

《大数据教程:数据分析原理和方法》(林正炎,张朋,梁克维,庞天晓著. 北京:科学出版社,2020. 7)试图较全面地介绍大数据技术的基本原理和方法,包括以统计模型为主的各类数据模型以及它们的计算方法,同时还将介绍这些方法在一些领域(如人工智能)中的应用。
大数据正在开辟一个人类的新纪元。人们用它来描述和定义信息爆炸时代产生的海量数据,并命名与之相关的技术发展与创新。数据,已经渗透到当今每一个行业和业务职能领域,成为社会生产中新兴的重要生产资料,它的应用开发已经成为国家的重要战略,对于提升国家的整体竞争优势至关重要。一个国家拥有数据的规模、活性及解释运用的能力将成为提高综合国力的重要组成部分。对数据的占有和控制甚至将成为陆权、海权、空权之外的另一种国家核心资产。各国都高度重视大数据对引领产业腾飞和学科发展的重要意义。大数据不仅会给技术科学、自然科学乃至社会科学带来根本性的变革,也会给人们的生活方式和工作方式带来全新的变化,包括为我们看待世界提供了一种全新的方法,即决策行为将日益基于数据分析做出,而不是像过去更多凭借经验和直觉做出。伴随大数据技术的进步,互(物)联网已经深入人们生活的各个角落;区块链技术加快了数据市场的到来;人工智能正在以人们难以预料的速度突飞猛进,可能极大地颠覆我们的认知,并彻底改变社会生活的各个方面。
大数据如此重要,以至于其获取、储存、管理、处理、分析、共享乃至呈现,都成为当前重要的研究课题。无处不在的信息感知和采集终端为我们收集了海量的数据;数理统计、应用数学技术的发展,为我们提供了各种有效的统计和数学模型;而以云计算为代表的计算技术的不断进步,处理大规模复杂数据能力的日益增强,为我们提供了强大的数据处理能力,这都为我们构建起了一个与物质世界相平行的数字世界。
但是大数据领域的核心是数据的科学分析与有效处理。挖掘和分析大数据中的信息并得到有效的应用,离不开数学模型以及处理这些模型的方法,离不开科学计算、概率统计、优化处理的理论与技术。但是,大数据除了数据海量这一基本特征以外,还常有以下几个特征。
首要特征是数据的多样性、数据结构的特殊性(半结构化、非结构化,高维度,多母体)。数据类型繁多,包括网络日志、音频、视频、图片、地理位置信息等,而且对结果的呈现也常要求不同形式,如可视化。
另一个特征是有效数据的稀疏性,数据价值密度相对较低。随着物联网的广泛应用,信息感知无处不在,信息海量,但价值密度较低,如何通过强大的机器算法更迅速地完成数据的价值“提纯”,是大数据时代亟待解决的难题。
再一个特征是时效性,处理速度常需快速。
最后一个特征是数据的动态性、流动性。
因此大数据对于传统的数据分析的理论与方法、计算的理论与方法提出了极大的挑战。与此同时,基于大数据应用的广阔前景,各种行业、各类学科都迫切需要数据科学技术的创新和应用,因此人们必须创建一套能适应大数据处理需求的理论和方法。
数据分析是大数据技术的核心,因此本书着重介绍各种数据分析方法,包括回归分析、分类方法、聚类分析等统计方法。针对大数据常常以高维或超高维的形式出现有效数据呈现稀疏性的特征,书中给出了各类降维和数据压缩的统计或数学方法。我们还介绍了人工智能的核心技术之一的数据学习(训练)的若干重要方法,包括神经网络和深度学习等。

