
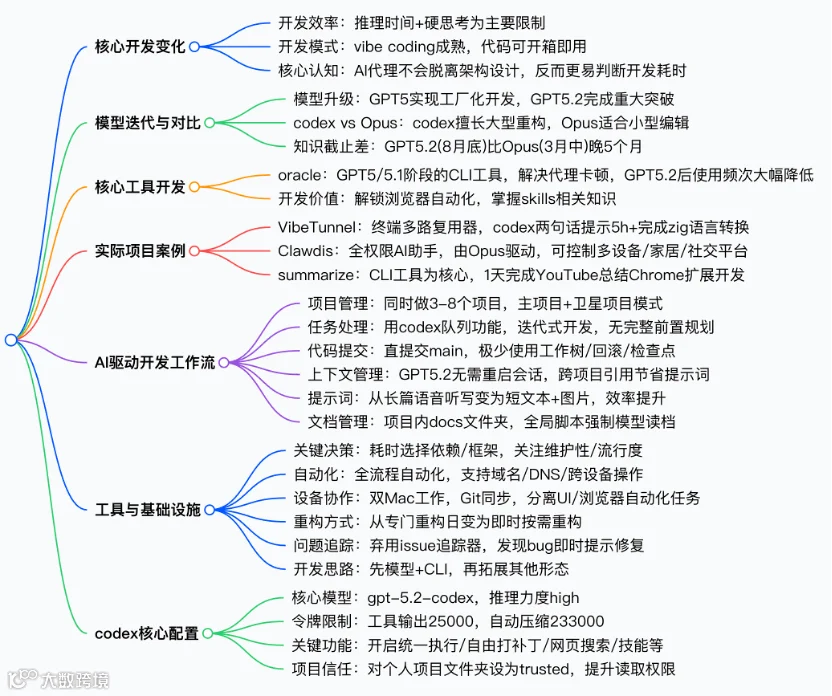
编者摘要:Peter Steinberger(彼得.斯泰因贝格) 于2025 年12 月28 日分享了AI智能体助力下推理速度主导的高效开发体验,GPT 5的推出实现了工厂化开发,GPT 5.2的升级带来了质的飞跃,核心开发工具codex在代码处理、上下文管理上显著优于Opus,其开发效率仅受推理时间和深度思考限制,还开发了oracleCLI 工具解决智能体卡顿问题,通过VibeTunnel、Clawdis 等项目验证了AI 模型的强大能力,并分享了以多项目并行、直提交main、短提示词为核心的AI 驱动开发工作流,同时介绍了工具基建选择逻辑和gpt-5.2-codex的核心配置,指出当下开发关键决策集中在语言/ 生态和依赖选择,且CLI 优先的开发思路能大幅提升效率。
自五月以来发生了什么变化
今年“氛围编码”取得了令人难以置信的进展。大约在5月份,我还惊讶于某些提示能够生成立即可用的代码,但现在这已经成为我的期望。我现在能够以一种似乎不真实的速度交付代码。从那时起我消耗了很多Token。是时候更新了。
有趣的是这些智能体是如何工作的。几周前有一个争论,认为人们需要编写代码才能感受到糟糕的架构,而使用智能体会造成一种脱节——对此我完全不同意。当你与智能体相处足够长的时间时,你会确切知道某件事情应该花多长时间,当代码生成器回来时未能一次性解决问题,我就开始产生怀疑。
我现在能够创建的软件量主要受到推理时间和深入思考的限制。老实说,大多数软件并不需要深入思考。大多数应用程序只是将数据从一种形式转移到另一种形式,也许把它存储在某处,然后以某种方式展示给用户。最简单的形式是文本,因此默认情况下,不论我想构建什么,它都是以命令行界面(CLI)开始的。智能体可以直接调用它并验证输出,从而闭合循环。
模型转变
真正开启像工厂一样构建的关键是GPT 5。在发布后的几周内我才意识到这一点- 而且codex也赶上了claude code具备的功能,并花了一些时间学习和理解它们之间的差异,但之后我开始越来越信任这个模型。这些天我不太看代码了。我观看直播,有时查看关键部分,但我必须坦诚- 大部分代码我不读。我确实知道各个组件在哪以及事物是如何构建的,整体系统是如何设计的,这通常就是所需的全部。
如今重要的决策是语言/生态系统和依赖关系。我常用的语言是TypeScript 用于网络开发,Go 用于命令行工具,如果需要使用macOS 相关内容或有用户界面,则使用Swift。几个月前我甚至没有考虑过Go,但最终我尝试了一下,发现它在编写智能体方面特别出色,简单的类型系统使得代码检查速度很快。
制作Mac 或iOS 应用的人士:你们不再需要太多Xcode。 我甚至不使用xcodeproj 文件。 现在Swift 的构建基础设施对于大多数事情来说已经足够了。codex 知道如何运行iOS 应用以及如何处理模拟器。 不需要特别的东西或MCP。
codex vs Opus#
我在这里写这篇帖子,正当codex 在进行一个庞大的、多小时的重构,并修复Opus 4.0 的旧问题。Twitter 上的人们常常问我Opus 和codex 之间有什么大区别,以及为什么这很重要,因为基准测试结果如此接近。在我看来,信任基准测试变得越来越困难——你需要尝试两者才能真正理解。无论OpenAI 在后期训练中做了什么,codex 在开始之前已经训练了LOTS 的代码。
