
01
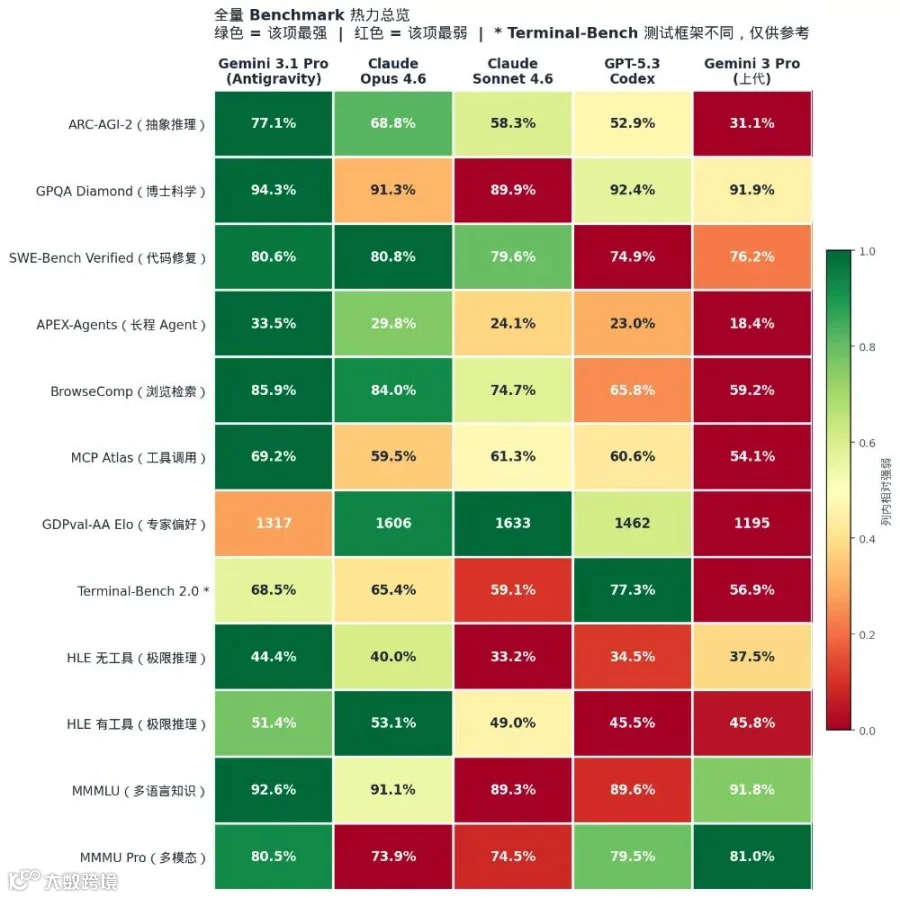
基准测试
|
测试内容
|
Gemini 3.1 Pro
|
Claude Opus 4.6
|
Claude Sonnet 4.6
|
GPT-5.3-Codex
|
Gemini 3 Pro
|
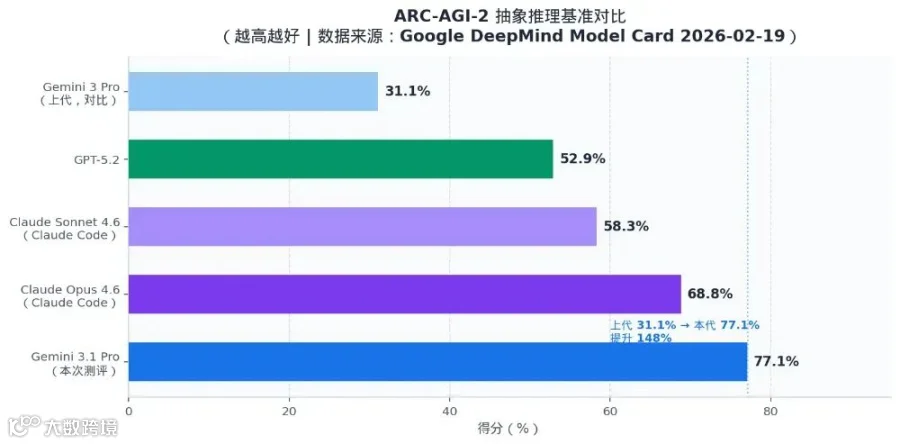
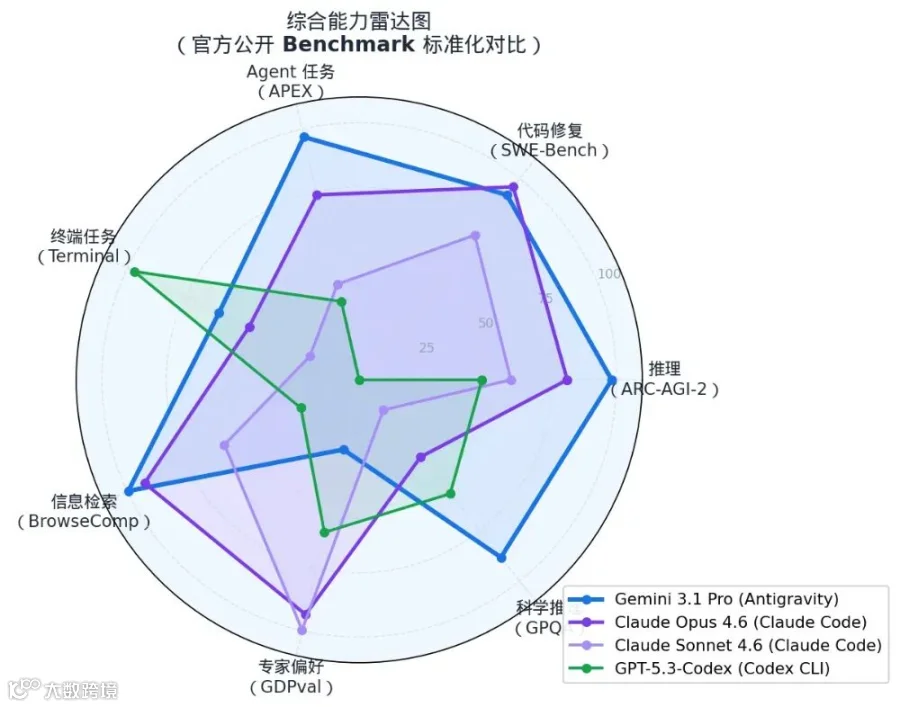
ARC-AGI-2
|
抽象推理(全新逻辑)
|
★ 77.1%
|
68.8%
|
58.3%
|
52.9%
|
31.1%
|
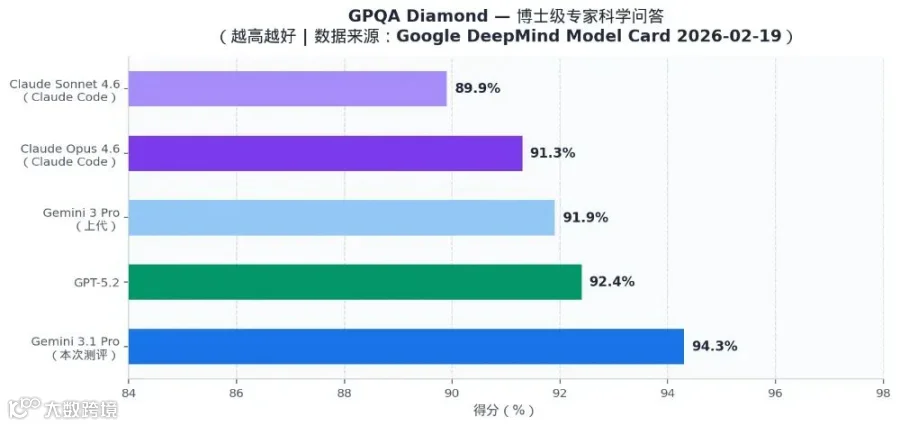
GPQA Diamond
|
博士级科学问答
|
★ 94.3%
|
91.3%
|
89.9%
|
92.4%
|
91.9%
|
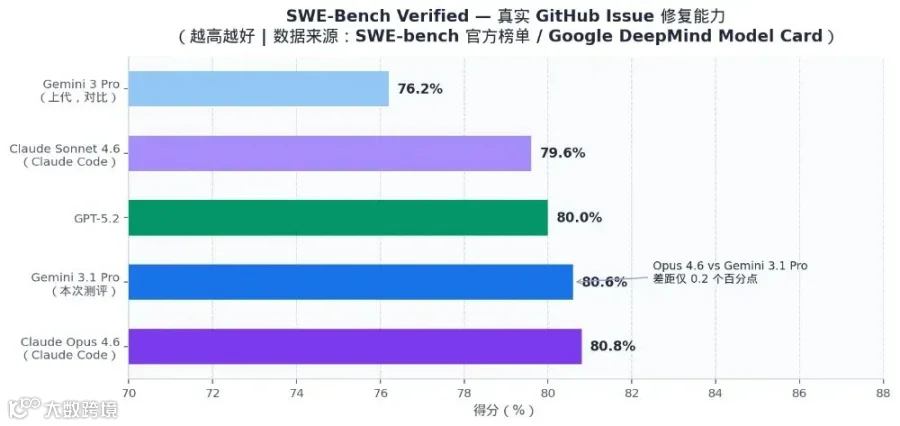
SWE-Bench Verified
|
真实 GitHub Issue 修复
|
80.6%
|
★ 80.8%
|
79.6%
|
74.9%
|
76.2%
|
SWE-Bench Pro
|
