

本文作者:「DaoCloud 道客」推理加速团队(冷荣富、潘远航、刘齐均、王昱奇、潘彬、李中军等)
在客户提出部署 DeepSeek V3.2 的 SLA 要求之后,如何在 vLLM 开源版本下部署出满足 SLA 要求的推理服务是一个难点,「DaoCloud 道客」团队基于对 vLLM 的使用调优和功能优化以及修复最终得到了满足 SLA 要求的部署形态和最终版本,并把优化代码贡献给了社区。
SLA 与
负载定义
1.1 性能目标(SLA)
目标要求如下:
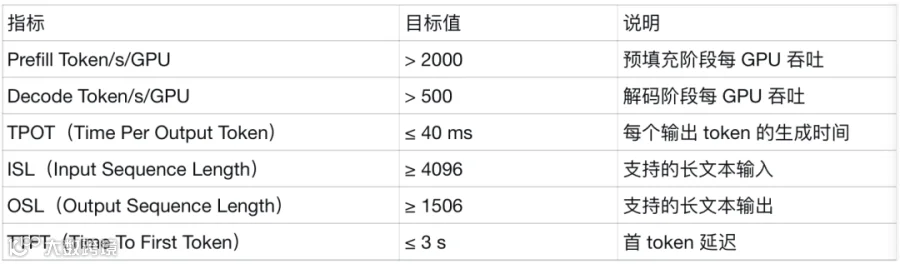
1.2 负载定义与统计口径
TTFT/TPOT 的统计口径:mean
Prefill/Decode tok/s/GPU 的计算公式与采样方式:
Total token throughput (tok/s) / GPUs负载类型:最小 ISL/OSL
使用 DeepGEMM warmup、使用随机种子
02
为什么照 Wide-EP 路线
难以直接达标
在先前文章《vLLM Large Scale Serving: DeepSeek-R1 @ 2.2k tok/s/H200 with Wide-EP》中,Wide-EP 策略在 R1 模型上实现了约 2.2K token/s/GPU 的吞吐。然而,在 DeepSeek-V3.2 上直接沿用该方案却无法达到目标,主要原因包括:
模型结构的差异:DeepSeek-R1 使用的是 MLA,而 V3.2 使用的是 DSA。
vLLM 对 V3.2 的 Attention 实现目前还在持续迭代,还有优化空间。
vLLM 在一些组合、Case 下还存在 Bug。
于是 DaoCloud 的 vLLM 工程师们,就开启了一段针对 DSV3.2 的性能优化之旅。
03
方法总览:
SLA 达标决策树
下面的方法在未来版本或许有不同的优化思路,比如:
社区在优化Attention 可以放置16 个 Head的情况,这个时候 TP8也许就是最优的。
针对异步调度问题社区也已经修改,最好使用
--no-disable-nccl-for-dp-synchronization来代替关闭异步调度。未来还有新技术,比如PCP、DCP等等。
3.1 Prefill 优化路线
现象:
TTFT 随并发快速变差
Prefill 吞吐不够,系统排队导致 TTFT 抬升
优化动作(按顺序):
1、先降 TP,再用 DP 扩吞吐: 经验上 Prefill 更容易受 TP 通信影响:先把 TP 降到 1/2,再引入 DP 来提高吞吐
2、检查 async scheduling 的 DP 同步路径
若日志出现
DP Using CPU all reduce ...,说明 DP padding 同步可能走了 CPU 路径新版本使用
--no-disable-nccl-for-dp-synchronization, 旧版本使用--no-async-scheduling
3、多节点时引入 EP + 负载均衡(EPLB)
可以通过观察 GPU 的利用率来分析对于当前的 Input Token 专家是否会出现负载不均衡的场景,Prefill 在多节点下更容易暴露通信与专家负载不均,可以通过开启 EPLB 进行动态负载专家。
