
早!今天小编和大家分享一篇刚刚发表在Front Endocrinol (Lausanne)杂志(IF:6.055)的文章《Identification of diagnostic markers related to oxidative stress and inflammatory response in diabetic kidney disease by machine learning algorithms: Evidence from human transcriptomic data and mouse experiments》,研究方向是氧化应激和炎症,并不是新方向,但是文章的影响因子还是不错的,说明文章还是有可借鉴之处的。下面我们就一起来看看吧!
背景&方法
糖尿病肾病 (DKD) 是糖尿病的长期并发症,可引起肾脏微血管疾病。它也是导致终末期肾病(ESRD)的主要原因之一,具有复杂的病理生理过程。在DKD中,氧化应激与炎症细胞密切相关,炎症细胞常相互共存、相互激活。过度的氧化应激和炎症反应导致肾间质、肾小球和肾足细胞的损伤,从而损害肾功能。因此,及时防治对延缓DKD具有重要意义。本研究旨在使用生物信息学分析来寻找可能成为 DKD 治疗靶点的关键诊断标志物。
方法
数据来源和处理
从GEO数据库下载了DKD的7个数据集。“sva”R 包用于从不同数据集中去除批处理效应。主成分分析 (PCA) 用于评估去除批次效应的效果,并可视化 DKD 和正常患者样本的分布。随后,从 MsigDB 的Gene Ontology (GO) 知识库获得了 458 个氧化应激相关基因,从 HALLMARK_INFLAMMATORY_RESPONSE获得了200个炎症相关基因。

DEGs的鉴定和功能富集分析
“limma”R 包用于差异分析(|log2FC|>0.5,padj < 0.05)。使用过度表示分析 (ORA) 分析上调和下调的基因。
DEOIG 的共识聚类分析
R 包“ConsensusClusterPlus”用于共识无监督聚类分析,并根据差异表达的氧化应激和炎症反应相关基因 (DEOIG) 的表达水平将患者分为不同的分子亚型。“clusterProfiler”R 包用于执行基因集富集分析 (GSEA)。单样本基因集富集分析 (ssGSEA) 分析用于量化与 DKD 相关的通路。
加权基因共表达网络分析
基于 113 个 DKD 样本的表达相似性,使用加权相关网络分析 (WGCNA) 方法将基因分为不同的模块。根据模块中基因的重要性评估以及模块与亚型之间的相关性分析,找到一个与DKD高度相关的模块,并将该模块中的基因用于后续研究。
DKD 诊断标志物的筛选和验证
将WGCNA分析得到的模块基因进行蛋白质-蛋白质相互作用(PPI)分析。应用Cytoscape软件的CytoHubba插件筛选核心基因。插件利用MCC、dmnc、MNC、degree、EPC、bottleneck、eccentricity、closeness、radiology、betweenness、stress、clustering efficiency等12种算法对基因进行打分,筛选出满足12种算法的基因作为候选基因. 接下来,利用最小绝对收缩和选择算子 (LASSO) 逻辑回归, Random Forest (RF) 和Support Vector Machine_Recursive Feature Elimination (SVM_RFE)筛选候选基因,三种算法的重叠基因被视为诊断标记。接受者操作特征 (ROC) 曲线用于评估诊断标记的诊断功效。
列线图评分系统的建立与验证
使用列线图评分系统,开发基于诊断标记的 DKD 诊断模型。校准曲线用于评估列线图的准确性,DCA来评估列线图的临床效用。
GSEA富集分析诊断标志物的生物学功能和通路
ssGSEA 分析用于量化 28 个免疫相关基因组。根据每个诊断标志物的基因表达情况将样本分为高表达组和低表达组,并使用GSEA分析来探索与每个基因相关的生物学功能和通路。
动物实验验证
研究结果
数据处理
PCA图显示批次效应得到了有效校正。合并数据后,可以准确地区分DKD和正常样本。差异分析共确定了 772 个DEG,其中 381个基因上调,391个基因下调。接下来,对得到的差异基因进行了ORA 富集分析,这些基因富集在“INFLAMMATORY_RESPONSE”、“EPITHELIAL_MESENCHYMAL_TRANSITION”、“APOPTOSIS”、“TNFA_SIGNALING_VIA_NFKB”等通路中。

DKD 中不同亚组的识别
将氧化应激和炎症反应相关基因与先前获得的 DEG 进行交叉,得到 84 个 DEOIG。接下来,使用 R 包“ConsensusClusterPlus”根据这 84 个 DEOIG 将 DKD 患者分为不同的亚组。当共识矩阵k值为2时,DKD样本间的交叉最小,113 个 DKD 样本被分为两个不同的簇(C1 和 C2)。对两个亚型进行GSEA通路富集分析和ssGSEA免疫分析。

WGCNA构建及关键模块识别
对7个数据集的113 个 DKD 样本进行WGCNA 分析。最终,MEblue 模块与 C1 和 C2 亚型的相关性最高。提取了 MEblue 模块中的基因用于后续分析。

糖尿病肾病诊断标志物的鉴定
对糖尿病肾病两种亚型的差异分析,获得了 473 个差异基因。与MEblue 模块中的 1458 个基因交叉后,得到347 个交叉基因。PPI互作分析的12 种算法获得了 279 个基因。使用 LASSO 回归算法、随机森林 (RF) 和SVM-RFE算法获得了4个基因作为 DKD 的诊断标志物。
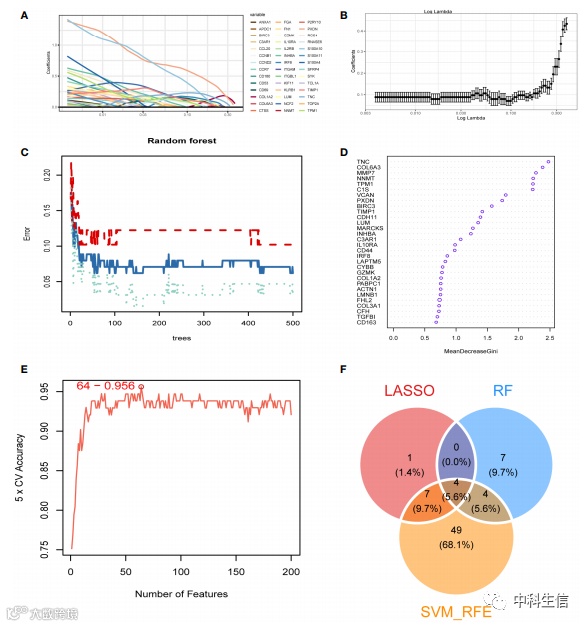
四种诊断标志物的诊断价值及验证
四种基因在DKD样本中的表达均高于正常样本。Nephroseq v5在线数据库中的样本也验证了它们的高表达。在合并的 GEO 数据集中,ROC 曲线的曲线下面积 (AUC) 为 0.808。此外,还评估了这四种基因在来自GSE142025数据集的独立患者队列中的诊断功效。每个基因的ROC曲线的AUC值均大于0.8,表明这4个基因可以诊断DKD。相关性分析表明,4个基因的表达量与肌酐呈正相关。

基于特征基因的DKD诊断模型Nomogram构建
基于四种诊断标志物的表达,我们构建了基于逻辑回归的诊断模型,并绘制了列线图。校准曲线显示列线图可以可靠地诊断 DKD,ROC曲线表明该模型的AUC值为0.801,DCA 结果显示净收益 (NB) 通过四个单独的基因或它们的组合评估 DKD 患者的结果。

诊断标记的功能富集分析
分析这四个诊断标记与免疫细胞的相关性。结果表明它们与大多数免疫细胞浸润呈正相关,例如活化的 CD4 T 细胞、活化的树突细胞、调节性 T 细胞、巨噬细胞等。接下来,根据基因表达将 DKD 样本分为高表达组和低表达组。对高表达组和低表达组差异表达基因进行GSEA分析,探索可能涉及的信号通路,发现4个基因的通路富集是一致的。

动物模型验证
为了进一步验证四种标志物在早期 DKD 诊断中的诊断价值,使用 12 周龄的 db/db 小鼠作为自发性 DKD 模型。对小鼠的体重、血糖、HbA1c、血清肌酐、血尿素氮和尿白蛋白/肌酐水平进行了比较。接下来,RT-PCR和免疫组化检测了四种生物标志物的 mRNA 和蛋白水平。

