
当AI连麻将中最基础的听牌场景都无法准确识别时,我们是否高估了其实际应用能力?本文通过实测豆包与Gemini在麻将决策中的表现,揭示当前AI在多模态识别、语音处理与场景理解上的局限性。
———— / BEGIN / ————
先说结论:
别说打麻将了,就连最基础的“听牌”(再摸一张即可胡牌),AI目前都难以准确完成。
使用场景
场景:四人线下打麻将。
任务:通过豆包视频对话辅助决策。为降低难度,测试中明确告知AI“已听牌”。
测试重点:推理能力、视觉识别能力、语音声纹分辨能力。
截图显示当前听牌状态为:9条、1饼(1筒)。

结果,均未达标
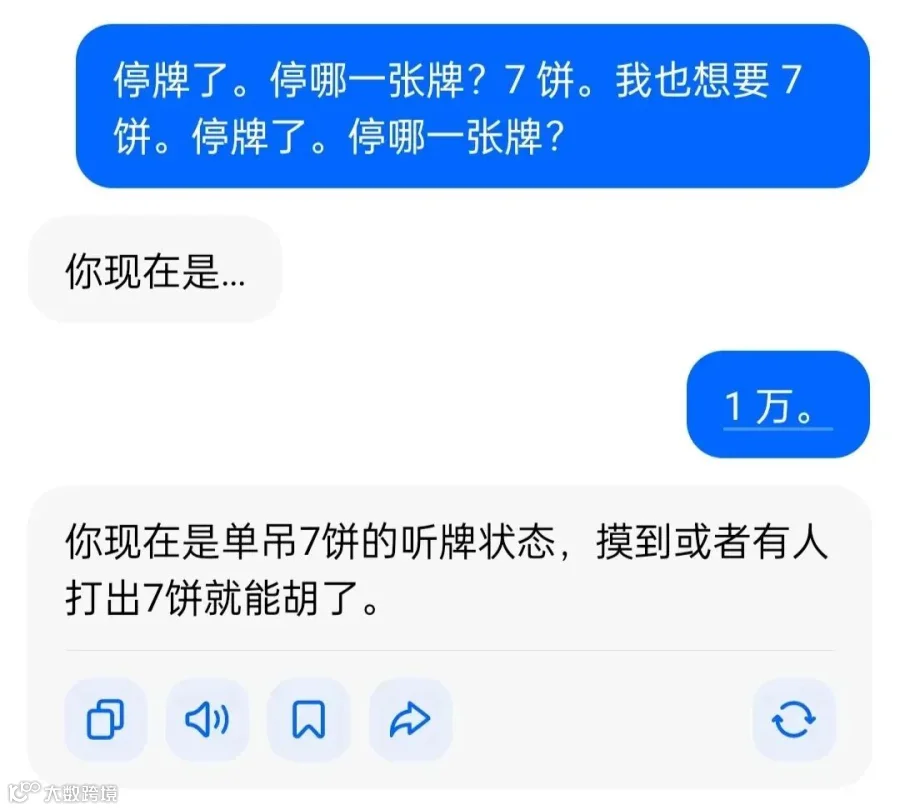
提问:“听牌了,听哪张?”