有时候它会安静地读取文件10到15分钟,然后才开始写代码。一方面这让人烦恼,另一方面这也令人惊叹,因为这大大增加了修复正确内容的机会。相较之下,Opus则更为急切——对于较小的编辑十分有效,但对于更大功能或重构则不太理想,它往往不读取整个文件或遗漏部分内容,从而导致低效的结果或遗漏某些东西。我注意到,即使codex在可比任务上有时花费的时间是Opus的4倍,我通常还是更快,因为我不需要回头去修复修复,这在我还在使用Claude Code时感觉相当正常。
codex还让我学会了很多与Claude Code 相关的必要伪装。与其使用“计划模式”,我直接与模型开始对话,问一个问题,让它搜索、探索代码、共同制定计划,当我对看到的内容满意时,我就写“构建”或“写计划到docs/*.md 并构建这个”。计划模式感觉像是老一代模型在处理提示时不够好,而不得不剥夺它们编辑工具的必要黑客行为。我有一条被误解很深的推文仍在传播,显示大多数人并不明白计划模式并不是魔术。
Oracle(oracle 🧿— Whispering your tokens to the silicon sage)
备注:Oracle这是作者Peter的一个开源项目,意在降低Token消耗。
从GPT 5/5.1 到5.2 的升级是巨大的。我大约在一个月前构建了oracle 🧿——它是一个CLI,允许智能体运行GPT 5 Pro 并上传文件和提示,同时管理会话,以便可以稍后检索答案。我这么做是因为许多时候,当智能体卡住时,我会要求它将所有内容写入一个markdown 文件,然后自己进行查询,这感觉像是一种重复的浪费时间——也是一个闭环的机会。说明在我的全球AGENTS.MD 文件中,有时模型在卡住时会主动触发oracle。我每天多次使用这个功能。这是一次巨大的解锁。Pro 在大约50 个网站快速查阅信息后能非常专注地思考,在几乎每个案例中都能准确回答。有时候速度很快,花费10 分钟,但也有运行时间超过一个小时的情况。
现在GPT 5.2已经发布,我需要它的情况少了很多。我自己有时会使用Pro进行研究,但我对模型“询问神谕”的请求次数从每天多次减少到了每周几次。我对此并不生气——构建神谕的过程非常有趣,我学到了很多关于浏览器自动化、Windows的知识,并最终花时间研究了一下技能,之前我对此想法一直持否定态度。这确实表明了5.2在许多实际编码任务中的显著进步。它几乎可以一招解决我抛给它的任何问题。
另一个巨大的优势是知识截止日期。GPT 5.2 直到八月底,而Opus 停留在三月中旬——大约相差5 个月。这在你想使用最新的可用工具时是相当重要的。
一个具体的例子:VibeTunnel#
为了给你另一个关于模型进步的例子。我早期的一项重要项目是VibeTunnel。一个终端复用器,方便你随时随地编码。今年早些时候,我几乎将所有时间都投入到这个项目中,经过两个月,它的发展如此出色,以至于我在与朋友外出时发现自己在手机上编码……于是决定这是我应该停止的事情,更多是为了心理健康。那时我尝试将复用器的核心部分从TypeScript重写,而旧版模型不断让我失望。我尝试了Rust、Go……天啊,甚至是zig。当然,我本可以完成这个重构,但这需要大量手动工作,所以在我将其搁置之前,我从未完成它。上周我重新启动了这个项目,并给codex提供了一个两句话的提示,将整个转发系统转换为zig,它运行了超过5小时并经过多次压缩,最终一次性交付了一个可用的转换版本。
你问我为什么要把它除尘?我目前的重点是Clawdis,一个AI助手,它可以全面访问我所有电脑上的一切,包括消息、电子邮件、家庭自动化、摄像头、灯光、音乐,甚至可以控制我床上的温度。当然,它也有自己的声音,一个CLI用于推特和它自己的clawd.bot。