更难版代码修复
|
54.2%
|
—
|
—
|
★ 56.8%
|
43.3%
|
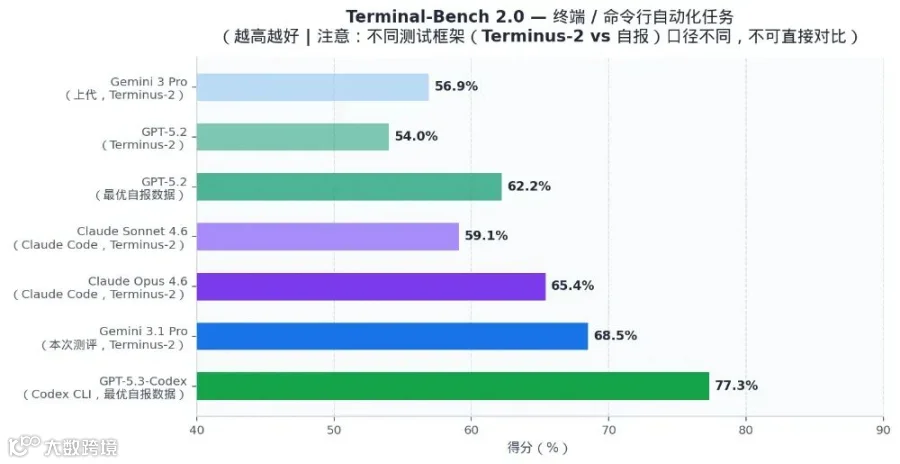
Terminal-Bench*
|
终端自动化(Terminus-2)
|
68.5%
|
65.4%
|
59.1%
|
★ 77.3%†
|
56.9%
|
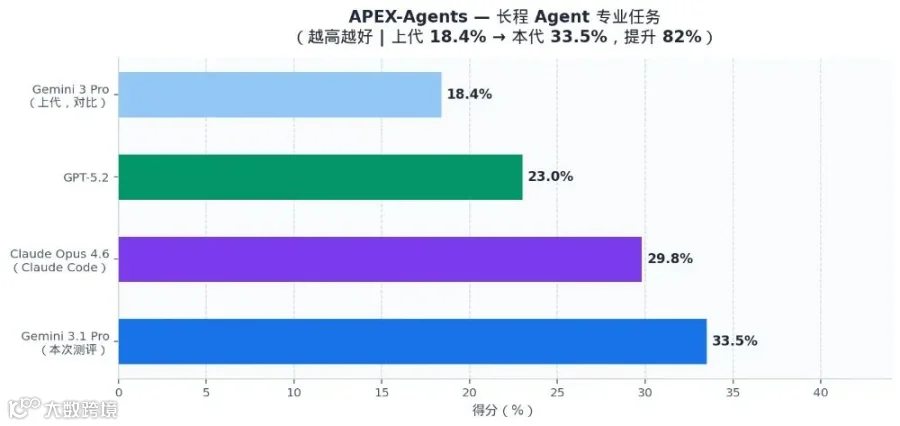
APEX-Agents
|
长程 Agent 任务
|
★ 33.5%
|
29.8%
|
24.1%
|
23.0%
|
18.4%
|
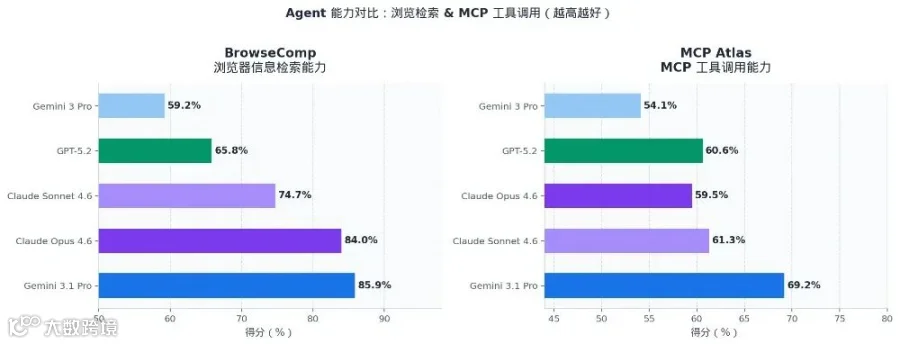
BrowseComp
|
浏览器信息检索
|
★ 85.9%
|
84.0%
|
74.7%
|
65.8%
|
59.2%
|
MCP Atlas
|
MCP 工具调用
|
★ 69.2%
|
59.5%
|
61.3%
|
60.6%
|
54.1%
|
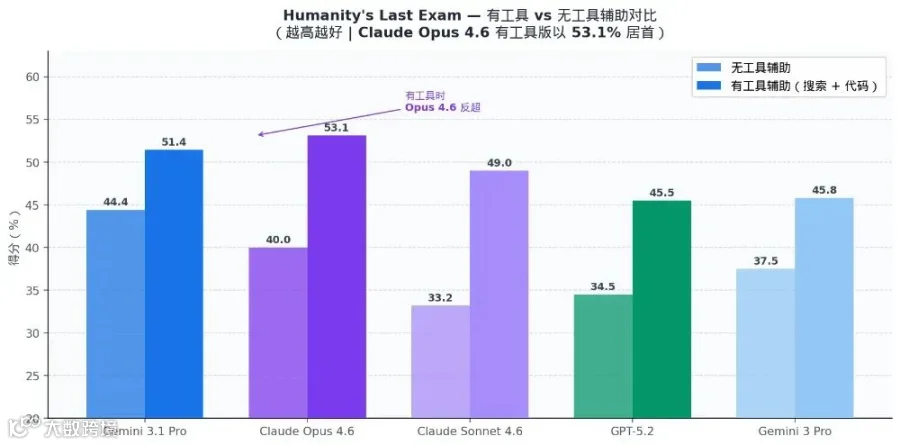
HLE(无工具)
|
人类最难试题
|
★ 44.4%
|
40.0%
|
33.2%
|
34.5%
|
37.5%
