
真实世界对象遵循生物分类层级结构,如蓝锥嘴雀从动物界至种级可分为脊索动物门、鸟纲、雀形目、唐纳雀科、锥嘴雀属、蓝锥嘴雀七层。当前多模态大模型通常仅能识别顶层类别(如“鸟”),难以实现全层级精准识别。
分层视觉识别旨在预测完整的类别序列,而非仅限于最终细粒度类别。现有生成式模型(如FineDINO)虽在细粒度识别上表现优异,但因缺乏类别树知识,无法逐层精准定位。判别式大模型(如BioCLIP系列)的表征空间已充分编码层级关系。北京大学彭宇新教授团队提出分类感知表征对齐方法(Taxonomy-Aware Representation Alignment, TARA),通过将判别模型知识迁移至生成模型,为类别树学习提供新路径。相关论文已被CVPR 2026接收,代码已开源。

背景
现有多模态大模型在依赖类别树的分层视觉识别任务上面临三大挑战:
同层判别性差
粗粒度层级“类内差异大”使模型难抓取关键共性;细粒度层级“类间差异小”导致相似类别混淆,无法逐层准确区分。
跨层一致性差
模型缺乏层级知识,难以保证相邻预测满足父子关系。例如,错误预测“鹦鹉目-裸鼻雀科”,实则裸鼻雀科应属“雀形目”。
新类泛化性差
现有方法过度关注子类差异,忽视共性提炼,导致新类别(尤其是稀有物种)识别能力薄弱。

△ 图1. 研究背景
TARA通过两个关键对齐机制注入类别树知识:利用生物基础模型(如BioCLIP)表征指导生成式大模型,使其提取具备完整层级结构的视觉特征,并适配指定粒度输出。
实验表明,该方法不仅提升最终细粒度识别准确率,更显著增强全层级分层识别性能。
技术方案
TARA包含以下两个核心模块:
分层视觉表征对齐
通过将多模态大模型中间层视觉特征与生物基础模型目标特征对齐,促使其学习完整类别树结构。给定图像I与层级识别问题q,生物基础模型视觉编码器生成目标特征𝐲img=εv(I),对齐损失为:
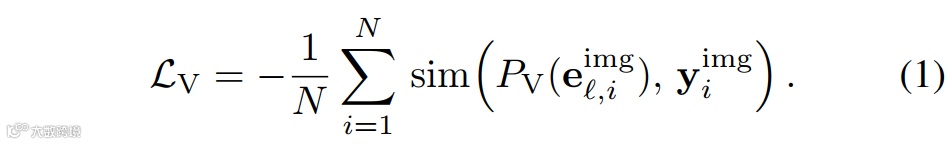
自由粒度类别表征对齐
根据用户指定的识别层次(如“纲”或“种”),将大模型输出的首词元表征与生物基础模型文本特征对齐。目标文本特征𝐲label=ET(C),对齐损失为:
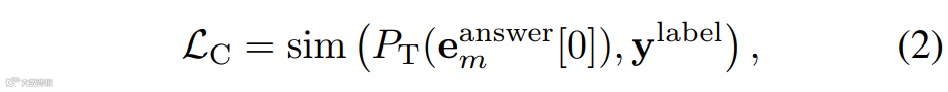
总对齐损失取上述均值:

训练阶段采用无需思考强化微调(No Thinking RFT)与TARA交替优化;推理阶段仅调用优化后的大模型。

△ 图2. TARA框架图
实验结果
iNaturalist-Plant与iNaturalist-Animal实验表明,TARA可同步提升细粒度及全层级识别准确率:
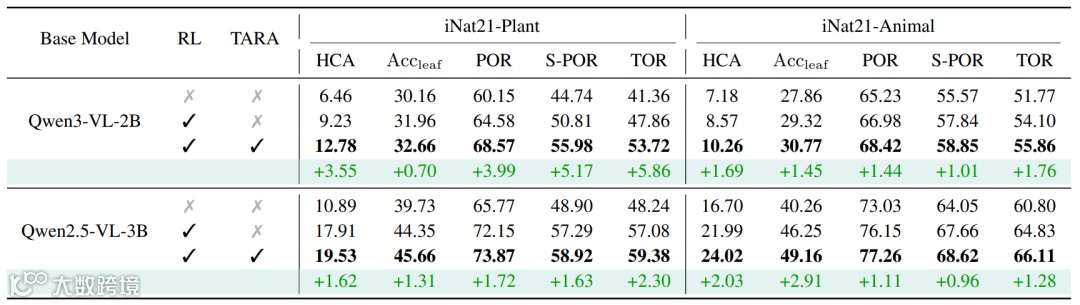
△ 表1. 分层视觉识别结果
在TerraIncognita新类别数据集上,TARA针对稀有物种(科学界可能未正式描述)的高层级分类(如“目”“科”)表现突出。由于新类别完全未见于预训练及微调数据,该方法通过类别树先验学习子类共性,有效提升新类泛化能力:

△ 表2. 新类别分层识别结果
案例对比显示,相较于Qwen3-VL-2B等基线模型,TARA显著提升同层区分能力与跨层一致性:

△ 图3. 案例效果对比
项目价值
TARA通过表征对齐机制注入类别树知识,不仅增强最终细粒度识别能力,更实现从粗到细分层识别能力的系统性提升,对生物多样性监测、生态研究等场景具有重要应用价值。
论文标题:Taxonomy-Aware Representation Alignment for Hierarchical Visual Recognition with Large Multimodal Models
论文链接:
https://arxiv.org/abs/2603.00431
开源代码:
https://github.com/PKU-ICST-MIPL/TARA_CVPR2026
实验室网址: