
大家好,我是兰心!
先说个扎心的事。
2026年3月,腾讯云混元系列模型价格暴涨463.13%,OpenAI把GPT-5.4的价格也翻了一倍不止。智谱AI的GLM-5系列两个月内连续涨价,最高涨幅超过80%。
你以为这是个案?不,这是趋势。
数据显示,2025年中中国日均Token消耗突破30万亿,到2026年2月已经飙升到180万亿。半年翻了6倍,这是什么速度?比房价涨得还快。
为什么?因为"龙虾"火了。

OpenClaw这种能干活的AI智能体,一个月内Token消耗量翻了4倍以上。一个配置合理的"龙虾",每天要向模型发起数百次调用,每次调用都带着完整上下文,消耗的Token量是传统聊天用户的几十倍甚至上百倍。
德国有家科技杂志测试OpenClaw,一天就花了100多美元。这谁扛得住?
所以问题来了:你还在给云厂商送钱吗?
本地部署,才是正道
数据不上云,隐私绝对安全。
别扯什么云端安全,你的机密数据都在别人的服务器上跑,这就是在裸奔。2025年某医疗AI企业因为云端API泄露患者病历,被罚了2300万。你觉得你的数据不值钱?
等你被竞争对手拿到核心数据,就知道疼了。
长期成本直接砍半。
我算过一笔账,一个月API调用费超过300美元,不如直接买台Mac Mini。高频使用场景下,本地部署三年能省30%-70%。这不是省小钱,这是省大钱。
响应速度秒杀云端。
工厂质检AI从云端800ms延迟降到本地15ms,瑕疵检测率直接提升40%。毫秒级响应和秒级响应,这就是质变。
GLM-4.7-Flash:封神的轻量模型
2026年1月,智谱发布了GLM-4.7-Flash,直接封神。
30B总参数量,激活参数量仅3B,这是什么概念?就是一个大型专业团队处理任务时,只调用精锐小分队攻坚。
性能呢?在SWE-bench编程测试中,它以59.2%的准确率远超同级模型——比阿里Qwen3-30B的34%高出25.2个百分点,较GPT-OSS-20B的22%更是翻倍领先。
推理速度提升40%,能耗降低35%,甚至能在配置达标的手机上流畅运行。这就是技术突破。
最关键的是什么?中文适配性拉满。
GLM-4.7-Flash在前端开发场景中,对React、Vue、Tailwind CSS等技术栈支持度极高,响应式布局、交互动画、暗黑模式切换等需求的代码生成准确率达89%。
后端任务更是拿手好戏,适配Spring Boot、Flask、Django等主流框架,对Swagger、MyBatis-Plus等国内常用工具适配性远超海外模型。
OpenClaw:能干活的智能体
OpenClaw不是聊天机器人,是实干家。
它能读写本地文件、执行代码、操控命令行,还能联网搜索、访问网页分析内容。大脑可以接入Qwen、OpenAI等云端API,或者用本地GPU跑模型。
我让OpenClaw帮我:
-
整理上周的会议纪要,自动生成行动项 -
监控服务器日志,发现异常自动报警 -
分析销售数据,生成可视化报表
这些任务以前需要三个人工,现在一个AI全搞定。
ClawHub官方技能平台有数千款Skills,覆盖30多个领域。办公协作、内容创作、开发工具、智能家居,应有尽有。
三步部署,小白也能搞定
别以为本地部署很难,2026年的工具已经简化到零代码基础也能玩转。
第一步:安装1Panel
1Panel是轻量级服务器管理面板,能一键实现环境搭建和工具管理。
前往1Panel官方开源仓库,根据自己的电脑系统下载对应安装包。双击安装包,按照引导完成安装,全程默认下一步即可。
安装完成后,打开1Panel面板,完成简单的账号注册,进入主界面备用。
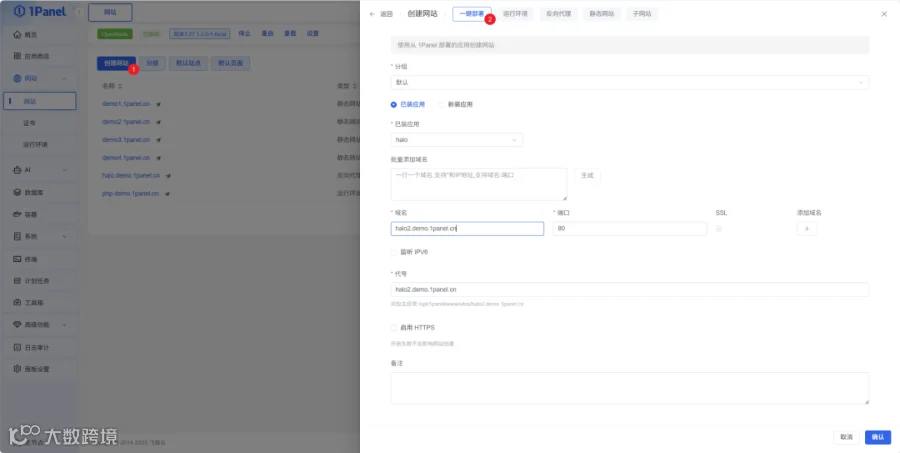
第二步:部署Ollama
Ollama是专为大模型设计的轻量运行工具,能一键拉取、运行GLM-4.7-Flash模型。
在1Panel主界面找到应用商店,搜索Ollama,点击一键安装。安装完成后,在我的应用中启动Ollama服务。
打开电脑命令行工具,输入简单指令拉取GLM-4.7-Flash模型,等待模型下载完成。模型体积轻量,下载速度快。
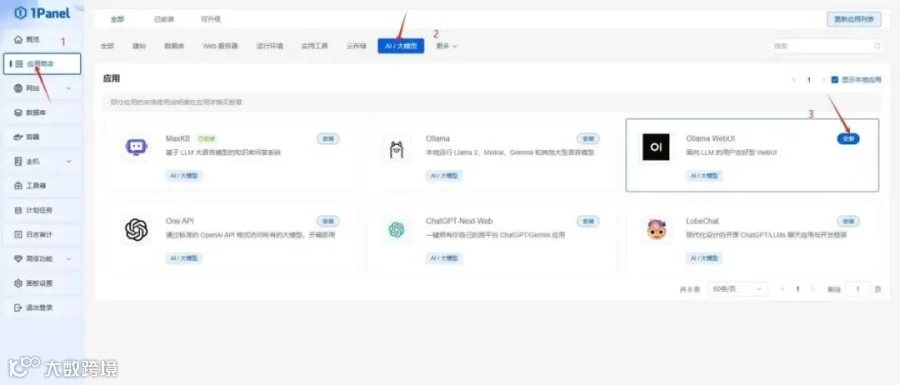
第三步:配置OpenClaw
同样在1Panel应用商店搜索OpenClaw,点击一键安装并启动。
启动后,在OpenClaw设置界面,选择模型对接,关联已下载的GLM-4.7-Flash模型。
按需安装所需Skills,如文件整理、Web搜索、文档解析等,完成后即可开始使用。
就这么简单,5分钟搞定。
硬件要求?低到离谱
很多人觉得本地部署需要RTX 4090,其实2026年已经不一样了。
硬件要求现在低得离谱:
-
CPU:Intel i3 4代或AMD Ryzen 3 2000+ -
内存:最低2GiB(建议4GiB) -
存储:40GiB SSD就行
我试过在2018年的旧笔记本上部署OpenClaw v2026.2.15,五分钟搞定。旧电脑也能"诈尸"。
能做什么?比你想象的多
部署完成后,实测体验拉满。
文件整理 :上传本地文件夹,AI可按类型、名称、日期自动分类整理,解放双手。
Web搜索 :无需打开浏览器,直接让AI在线搜索信息,快速整合答案。
文档处理 :支持Word、Excel、PDF等多种格式文档解析、总结、改写,提升办公效率。
多场景对话 :基于GLM-4.7-Flash的中文优势,日常聊天、知识问答、文案创作都能轻松应对。
所有操作均在本地完成,响应速度极快,而且全程零Token费用,再也不用精打细算AI调用次数。
避坑指南:别掉进这三个坑
我踩过的坑,希望你不用再踩。
坑一:安全漏洞
开源智能体存在信任边界模糊的问题。可能被指令诱导、配置缺陷或被恶意接管,执行越权操作。
避坑方案:生产环境必须配置严格权限,定期安全审计。别把管理员权限随便给AI。
坑二:模型幻觉
本地模型在专业领域幻觉率能达到17%-33%。我让本地AI分析法律合同,结果它自己编了几条法律条文。
避坑方案:关键决策必须人工复核。本地AI适合执行任务,不适合做最终决策。
坑三:隐性成本
硬件投入只是开始。电力、散热、运维人力都是钱。
避坑方案:先试点核心场景,再逐步扩容。别一次性投入太多。
未来已来,你跟上了吗?
2026年的趋势很明确——混合架构。
日常轻量任务用本地小模型保安全,复杂高阶任务调用云端大模型保质量。
数据显示,58%的人已经选择了本地部署。这个数字比去年涨了45%。
GLM-4.7-Flash+1Panel+Ollama+OpenClaw的组合,堪称本地AI部署的「最优解」。轻量、免费、易操作,兼顾性能与实用性。
无论是职场人提升办公效率,还是学生党做知识研究,亦或是普通用户体验AI,这套方案都能完美适配。
告别云端Token焦虑,摆脱数据隐私顾虑。
你的数据主权,终于不用再裸奔了。