EPLB 中的冗余专家数 num_redundant_experts 也比较关键,过大会导致占用过多的 GPU HBM,理想情况下一个 GPU 放置一个冗余专家最佳。
4、高效 all-to-all 通信
在单节点场景下可选用 PPLX 作为 all-to-all backend。
在多节点下 Profile 默认选用 DeepEP 的 deepep_high_throughput 模式,Decode 模型选用 deepep_low_latency 模式。
5、设置合理的 max-num-batched-tokens 、 gpu_memory_utilization 避免容易触发 OOM
max-num-batched-tokens是调度器的上限(每次迭代允许的总 token 数),启动的时候由服务端设置,但是设置为多少其实很有考究,需要根据 ISL 长度、DP Rank 组数量、模型剩余显存、KVCache 空间来综合考虑。gpu_memory_utilization设置 vllm 可以使用的 GPU 显存空间,比如在开启 CUDA Graph 的情况下,会占用更多的显存。
验证方式:
固定
ISL=4096, OSL=1,逐步提高并发观察 TTFT 是否在目标内,Prefill tok/s/GPU 是否稳定超过 2000 Token/s/GPU
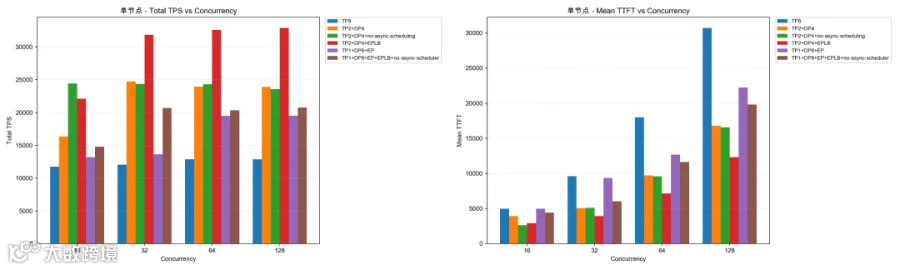
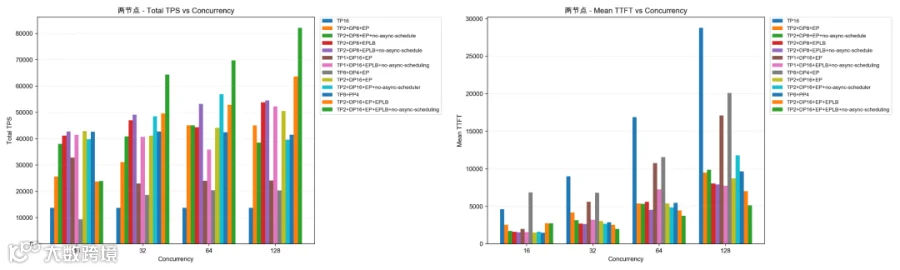
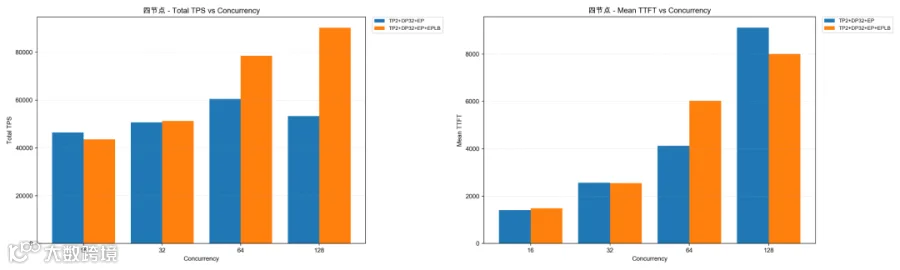
下面是测试过程中各种随着优化的启动参数在不同并发下的得到的测试数据,根据测试数据来分析最终的方案;根据数据来看在两节点下数据最好,所以后续 P/D 分离的时候也采用了两节点组成的 P。
Tips: 有些方案需要修复 bug 才能运行。
单节点
两节点
四节点
04
寻找 Hopper 架构
下的“甜蜜点”
Prefill 阶段负责处理输入提示词,计算生成首个输出 token 前的 KV 缓存。为了测试 Prefill 阶段性能,我们将输出长度(OSL)设置为 1、输入长度(ISL)设置为 4096,并分别在单机、双节点等场景做对比测试。
4.1 Benchmark 命令(示例)
这里提供一个 benchmark 测试命令案例,后续都基于这个进行修改:
vllm bench serve \
--model /gpfs/rd/models/DeepSeek-V3.2 \
--dataset-name random \
--random-output-len 1 \
--random-input-len 4096 \
--num-prompt 256 \
--trust-remote-code \
--max-concurrency 16 \
--request-rate inf
4.2 单节点(8×GPU):Baseline vs Optimization
单节点共有 8 张 GPU 显卡