|
HLE(有工具)
|
人类最难试题 + 工具
|
51.4%
|
★ 53.1%
|
49.0%
|
45.5%
|
45.8%
|
LiveCodeBench Pro
|
竞技编程 Elo
|
★ 2887
|
—
|
—
|
—
|
2439
|
MMMLU
|
大规模多语言理解
|
★ 92.6%
|
91.1%
|
89.3%
|
89.6%
|
91.8%
|
MMMU Pro
|
多模态理解推理
|
80.5%
|
73.9%
|
74.5%
|
79.5%
|
★ 81.0%
|
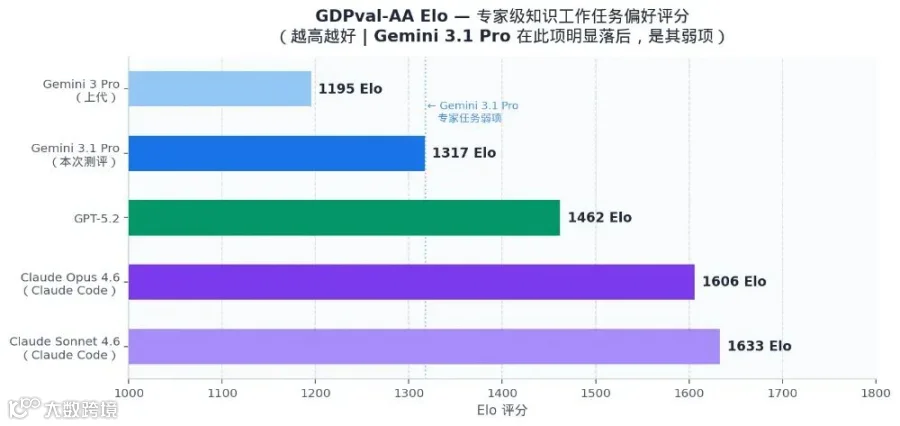
GDPval-AA Elo
|
专家偏好任务
|
1317
|
1606
|
★ 1633
|
1462
|
1195
|
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
02
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
03
-
使用 Server Components 加载初始数据,Client Components 处理交互 -
通过 WebSocket 连接 Go 后端,实时接收卡片状态更新 -
