的函数名上能直观地看出每一步是在做什么,但是却看不到如何构造电路的细节。
实际上这里仅仅是调用了自带的r1cs_example,隐去了实现细节。下面通过一个更直观的例子来学习电路细节。
研究src/test.cpp,这个例子改编自克里斯汀·伦德伟(Christian Lundkvist)的libsnark-tutorial。
代码开头仅引用了三个头文件:

前面提到r1cs_gg_ppzksnark对应的是Groth16方案。
这里加了gg是为了区别r1cs_ppzksnark(也就是BCTV14a方案),表示Generic Group Model(通用群模型)。
Groth16安全性证明依赖Generic Group Model,以更强的安全假设换得了更好的性能和更短的证明。
第一个头文件是为了引入default_r1cs_gg_ppzksnark_pp类型,第二个则为了引入证明相关的各个接口。
pb_variable 则是用来定义电路相关的变量。
下面需要进行一些初始化工作,定义使用的有限域,并初始化曲线参数。
这相当于准备工作。

接下来就需要明确“待证命题“是什么。
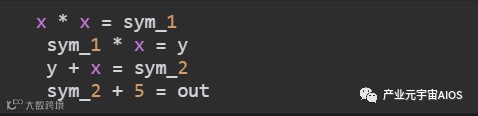
这里不妨沿用之前的例子,证明秘密x满足等式x3 + x + 5 == out。
这实际也是维塔利(Vitalik)博客文章 Quadratic Arithmetic Programs: from Zero to Hero中用的例子。
如果对下面的变化陌生,可尝试阅读该文章。通过引入中间变量sym_1、y、sym_2将x3 + x + 5 = out扁平化为若干个二次方程式,几个只涉及简单乘法或加法的式子,对应到算术电路中就是乘法门和加法门。
你可以很容易地在纸上画出对应的电路。
通常文章到这里便会顺着介绍如何按照R1CS的形式编排上面几个等式,并一步步推导出具体对应的向量。
这对理解如何把Gate转换为R1CS有帮助,然而却不是本书的核心目的。
所以此处省略这些内容。
下面定义与命题相关的变量。
首先创建的protoboard是libsnark中的一个重要概念,顾名思义就是“原型板”或者“面包板”,用来快速搭建电路,在zk-SNARKs电路中则是用来关联所有变量、组件和约束。
接下来的代码定义了所有需要外部输入的变量以及中间变量。

下面将各个变量与protoboard连接,相当于把各个元器件插到“面包板”上。
allocate()函数的第二个string类型变量仅是用来方便DEBUG时的注释,方便DEBUG时查看日志。

注意,此处第一个与pb连接的是out变量。
我们知道zk-SNARKs中有public input和private witness的概念,分别对应libsnark中的primary和auxiliary变量。
那么如何在代码中进行区分呢?
我们需要借助set_input_sizes(n)来声明与protoboard连接的public/primary变量的个数n。
在这里n = 1,表明与pb连接的前n = 1个变量属性是public,其余变量的属性都是private。
至此,所有变量都已经顺利与protoboard相连,下面需要确定的是这些变量间的约束关系。
这个也很好理解,类似元器件插至面包板后,需要根据电路需求确定它们之间的关系再连线焊接。
如下调用protoboard的add_r1cs_constraint()函数,为pb添加形如a * b = c的r1cs_constraint,即r1cs_constraint(a, b, c)中参数应该满足a * b = c。
根据注释,不难理解每个等式和约束之间的关系。

至此,变量间的约束添加完成,针对命题的电路构建完毕。
下面进入前文提到的“4个步骤”中的第二步:使用生成算法(G)为该命题生成公共参数(pk和vk),即trusted setup。
生成出来的proving key和verification key分别可以通过keypair.pk和keypair.vk获得。

进入第三步,生成证明。
先为public input以及witness提供具体数值。
不难发现,x = 3, out = 35是原始方程的一个解,则依次为x、out以及各个中间变量赋值。
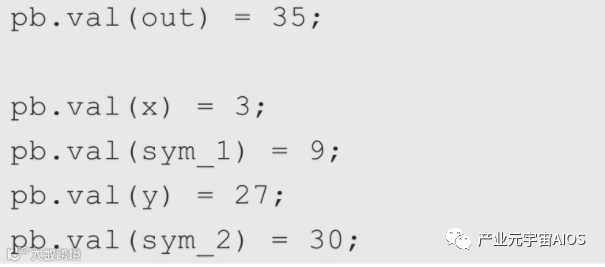
再把public input以及witness的数值传给prover函数进行证明,可分别通过pb.primary_input()和pb.auxiliary_input()访问。
生成的证明用proof变量保存。

最后我们使用verifier函数校验证明。
如果verified = true则说明证明验证成功。

从日志输出中可以看出验证结果为true,R1CS约束数量为4,public input和private input数量分别为1和4。
日志输出符合预期。

实际应用中,trusted setup、prove、verify会由不同角色分别开展,最终实现的效果就是prover给verifier一段简短的proof和public input,verifier可以自行校验某命题是否成立。
对于前面的例子,就是能在不知道方程的解x具体是多少的情况下,验证prover知道一个秘密的x可以使得x3 + x + 5 = out成立。
通过上面短短的几十行代码,就已经使用了zk-SNARKs。
使用它进行实战,我们可以参见安比实验室的开源代码示例:https://github.com/secbit/libsnark_abc。
3.5 术语介绍
·SP——Span Program,采用多项式形式实现计算的验证。
·QSP——Quadratic Span Program,QSP问题,基于布尔电路的NP问题的证明和验证。
·QAP——Quadratic Arithmetic Program,QAP问题,基于算术电路的NP问题的证明和验证,相对于QSP,QAP有更好的普适性。
·PCP——Probabilistically Checkable Proof,在QSP和QAP理论之前,学术界主要通过PCP理论实现计算验证。
PCP是一种基于交互的、随机抽查的计算验证系统。
·NIZK——Non-Interactive Zero-Knowledge,统称“无交互零知识验证系统”。
NIZK需要满足三个条件:
〇完备性(Completeness),对于正确的解,肯定存在相应证明。
〇可靠性(Soundness),对于错误的解,能通过验证的概率极低。
〇零知识(Zero Knowledge)。
·SNARG——Succinct Non-interactive ARGuments,简洁的、无须交互的证明过程。
·SNARK——Succinct Non-interactive ARgumentss of Knowledge,相比SNARG,SNARK多了Knowledge,也就是说,SNARK不光能证明计算过程,还能确认证明者“拥有”计算需要的Knowledge(只要证明者能给出证明就说明证明者拥有相应的解)。
·zkSNARK——zero-knowledge SNARK,在SNARK的基础上,证明和验证双方除了能验证计算外,验证者对其他信息一无所知。
·Statement——对于QSP/QAP和电路结构本身(计算函数)相关的参数。
比如说,某个计算电路的输入/输出以及电路内部门信息。
Statement对证明者和验证者都是公开的。
·Witness——Witness只有证明者知道,可以理解成某个计算电路的正确的解(输入)。