BaseLine:使用 `-tp=8` 作为基线对照组。
Optimization:使用 `-tp=2` 和 `-dp=4`以及其他优化参数作为优化对照组。
测试结果:
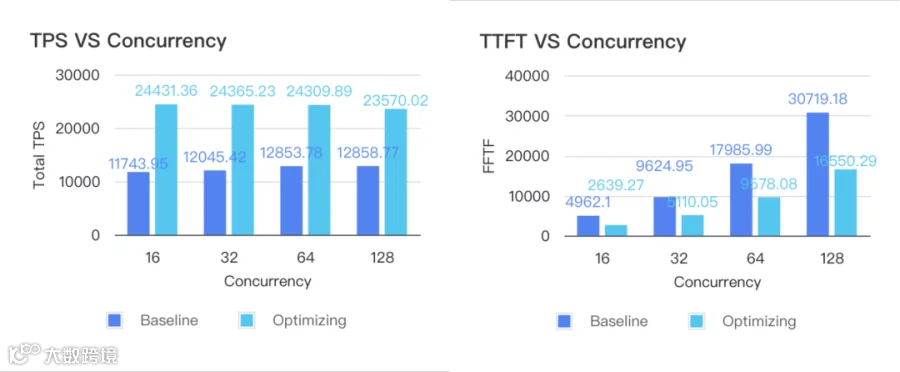
在请求并发数为 16 的情况下:
Baseline:
Total TPS(tokens/s):11,743.95
Mean TTFT(ms):4,962.10
Optimization:
Total TPS(tokens/s):24,431.36
Mean TTFT(ms):2,639.27
对比结果:
Total TPS 提升:108%
Mean TTFT 下降:46.81%
优化后 Prefill Token/Second/GPU:3,053.92
满足预定 SLA(Prefill Token/Second/GPU >= 2000,TTFT <= 3s)
4.3 双节点(16×GPU):Baseline vs Optimization
单节点有 8 张 GPU 显卡,所以双节点共有 16 张 GPU 显卡
BaseLine:使用 `-tp=16` 作为作为基线对照组。
Optimization:使用 `-tp=2` 和 `-dp=8` 以及开启 EPLB 等其他优化参数作为优化组。
测试结果
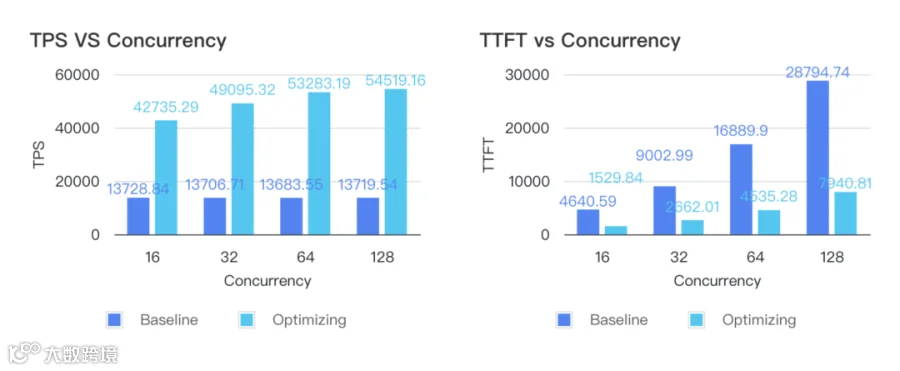
在请求并发数为 32 的情况下:
Baseline:
Total TPS(tokens/s):13,706.71
Mean TTFT(ms):9,002.99
Optimization:
Total TPS(tokens/s):49,095.32
Mean TTFT(ms):2,662.01
对比结果:
Total TPS 提升:258.18%
Mean TTFT 下降:70.43%
优化后 Prefill Token/Second/GPU:3,068.46
满足预定 SLA(Prefill Token/Second/GPU >= 2000,TTFT <= 3s)
4.4 Prefill 关键“避坑”:
4.4.1 开启 async scheduling 的影响
在使用 DP 部署的时候,总是会出现 Using CPU all reduce to synchronize DP padding between ranks. 这个 info 日志;
根据代码排查后发现在开启 async-shcheduleing 之后,就会使用 cpu 来进行 all_reduce , 于是我们在 Prefill阶段分别测试了默认开启异步调度和不开启异步调度的结果,结果证明不开启异步调度性能更好。
之后通过抓取 Profile 文件来分析在 coordinate_batch_across_dp 这一步操作的时间确认是否符合预期;
开启异步调度之后的
coordinate_batch_across_dp
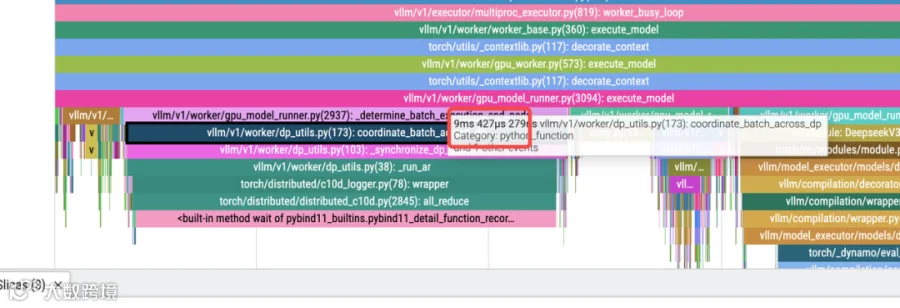
不开启异步调度之后的
coordinate_batch_across_dp,