拖拽排序(原生 Pointer Events,不用第三方拖拽库) -
Optimistic UI:拖拽时立即更新界面,请求失败时回滚 -
WCAG 2.1 AA 无障碍访问(键盘导航 + 屏幕阅读器) -
TypeScript strict mode,Tailwind CSS 样式
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
RAG(检索增强生成)管道:文档分块 → Embedding → pgvector 存储 → 相似检索 → LLM 生成摘要 -
支持增量更新(新文档上传后自动 re-index) -
流式输出(Server-Sent Events,实时返回摘要 token) -
Redis 缓存摘要结果(TTL 1小时,相同文档哈希命中缓存) 5. LangChain LCEL 链式调用 6. pytest-asyncio 完整测试,mock LLM 调用
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
给出 SQL 执行时序分析(解释 race condition 如何触发) -
给出至少两种修复方案,分析各自在 Go + PostgreSQL 场景下的权衡 -
修复后 go test -race 通过,p99 延迟 < 50ms -
补充并发场景的集成测试(用 testcontainers -go 起真实 PostgreSQL)
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
-
Go 后端:新增 / api /tasks/:id/summary 接口,调用 Python AI 服务( gRPC ),处理超时和降级 -
Next.js 前端:任务详情页新增"AI 摘要"按钮,流式展示摘要结果( EventSource API) -
三层完整联调可运行(docker-compose 一键起服务) -
错误处理:AI 服务不可用时降级展示提示,不影响主功能
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
04
|
|
|
|
|
|
|---|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
05
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|