豆包回复:“单吊7饼。”
问题分析如下:
1. 文字识别
语音转文字阶段将“听牌”误识别为“停牌”,虽最终输出仍为“听牌”,但说明底层文本纠错或上下文修正能力不足。
2. 视觉识别
未能准确识别手牌构成及听牌张数,答案与画面完全不匹配。可能受限于图像质量、光照条件或模型对麻将牌面特征的学习不足。
3. 语音声纹分辨
无法区分用户本人与其他玩家语音,将他人发言(如“我要7饼”“一万”等)一并纳入Prompt处理,导致决策依据错误。
因此得出错误结论“单吊7饼”。
尝试改用静态截图上传方式测试:
期望AI通过高亮、裁剪、放大等手段从低质量图片中提取关键信息。
4. 图片识别
上传同一张截图后,豆包判定为“听五万和六筒”,仍与真实听牌不符。
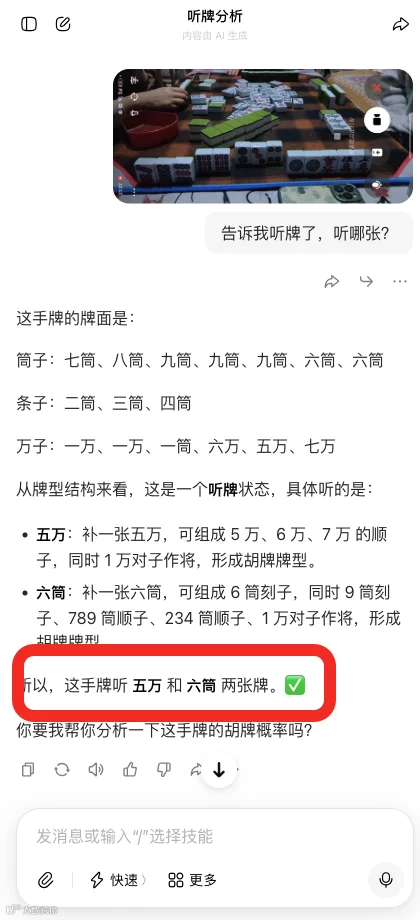
连最基础的听牌识别尚且失败,更遑论替代人类完成整局博弈。
继而测试Gemini表现。
Gemini,同样未达预期
上传相同截图,提问:“听牌,听哪几张?”
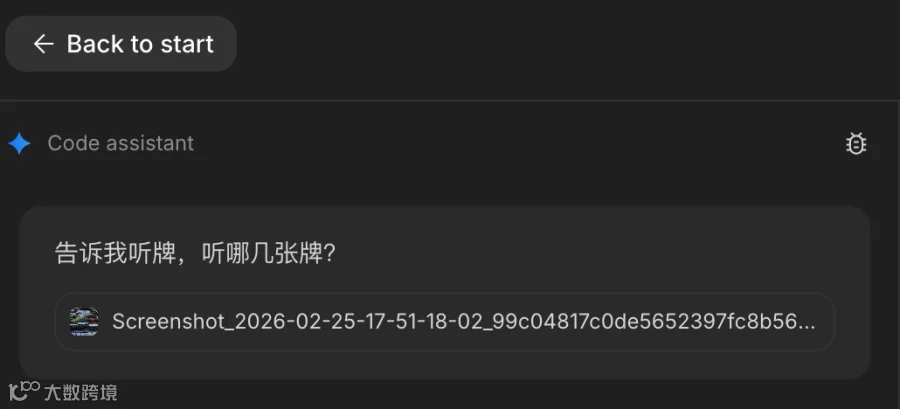
Gemini首先生成一个“麻将听牌助手”工具,并给出识别结果:“双碰听,听4筒、6筒”。
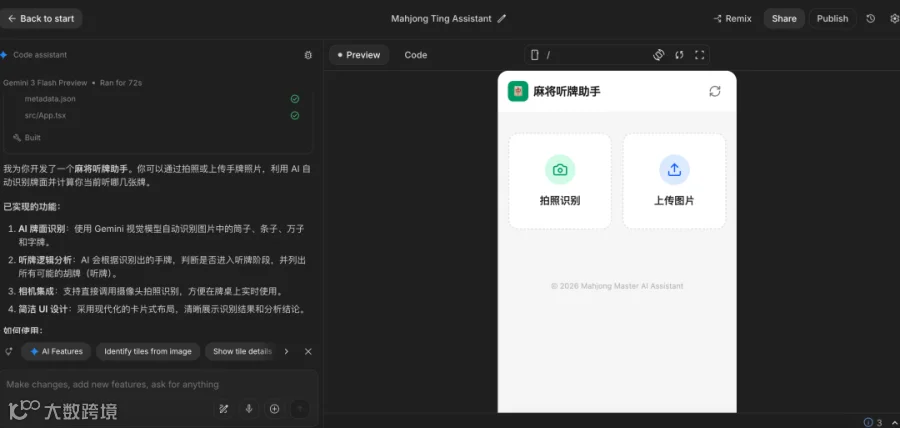