从 Profile 中可以看出来在不开启异步调度的情况下,coordinate_batch_across_dp 消耗的时间少很多;
后续发现这个和我们单独测试 Prefill 的工作负载特性有关,在这种场景下,会导致通信开销变大;
反馈到社区之后,https://github.com/vllm-project/vllm/pull/32197 通过这个PR修复了这个功能,在开启异步调度的时候可以通过设置 --no-disable-nccl-for-dp-synchronization 来进行禁止使用 cpu 进行同步。
根据测试下来在 Prefill 阶段不开启异步调度的情况下对吞吐和 TTFT 都有一定的影响,下面是一些实测数据。
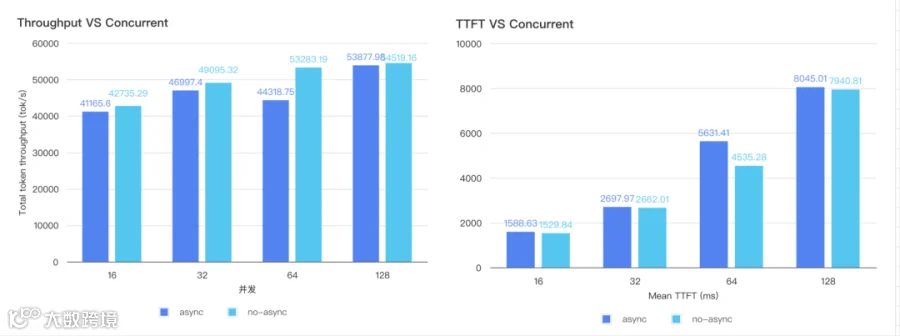
4.4.2 为什么要设置为 TP2
Prefill 的大 GEMM 运算很适合被分片切分,假如不考虑通信开销,逻辑上:机内的 TP 越大,TTFT 的优化效果更好。但是在 DeepSeek-V3.2 中会存在 TP 越大性能越差的问题,通过单节点和双节点测试数据都能证实这个结论。
核心是因为目前 FlashMLA-Sparse 内核在 Hopper 架构上仅支持 64 的倍数的头数。而 DeepSeek V3.2 总的有 128 个头,那只有在 TP1(每个 Rank 128 个 head)和 TP2 (每个 Rank 64 个 head)的情况下 head 划分是最佳的(能被 64 整除),会引入 Head 冗余 (Padding),产生了额外的计算和显存开销,直接拖慢了性能。 因此,我们将策略调整为 TP2 + DP (数据并行),这是当前架构下的数学最优解(https://github.com/vllm-project/vllm/issues/31368)
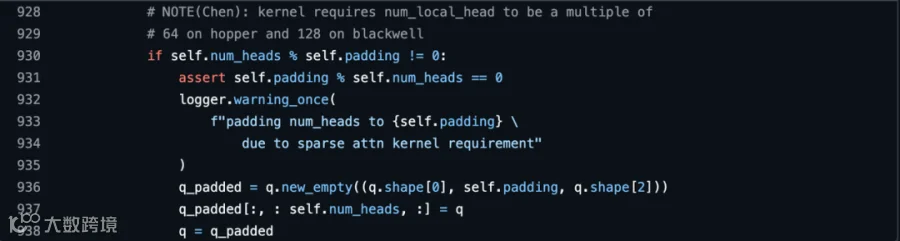
但如果是在 Blackwell 架构的 GPU 上运行,这个最佳参数变成了 TP1.
05
Decode
优化实践
为了单独测试 Decode 的性能,我们使用 DecodeBenchConnector 进行 Prefill KVCache 填充。
5.1 单节点
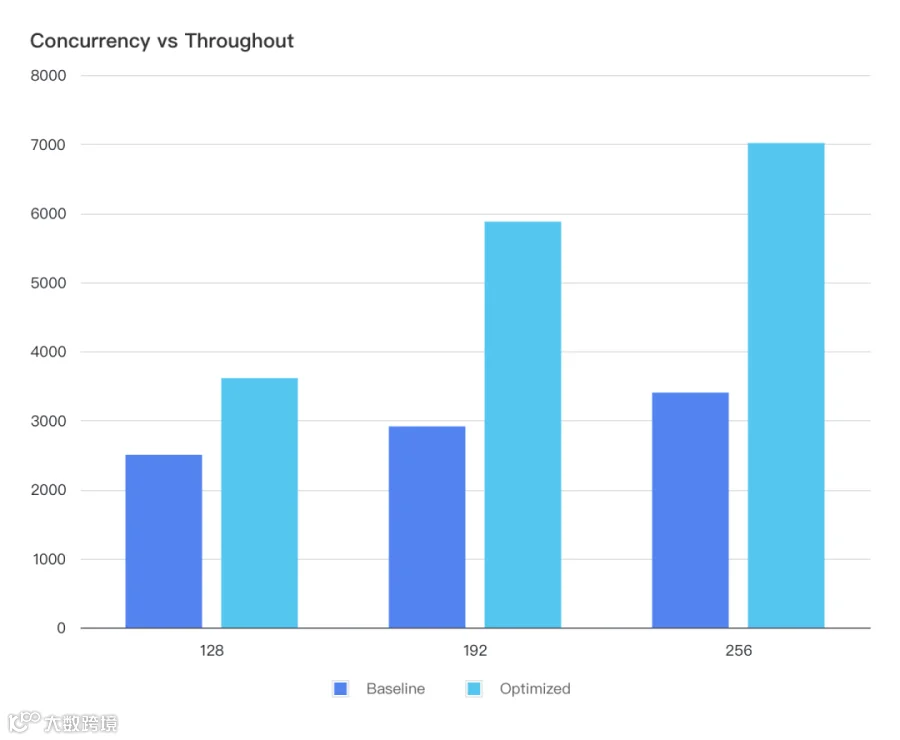
Baseline:使用 `-tp=8` 作为基线对照组。
Optimized:使用低延迟的 all2all 内核,以及开启 MTP 等优化参数作为优化对照组。
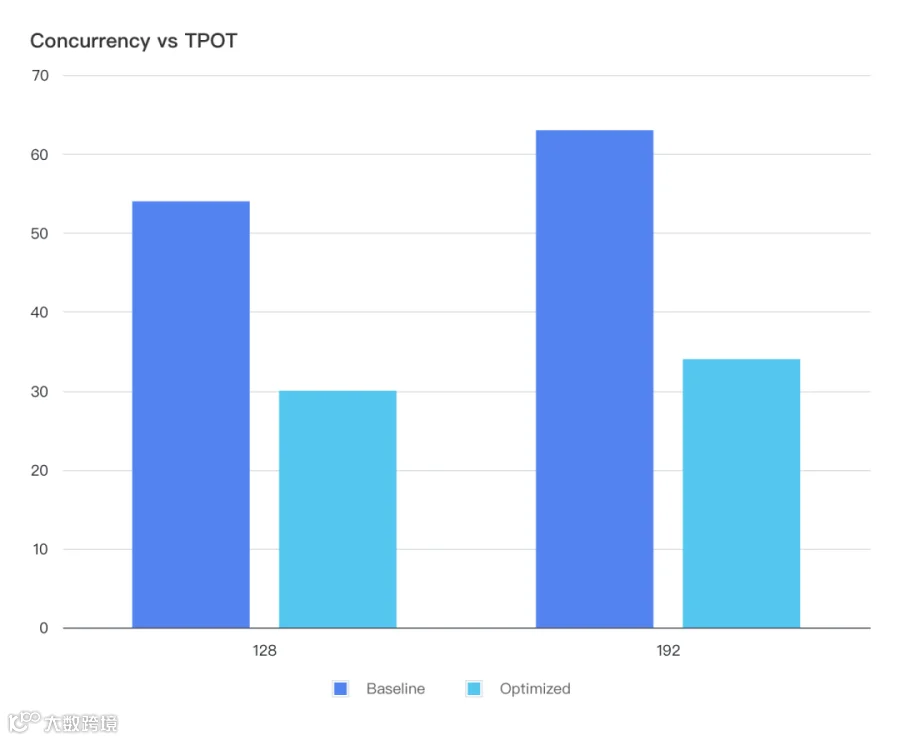
当比于 Baseline,Decode 的吞吐几乎翻倍:
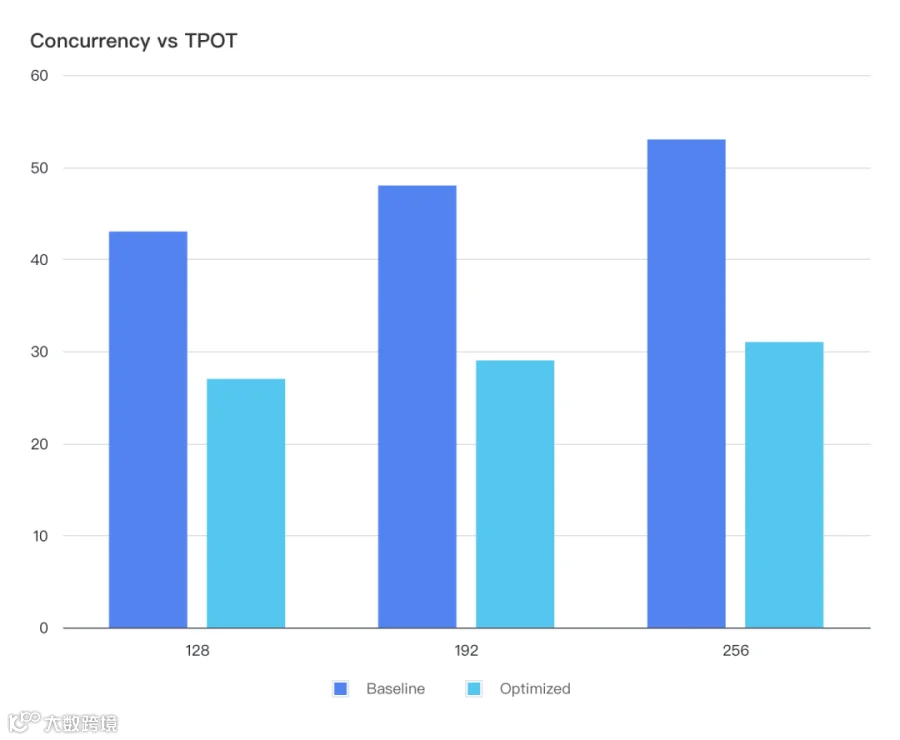
TPOT 也下降了非常多,这样才能满足 TPOT:
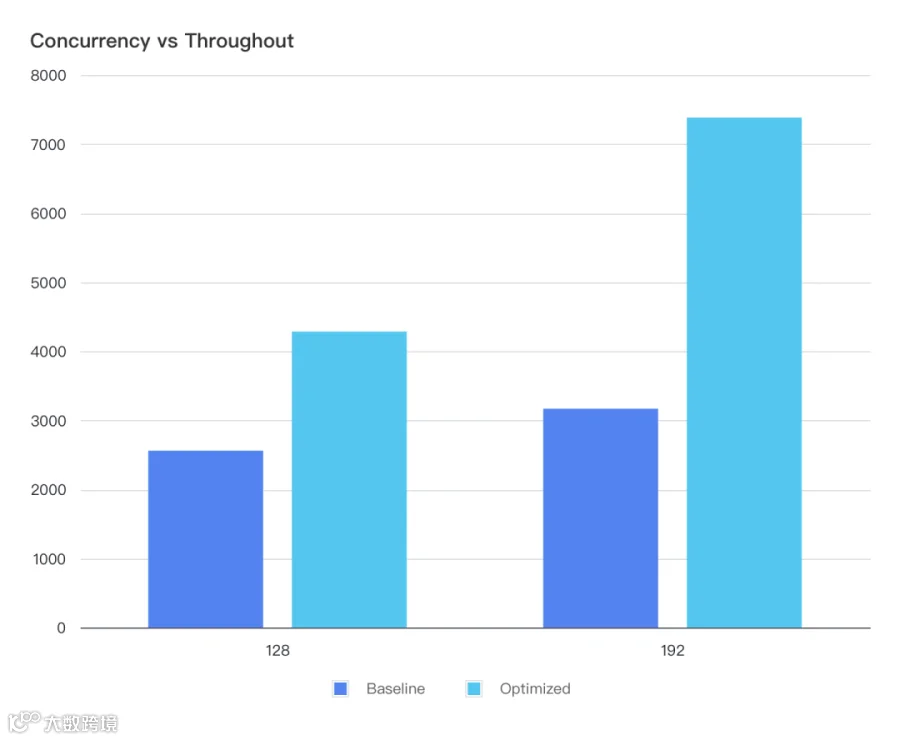
5.2 双节点
5.3 Decode 关键“避坑”
5.3.1 DSA(V3.2)对比 MLA(V3.1):TPOT 影响分析
在相同的 TP=8 并行配置下,模型架构的升级(MLA -> DSA)在注意力机制上引入了新的计算开销。
这导致单步延迟(TPOT)有所增加:
MLA (V3.1):单个推理步耗时 11.9371ms。
DSA (V3.2):单个推理步耗时 18.4465ms。
1、端到端延迟对比:DSA 模型延迟增加
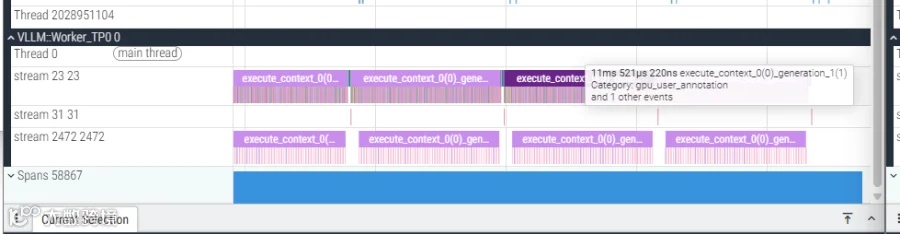
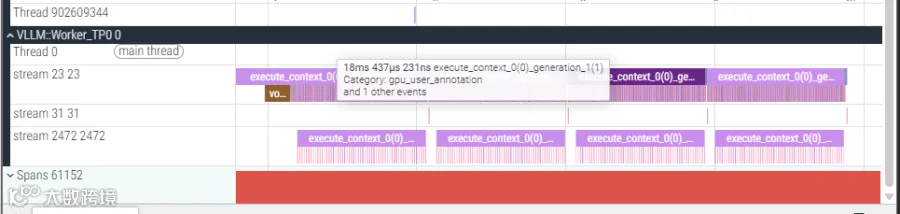
MLA (V3.1):单个推理步耗时 11ms。
DSA (V3.2):单个推理步耗时 18ms。
差距:DSA 单步延迟增加了 7ms。
延迟增量分析:注意力(Attn)算子层开销
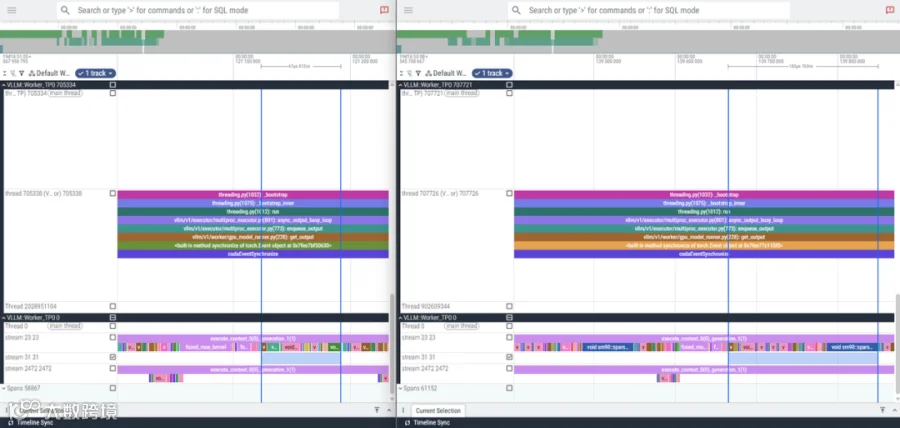
通过对关键注意力算子的分析,可以定位延迟增加的主要来源:
MLA 执行路径:
cross_device_reduce_1stage->FlashAttnFwdSm90,耗时 67µs。DSA 执行路径:
cross_device_reduce_1stage->sparse_attn_fwd_kernel,耗时 183us。层间增量:DSA 的注意力计算在每个模型层上比 MLA 慢 116us。在多层模型架构中,这一开销在端到端延迟中被逐层累积和放大,61 层相差 (61 *116us) / 1000 = 7.076ms 的总延迟增量。
2、DSA 对长上下文优化
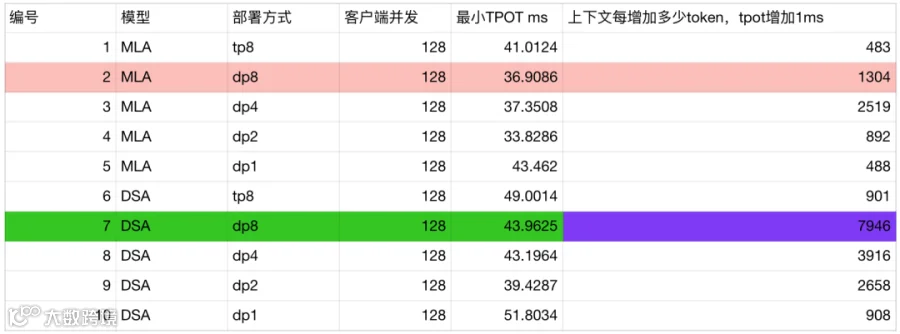
1、关于不同部署方式,MLA 与 DSA 模型的性能对比分析(编号 2 和 7 组)
最小延迟对比:在输入长度极短(上下文长度为1)时,MLA 模型的 TPOT 为 37ms,优于 DSA 模型的 44ms。
吞吐效率对比:随着上下文长度增加,MLA 模型每增加 1304 个 token TPOT 延迟增加 1ms;而 DSA 模型每增加 7946 个token,延迟才增加 1ms。
核心结论: MLA 适合“短跑”,DSA 适合“长跑”
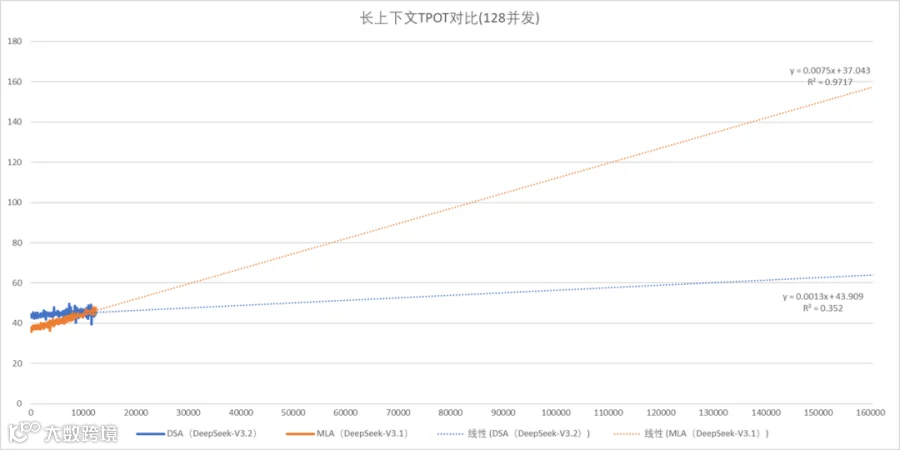
按照实际测试结果外推到 deepseek 默认支持的最长上下文 16 万,这时:
MLA 模型 TPOT 预计为 160ms
DSA 模型 TPOT 预计为 64ms
这验证了论文中的观点,即 DSA 模型在长上下文场景下,随输入增长的吞吐效率更高,能实现显著的端到端加速。其性能优势在长文本处理中更为明显。
除了 dp8 ,其他部署方式 MLA 相比 DSA 对长上下文场景也有明显提升。
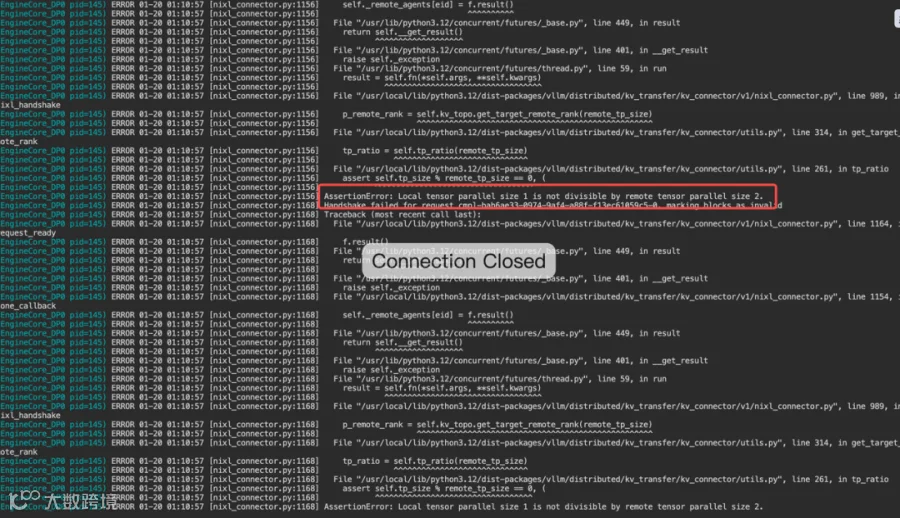
目前部署版本 Prefill 中是 TP2 最好,使用新版本之后可以让 Prefill 和 Decode 可以使用不相同的 TP 数量,性能也会有所提升。
Note :当前版本Prefill 使用 TP2 ,Decode 使用 TP1时开启之后会出现如下错误:Local tensor parallel size 1 is not divisible by remotetensor parallel size 2.