Clawd可以看到并控制我的屏幕,有时还会发表一些讽刺的评论,但我也想给他提供检查我的智能体的能力,而获取字符流显然比查看图像要高效得多……如果这样行得通,我们拭目以待!
我的工作流程#
我知道……你来这里是为了学习如何更快地构建,而我只是在为OpenAI撰写营销推广文。我希望Anthropic正在开发Opus 5,潮流再次转变。竞争是好的!与此同时,我喜欢Opus作为通用模型。我的AI智能体运行在GPT 5上时不会有一半的乐趣。Opus有一些特别之处,使得使用起来非常愉快。我将其用于大部分计算机自动化任务,当然它也驱动着Clawd🦞。
我从上次在十月份处理它以来,没有改变我的工作流程太多。
我通常同时处理多个项目。根据复杂程度,这个数量可以在3到8之间。上下文切换可能会很疲惫,我真的只有在家里、安静且专注的时候才能做到这一点。这需要处理很多心理模型。幸运的是,大多数软件都很无聊。创建一个命令行界面来检查你的食品配送不需要太多思考。通常我的重点是在一个大型项目和几个持续进行的小项目上。当你进行足够的智能体工程时,你会对什么事情会比较简单以及模型可能在何处遇到困难有一种感觉,因此我通常只需输入一个提示,Codex就会运行30分钟,我就能得到我需要的东西。有时候需要一点调整或创造力,但通常事情是直接明了的。
我大量使用codex 的排队功能——当我有了新的想法,我就把它加到流程中。我看到很多人正在尝试各种多智能体编排系统、电子邮件或自动任务管理——到目前为止,我还没看到太大的需求——通常我是瓶颈。我构建软件的方法是非常迭代的。我构建一些东西,玩一下,看看它的“感觉”,然后获得新的想法来refining 它。我很少能在脑海中有一个完整的画面。当然,我有一个大致的想法,但随着我探索问题领域,这个想法往往会发生巨大的变化。因此,那些将完整想法作为输入然后提供输出的系统对我来说并不好用。我需要去玩弄它、触摸它、感受它、看到它,这就是我发展它的方式。
我基本上从不回退或使用检查点。如果某样东西不是我喜欢的样子,我会要求模型改变它。Codex 有时会重置一个文件,但通常它只是回退或修改编辑,完全回退的情况非常少,而是我们只是向一个不同的方向发展。构建软件就像爬山。你不会直线向上走,而是绕着它走,转弯,有时你偏离了路径,需要倒退走一段路,这并不完美,但最终你会到达你需要去的地方。
我只是简单地提交到主干。有时,Codex 认为项目太混乱,自动创建一个工作树,然后再合并更改,但这种情况很少,我只在例外情况下提示它。我发现需要考虑项目中不同状态所带来的额外认知负担是不必要的,宁愿线性发展。较大的任务我会留在我分心时进行——例如在写这些的时候,我在这里对4 个项目进行重构,每个项目大约需要1-2 小时完成。当然,我可以在一个工作树中完成,但这只会导致很多合并冲突和次优的重构。注意:我通常是独自工作,如果你在一个更大的团队中,这种工作流程显然是行不通的。
我已经提到过我规划一个功能的方法。我总是交叉参考项目,尤其是如果我知道我已经在其他地方解决了某些问题,我会要求Codex查看../project-folder,通常这就足够让它根据上下文推断出该查看的位置。这对于节省提示非常有用。我可以直接写“查看../vibetunnel,并为Sparkle changelogs做同样的事情”,因为在那里已经解决了,并且有99%的把握它会正确地复制过来并适应新项目。这就是我搭建新项目的方法。