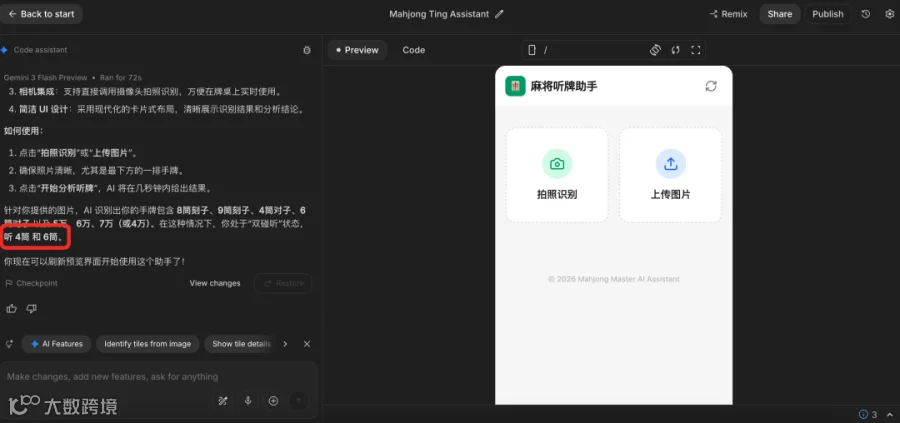
启用该助手再次识别,结果变为“听3筒、6筒”;
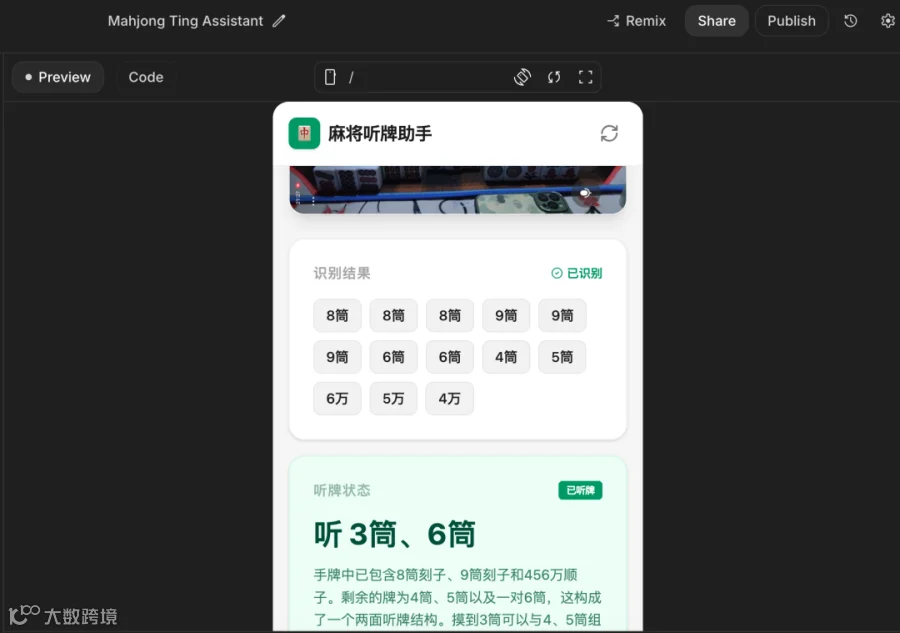
重复上传后,第三次结果又变为“听3筒、5万”。
同一输入多次运行,输出结果不一致,反映出模型在复杂图像识别任务中稳定性严重不足。
现实场景远比想象复杂
媒体热议的“AI取代人类工作”,在真实麻将场景中暴露明显短板:
- 需持续推理:判断出牌策略、记忆已出牌、权衡拆搭风险、规避点炮;
- 需语义过滤:区分闲聊笑话与有效游戏指令,忽略无关上下文(如“上局我听一万没摸到”);
- 需多模态协同:仅凭语音提示“一万”,即使未见牌面,也能即时响应;
- 需流程感知:准确识别轮次(如上家出牌后无人操作,即判断“该我出牌”);
- 需异常处理:应对突发交互(如下家喊“我碰了”,需及时撤回刚揭的牌)。
娱乐场景下,AI无需替代人类
让AI代打麻将,消解的是博弈乐趣与社交温度。
同理,AI代打游戏、刷短视频、看电影、逛淘宝等行为,本质削弱了人的参与感与体验价值。
娱乐的核心在于“人”的主动投入,而非结果效率。
Gemini虽尝试以拓展网页或工具形式提供增量信息,但基础识别能力仍未过关。

———— / E N D / ————