5.3.2 eplb 的 log_balancedness=true 极大的影响 Decode 性能
在我们前期的测试过程中,我们发现一旦开启 eplb,相比与不开 eplb,性能下降非常厉害:
不开 EPLB:
核心参数:--eplb-config
{"window_size":"1000","step_interval":"1000","num_redundant_experts":"32","log_balancedness":"True", "async": "True"}
开启 EPLB:
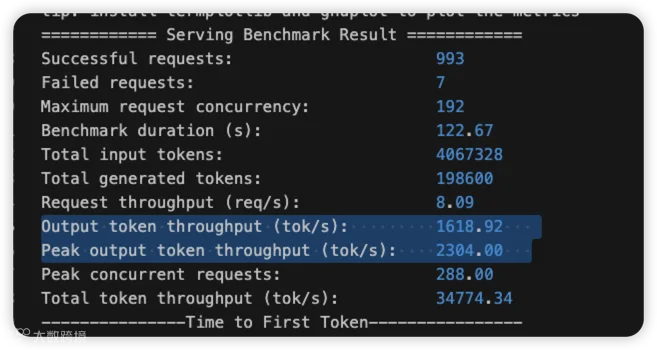
发现输出 token 吞吐差异巨大。
按照理论知识,这里不应该有如此大的差距,所以我们通过 profile 深入分析:
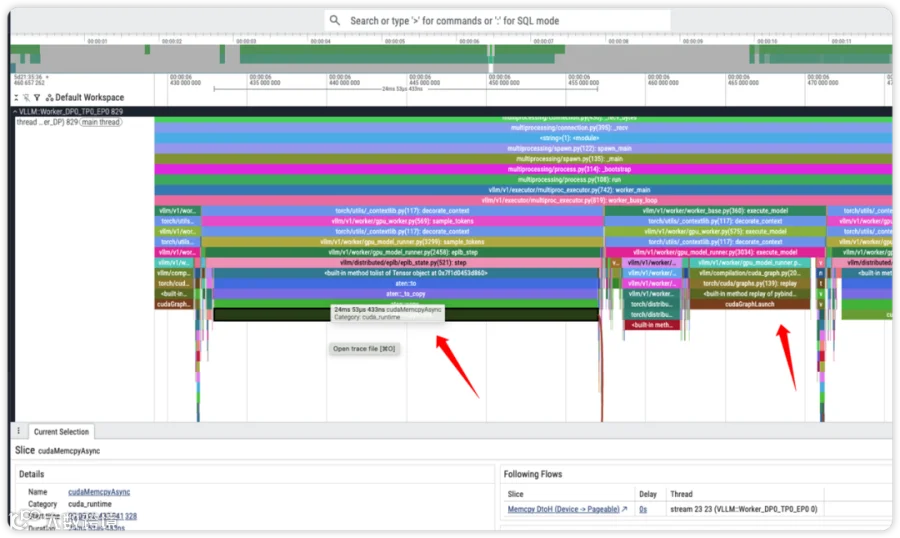
发现每次调度之后,eplb-step 都占用了非常长的时间,这比 Decode 实际执行的时间还长。
这是因为每次 log 的过程中,都需要将 gpu 里面的保存的负载均衡数据复制到内存中,然后再计算,这将消耗大量的时间和算力。
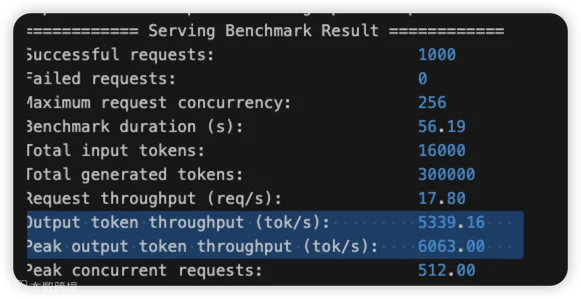
修复之后的数据:
5.3.3 MTP + PD 分离无法工作
当我们在 PD 分离的场景下开启 MTP 的时候,一旦开始压测,就会随机出现两个错误:
错误一:Invalid reshape for topk_indices
(Worker_DP0_TP1_EP1 pid=886837) ERROR 01-09 15:05:37 [v1/executor/multiproc_executor.py:822] return self._op(*args, **kwargs)
(Worker_DP0_TP1_EP1 pid=886837) ERROR 01-09 15:05:37 [v1/executor/multiproc_executor.py:822] File "/gpfs/rd/kebe/vllm/vllm/model_executor/models/deepseek_v2.py", line 763, in sparse_attn_indexer
(Worker_DP0_TP1_EP1 pid=886837) ERROR 01-09 15:05:37 [v1/executor/multiproc_executor.py:822] topk_indices.reshape(batch_size, -1, topk_indices.shape[-1]),
(Worker_DP0_TP1_EP1 pid=886837) ERROR 01-09 15:05:37 [v1/executor/multiproc_executor.py:822] RuntimeError: shape '[2, -1, 2048]' is invalid for input of size 6144
错误二:Assertion failure in fp8_paged_mqa_logits (batch size mismatch