我见过许多系统供人们参考过往的会议。这是我从来不需要或使用的另一件事。我在每个项目的docs文件夹中维护子系统和功能的文档,并在我的全局AGENTS文件中使用一个脚本加上一些指令,强制模型读取某些主题的文档。这在项目越大时越有成效,因此我不会在每个地方使用它,但它在保持文档更新和为我的任务构建更好的上下文方面非常有帮助。
关于上下文。我以前非常勤奋地为新的任务重新开始一个会话。使用GPT 5.2后,这已经不再需要。即使上下文更加充实,性能也极其优秀,并且常常有助于提升速度,因为模型在加载了大量文件时工作得更快。显然,这仅在你将任务序列化或保持的更改间隔较远,以至于两个会话不会相互干扰时才有效。codex没有“此文件已更改”的系统事件,这与claude代码不同,因此你需要更加小心——另一方面,codex在上下文管理方面远远更好,我觉得在一次codex会话中完成的工作比claude要多5倍。这不仅仅是客观上更大的上下文大小,还有其他因素在起作用。我猜测codex在内部确实是为了节省token而进行很紧凑的思考,而Opus则非常啰嗦。有时,模型会搞砸,它的内部思考流会泄漏给用户,所以我见过这种情况好几次。实际上,codex的语言表达方式让我觉得奇怪而有趣。
提示。我过去习惯用语音输入写长而复杂的提示。使用Codex后,我的提示变得简短多了,我经常重新输入,并且很多时候我会添加图像,尤其是在用户界面(或带有CLI的文本副本)的迭代过程中。如果你向模型展示出哪里出错了,只需几句话就足以让它完成你想要的。是的,我就是那个把某个UI组件的剪裁图像拖过来,加上“修复边距”或“重新设计”的人,很多时候这要么解决了我的问题,要么让我走得相当远。我过去会参考Markdown文件,但有了我的docs:list脚本,这不再是必要的。
降价促销。很多时候我写“写文档到docs/*.md”,然后任由模型选择文件名。你为模型训练所设计的结构越明显,你的工作就会越轻松。毕竟,我并不是为了我自己方便而设计代码库,而是为了让智能体能够高效地在其中工作。与模型对抗通常是浪费时间和代币。
工具与基础设施#
什么仍然很难?选择合适的依赖和框架是我花费相当多时间的事情。这个库维护得好吗?同行依赖怎么样?它流行吗= 是否有足够的世界知识以便智能体能够轻松使用?同样,系统设计。我们会通过WebSocket 进行通信吗?HTML 呢?我应该把什么放在服务器上,什么放在客户端?数据如何流动,流向哪里?这些往往是一些较难向模型解释的事情,而研究和思考会有所回报。
由于我管理着许多项目,通常我会让一个智能体在我的项目文件夹中运行,当我发现一个新的模式时,我会要求它“找到我所有最近的Go 项目并在那里实施这个更改+ 更新变更日志”。我的每个项目在该文件中都有提升的补丁版本,当我重新访问时,一些改进已经在等着我去测试。
当然,我会自动化一切。注册域名和更改DNS是一项技能。写出好的前端也是一项技能。我的AGENTS文件中有关于我的tailscale网络的备注,所以我可以直接说“去我的Mac Studio更新xxx”。
关于多台Mac。我通常在两台Mac上工作。我的MacBook Pro连接大屏幕,而我通过Jump Desktop远程连接到另一台屏幕上的Mac Studio。有些项目在那里进行,有些在这里。有时我在每台机器上编辑同一项目的不同部分,并通过git进行同步。这比工作树简单,因为主干上的漂移容易调和。还有一个额外的好处是,任何需要UI或浏览器自动化的东西我可以转移到我的Studio,这样就不会被弹窗打扰。(是的,Playwright有无头模式,但有很多情况下那不会起作用)