▲本图说明了LLE 背后的直观思想。局部线性嵌入(LLE)是通过低维邻域里高维数据的嵌入,达到准确地保留邻域高维数据的局部线性结构的一种降维方法。最左边的图显示从瑞士卷流形中采样的n = 2000 个输入,最右边的图显示由LLE 发现的二维表示。在中间的图中,输出具有与输入相同的维度,但是随机选择了l < n 个点,图中分别取l = 25,15 和10,取k = 20。中间图优化的目标不是减少维数,而是从一个小的子样本中对整个数据集进行局部线性重建。
计算机技术在数据处理的各个环节都起着至关重要的作用。为此,本书介绍了数据的预处理和存储,以及若干常用的计算方法,包括最大期望算法、贝叶斯算法、隐马尔可夫方法等。
实际中的“数据”除了以数字(包括向量、矩阵等)形式呈现外,还可能以其他各种方式出现,如文字、图像、声音等;对于分析得到的结果,除了以数字形式表达外,人们也常常希望能以其他方式给出,如表格、图像、声音等。书中介绍了处理这些“数据”的某些办法,如可视化方法等。
为了使读者深入了解书中介绍的各种数据模型及它们的应用,我们在给出模型和方法的同时,尽量列举一些例子;在第12 章,我们给出了三个实际案例,介绍如何应用书中提及的某些数据处理方法解决实际中遇到的问题。
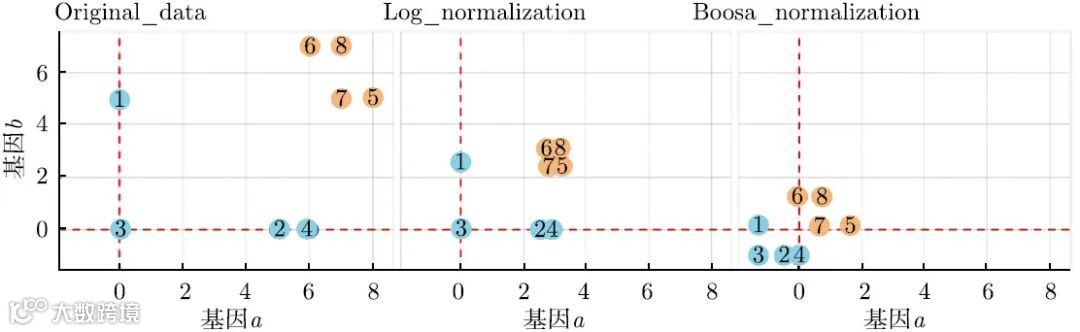
▲ 左:原始稀疏表达数据; 中:经log 变换得到的结果; 右:基于隐变量提升标准化方法得到的结果。图中每个子图都有8个点。点代表细胞,点的颜色代表细胞所属的类别,x 轴和y 轴分别代表各个细胞基因的表达量。从图中看到,这里所采用的标准化方法,将整体数据的重心移到了0附近,在消除数据的稀疏性的同时,扩大了0和非0基因表达量之间的差距。实际数据处理结果,也证实了BOSSA标准化方法在处理高维稀疏单细胞RNA-seq数据上的优越性。
大数据人才的缺失已经成为一个空前突出的问题。为此几乎所有的高等院校乃至中学都开设了大数据类的课程;数百所高校纷纷开设了大数据等相关专业。但是能适用于这类专业课程的合适教程十分稀缺。虽然国内外已经出版了大量大数据方面的书籍,但是多数都是泛泛介绍大数据的重要性、大数据的特点和在各个领域的应用,很少涉及大数据的方法和技术。目前也陆续出版了不少介绍大数据的方法和技术的书籍,但是它们大多数都侧重于某一个方向。如有的偏重于计算技术,譬如介绍机器学习的方法;有的则偏重于数理统计的理论和方法,譬如主要介绍多元分析、回归分析等;也有少量较为全面介绍大数据方法和技术的书籍,但似乎很难深入。本书试图为读者提供一个进入大数据领域的入门途径,使读者在学习书中的方法后能够较快地应用于解决实际课题。
本书可作为高等院校从事大数据及相关专业或对它们有兴趣的教师、研究生、本科生的参考书或教材;也可供从事大数据、人工智能研究、开发的科技人员阅读、参考。有些较为深入的内容,我们加了“*”号,初学者可暂时不读。
本书的撰写和出版得到了浙江大学数学科学学院的资助和国内外统计界、计算界很多同仁的指教。科学出版社胡庆家编审为本书的出版做了大量工作,本书还得到中央高校基本科研业务费专项资金等的资助,在此一并表达深切的谢意。

本文摘编自《大数据教程:数据分析原理和方法》(林正炎,张朋,梁克维,庞天晓著. 北京:科学出版社,2020. 7)一书“前言”,有删减修改,标题为编者所加。
ISBN 978-7-03-063298-2
责任编辑: 胡庆家
本书试图较全面地介绍大数据技术的基本原理和方法,包括以统计模型为主的各类数据模型以及它们的计算方法,同时还将介绍这些方法在一些领域(如人工智能)中的应用。
(本文编辑:刘四旦)

一起阅读科学!
科学出版社│微信ID:sciencepress-cspm
专业品质 学术价值
原创好读 科学品位

科学出版社 视频号
硬核有料 视听科学
传播科学,欢迎您点亮★星标,点赞、在看▼