(Worker_DP0_TP1_EP1 pid=978655) ERROR 01-09 15:49:58 [v1/executor/multiproc_executor.py:822] File "/gpfs/rd/kebe/vllm/vllm/model_executor/models/deepseek_v2.py", line 737, in sparse_attn_indexer
(Worker_DP0_TP1_EP1 pid=978655) ERROR 01-09 15:49:58 [v1/executor/multiproc_executor.py:822] logits = fp8_paged_mqa_logits_func(
(Worker_DP0_TP1_EP1 pid=978655) ERROR 01-09 15:49:58 [v1/executor/multiproc_executor.py:822] File "/gpfs/rd/kebe/vllm/vllm/utils/deep_gemm.py", line 323, in fp8_paged_mqa_logits
(Worker_DP0_TP1_EP1 pid=978655) ERROR 01-09 15:49:58 [v1/executor/multiproc_executor.py:822] return _fp8_paged_mqa_logits_impl(
(Worker_DP0_TP1_EP1 pid=978655) ERROR 01-09 15:49:58 [v1/executor/multiproc_executor.py:822] RuntimeError: Assertion error (csrc/apis/attention.hpp:192): batch_size_next_n == batch_size * next_n
深入研究发现是在 PD 分离的时候,一部分请求没有 MTP 的 Draft 结果,需要 padding(对齐),但是代码并没有很好的处理一部分 padding,所以导致错误,我们已经修复:
https://github.com/vllm-project/vllm/pull/32175
06
生产部署
路径
基于上述 Prefill 和 Decode 不同的优化方式,发现P和D角色的优化参数是迥然不同的,混合部署显然不是最优解。所以我们最终采用了 P/D 分离 (Prefill/Decode Separation) 架构。
架构拓扑
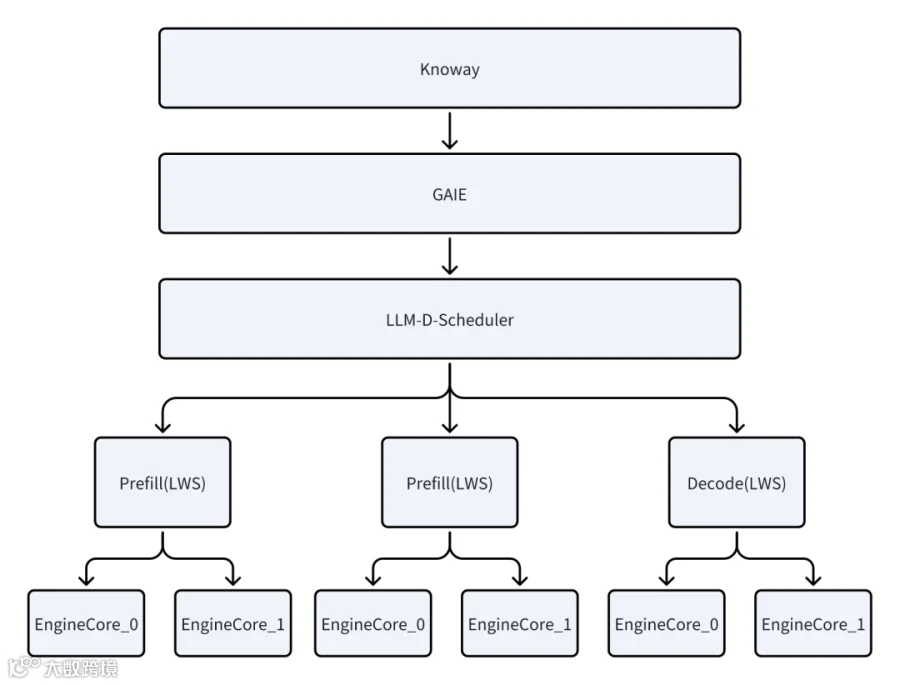
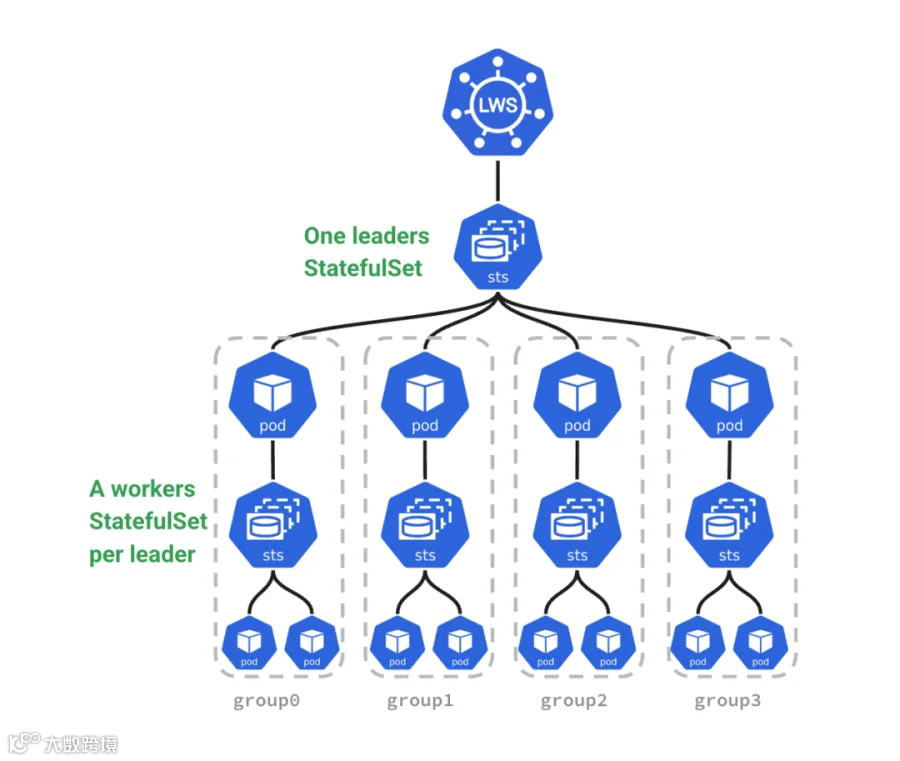
我们利用 K8s 原生的 llm-d 和 LWS 项目, 构建了 2P1D 的生产集群
Prefill 实例 (P): 部署 2 组。每组采用 2 节点 (TP2+DP+EP) 配置。
TP2 是算力利用率最高的配置 ,双节点在满足 TTFT SLO 的限制下能提供良好的并发支持。
后续并发量提高,也能够在2的基础上上比较容易进行扩缩容。