另一个好处是任务可以在那儿持续运行,所以每当我旅行时,远程就成为我的主要工作站,即使我关闭我的Mac,任务也会继续进行。我曾经尝试过像codex或Cursor web这样的真实异步智能体,但我怀念可控性,最终工作都会变成拉取请求,这又增加了我设置的复杂性。我更喜欢终端的简洁。
我以前玩过斜杠命令,但总觉得它们没有太大用处。技能Skill替代了其中的一部分,对于其余的我一直在写“commit/push”,因为这花费的时间与/commit 相同,并且总是有效。
在过去,我经常专门花几天时间重构和清理项目,现在我更倾向于随时进行。当提示开始耗时过长或我看到代码流中有丑陋的东西时,我会立刻处理它。
我尝试过线性或其他问题跟踪工具,但没有一个能让我满意。重要的想法我会立刻处理,其他的我要么会记住,要么就不重要。当然,我为使用我的开源代码的人提供了公共缺陷跟踪器,但当我发现一个缺陷时,我会立即处理它——比写下来然后再切换回去要快得多。
无论你构建什么,首先从模型和CLI开始。我脑海中一直有一个总结YouTube视频的Chrome扩展的想法。上周,我开始着手开发summarize,一个将任何内容转换为Markdown的CLI,然后将其输入模型进行总结。首先,我做好了核心部分,一旦那部分运行良好,我在一天之内构建了整个扩展。我对它非常喜爱。它运行在本地,可以使用免费或付费模型。能在本地转录视频或音频。与本地守护进程通信,因此速度非常快。试试吧!
我常用的模型是gpt-5.2-codex high。再次强调,保持简单。除了运算速度更慢外,xhigh几乎没有什么好处,我不想花时间考虑不同的模式或“超思维”。所以几乎所有的东西都运行在high 上。GPT 5.2 和codex 足够接近,切换模型没有意义,所以我就使用这个。
我的配置#
这是我的~/.codex/config.toml:
model = "gpt-5.2-codex"
model_reasoning_effort = "高"
tool_output_token_limit = 25000
#留出空间以便在272–273k上下文窗口附近进行本地压缩。
#公式:273000 - (tool_output_token_limit + 15000)
# tool_output_token_limit=25000 ⇒ 273000 - (25000 + 15000) = 233000
model_auto_compact_token_limit = 233000
[features]
ghost_commit = false
unified_exec = true
apply_patch_freeform = true
web_search_request = true
skills = true
shell_snapshot = true
[projects."/Users/steipete/Projects"]
trust_level = "trusted"
这使得模型可以一次读取更多内容,默认设置有点小,可能限制它所看到的内容。它会默默失败,这很痛苦,不过他们最终会修复这个问题。此外,网页搜索仍然不是默认开启的?unified_exec 替换了tmux 和我旧的runner 脚本,rest 也很好。不要害怕压缩,自从OpenAI 切换到他们的新/compact 端点,这样的工作效果很好,任务可以在许多压缩中运行并完成。这样会使事情变慢,但通常就像是一次审查,模型在再次查看代码时会发现错误。
那就是现在的情况。我计划再写更多,并且脑子里有很多想法的积压,只是乐于创造。如果你想听听更多的闲聊和关于如何在这个新世界中构建的想法,欢迎在Twitter上关注我。