Decode 实例 (D): 部署 1 组。采用 2 节点 配置
单节点显存容易耗尽 KV Cache导致 OOM,双节点提供了更大的 KV Cache 空间以支持高并发 Decode 。
最终部署采用 2P1D 的架构进行部署,在满足 SLA 的情况下可以支持较高的吞吐和并发,随着并发增加可以进行扩充 P 来支持。(部署架构图如下)
在 P/D 分离的场景下通过max-concurrent较难测试出符合预期的数据,这里改用 reqeust-rate + max-concurrent 的组合来控制服务端处理的 sequence 数据。
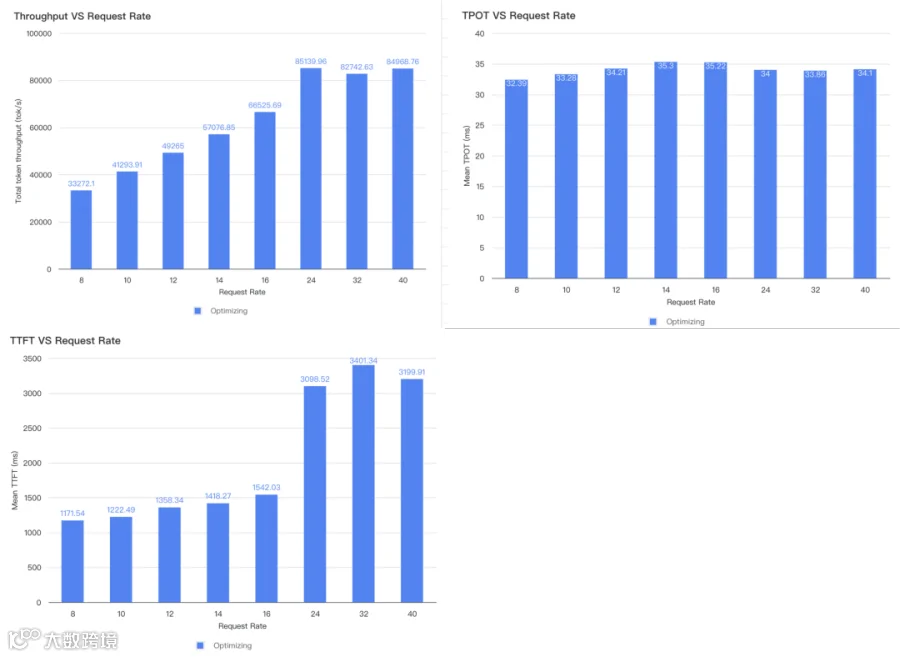
在 2P1D 架构下,系统展现了强大的吞吐能力:
最大吞吐: 85,000 tokens/s (在没有使用前缀缓存的情况)
并发能力: 支持 Request Rate = 24 req/s 且 Max Concurrent = 170,在此负载下 SLA 依然稳健达标。
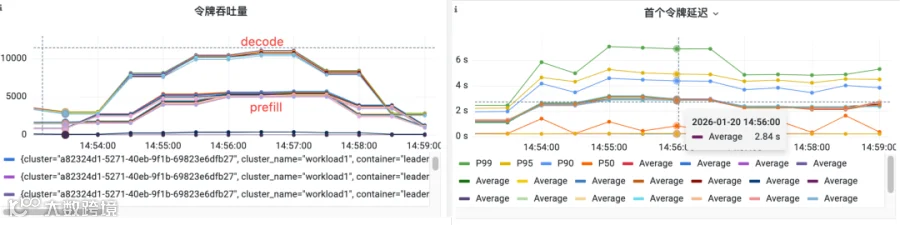
监控数据: 下面是从监控中查看P/D 每个 Engine 的吞吐数据、TTFT 数据,都是看到也是满足 SLA 的,首 Token 延迟稳定在 2.84s 左右 (P90) 。
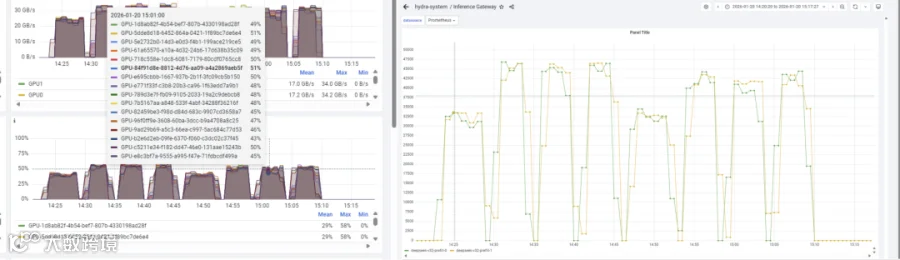
Prefill 服务中的 GPU SM Activity 也能到 50%,NVLink RX/TX 都能到30GB/s;Prefill 和 Decode 节点的负载也比较稳定和均衡。
6.1 技术框架介绍
我们采用 llm-d 做了云原生的 P/D 分离的协调和编排,无论在控制流(部署,启动)还是数据流(PD 网关,KV-路由)都有良好的功能和性能支撑。
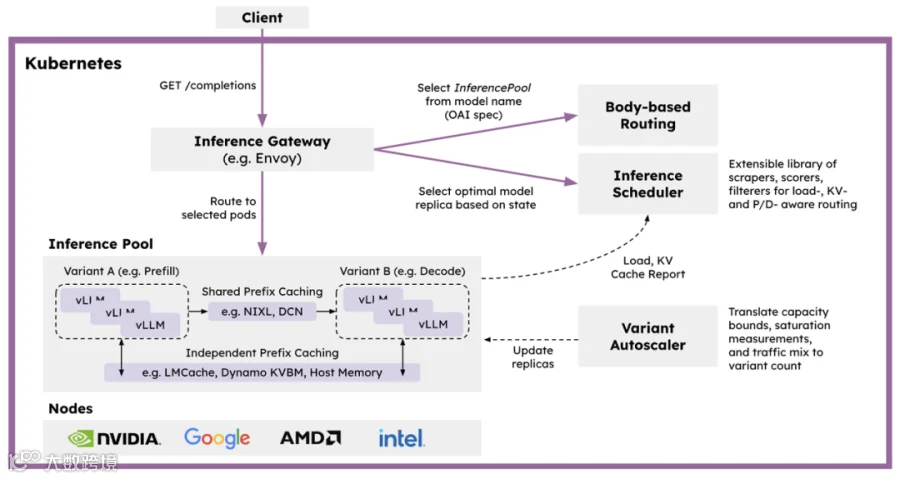
llm-d 介绍: 是一个原生于 Kubernetes 的高性能分布式 LLM 推理框架,能够以最快的速度实现价值,并提供极具竞争力的性价比。llm-d 基于 vLLM、Kubernetes 和推理网关构建,提供模块化的分布式推理解决方案,并具备键值缓存感知路由和解耦服务等特性。
我们还采用了 LWS 作为跨多台节点的单个 vLLM 实例的云原生编排。
LeaderWorkerSet(LWS)介绍:一个用于将一组 Pod 作为复制单元进行部署的 API。它旨在解决 AI/ML 推理工作负载的常见部署模式,特别是多主机推理工作负载,其中 LLM 将被分片并在多个节点上的多个设备中运行。初始设计和提案可在以下网址找到:
http://bit.ly/k8s-LWS。
07
总结
在进行部署和解决问题过程中,也得到了很多 vLLM 社区成员的帮助,在此感谢社区;公司的团队成员在这个过程中也提出了很多遇到的问题并记录 issue,和解决问题的方案提交 PR,来反馈给社区。
热门推荐

访问以下网址,
快速获取高效能 AI 算力

DaoCloud 公司简介
网址:www.daocloud.io
邮件:info@daocloud.io
电话:400 002 6898
